
Apple researchers unveiled Manzano, a unified multimodal model that simultaneously handles visual understanding and image generation while overcoming performance trade-offs plaguing current approaches.

Apple researchers have published a groundbreaking study detailing Manzano, a multimodal model architecture that bridges visual understanding and text-to-image generation within a single system. Unlike current approaches that force trade-offs between these capabilities, Manzano achieves competitive results in both domains through its hybrid tokenization approach.
The Core Challenge
 Current unified multimodal models face inherent limitations when combining image understanding and generation. As noted in the MANZANO research paper, systems typically prioritize one function at the expense of the other:
Current unified multimodal models face inherent limitations when combining image understanding and generation. As noted in the MANZANO research paper, systems typically prioritize one function at the expense of the other:
- Autoregressive generators (like DALL-E) use discrete image tokens ideal for pixel prediction but weak for semantic understanding
- Understanding-focused models employ continuous embeddings that lose low-level visual details crucial for generation
This stems from conflicting tokenization requirements: generation thrives on discrete tokens while understanding benefits from continuous representations. Most solutions either:
- Use dual tokenizers (VQ-VAE + semantic encoder), creating task conflict
- Employ parameter-inefficient MoT pathways
- Connect frozen LLMs to diffusion decoders, limiting mutual optimization
Manzano's Unified Architecture
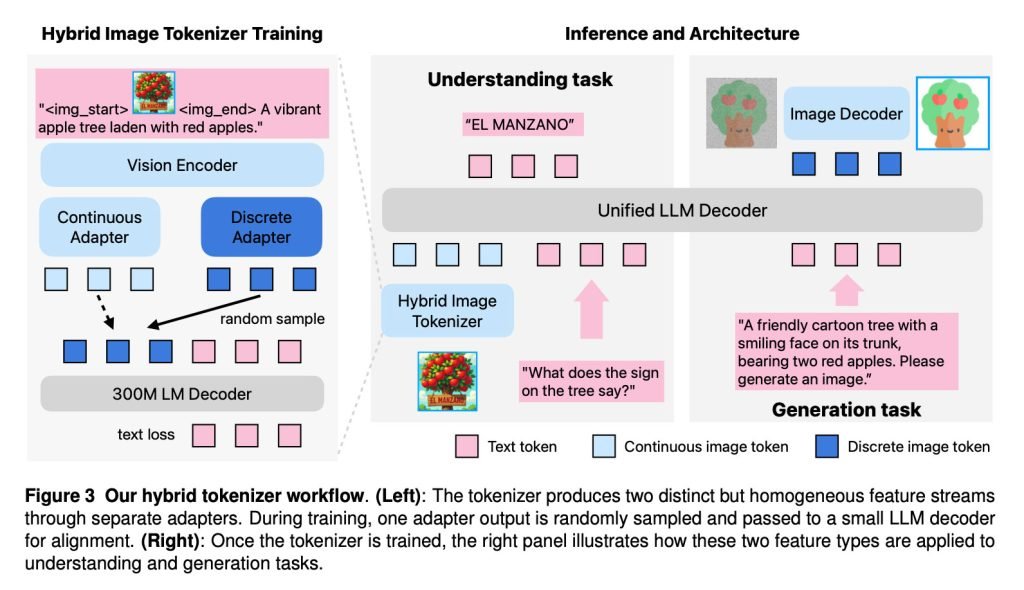 Manzano solves this through three integrated components:
Manzano solves this through three integrated components:
- Hybrid Vision Tokenizer: Produces both continuous embeddings (for understanding) and discrete tokens (for generation)
- LLM Decoder: Processes text tokens and continuous image embeddings, predicting next tokens from unified vocabulary
- Diffusion Decoder: Renders pixels from predicted image tokens using denoising diffusion
This architecture enables synergistic learning where the autoregressive component predicts semantic content which the diffusion decoder translates into pixels. Unlike decoupled approaches, both subsystems train jointly.
Performance Results
 Manzano demonstrates remarkable capabilities across benchmarks:
Manzano demonstrates remarkable capabilities across benchmarks:
- Handles counterintuitive prompts like "The bird is flying below the elephant" comparably to GPT-4o and Nano Banana
- Achieves superior performance in human evaluations of image-text alignment
- Outperforms competitors in compositional image generation tasks
The 30B-parameter version shows particularly strong scaling properties, with performance improving linearly with model size:
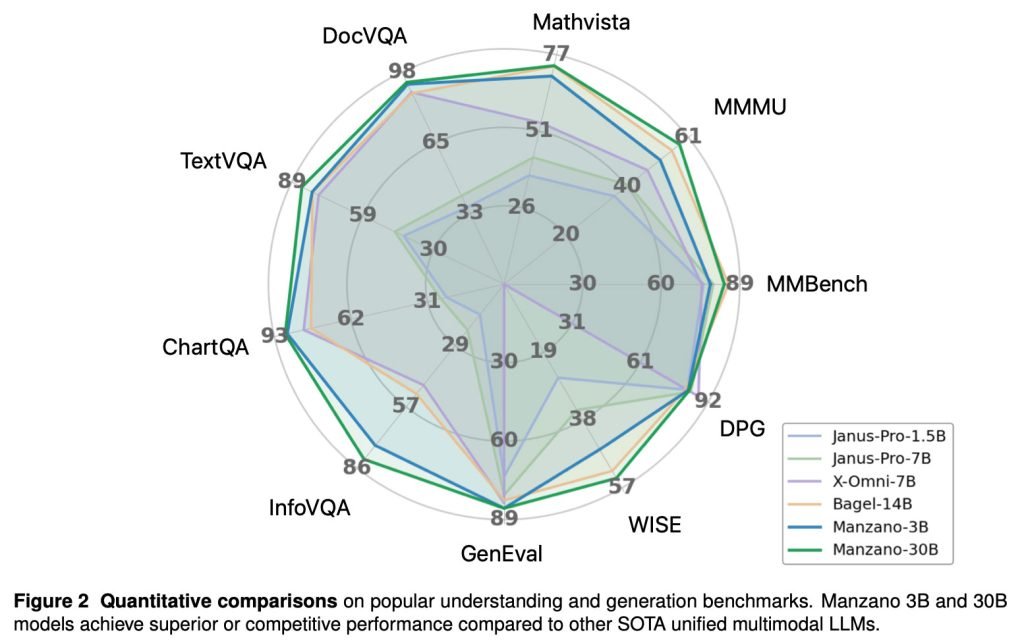
Additional testing revealed strengths in:
- Instruction-guided image editing
- Style transfer
- Inpainting/outpainting
- Depth estimation
Practical Implications
While not yet deployed in Apple products, Manzano represents significant progress toward more capable multimodal systems. Its parameter-efficient design (tested from 300M to 30B parameters) suits edge deployment. This research aligns with Apple's ongoing work in generative imaging, potentially enhancing future iterations of Image Playground.
For technical implementation details on the hybrid tokenizer training and diffusion decoder design, see the full research paper. Those interested in Apple's imaging research should also explore their recent work on UniGen.
Comments
Please log in or register to join the discussion