
Amazon is deploying over a gigawatt of new AI-dedicated data centers packed with its custom Trainium2 chips to anchor client Anthropic, betting that hardware-software co-design can overcome raw performance gaps with Nvidia. This partnership, central to AWS's cloud resurgence, leverages Trainium's memory bandwidth efficiency for Anthropic's reinforcement learning ambitions at unprecedented scale. The move signals a strategic pivot where hyperscalers and AI labs converge on custom silicon to escap

For over two years, AWS watched rivals Azure and Google Cloud gain ground in the AI infrastructure race, hampered by networking limitations and the absence of a marquee anchor client. That changed decisively when Amazon quadrupled its investment in Anthropic – now GenAI's stealth powerhouse, rocketing to $5B annualized revenue. Today, SemiAnalysis reveals exclusive insights into the engine behind this resurgence: multi-gigawatt data centers being rushed to completion, housing nearly a million of Amazon's custom Trainium2 accelerators exclusively for Anthropic's colossal model training needs.
The Anatomy of a Bet
Why would Anthropic, amid fierce competition, gamble on AWS's unproven silicon? The answer lies in memory bandwidth economics. While Nvidia's GB200 boasts 3.85x higher peak FLOPs, Trainium2 delivers superior memory bandwidth per dollar (TCO) – critical for Anthropic's reinforcement learning (RL)-heavy roadmap. As Dylan Patel notes, "Their roadmap is more memory-bandwidth-bound than FLOPs bound." Trainium2 provides 2,900GB/s memory bandwidth at a TCO reportedly 30-40% below comparable GPU clusters, making it ideal for memory-intensive post-training workloads.
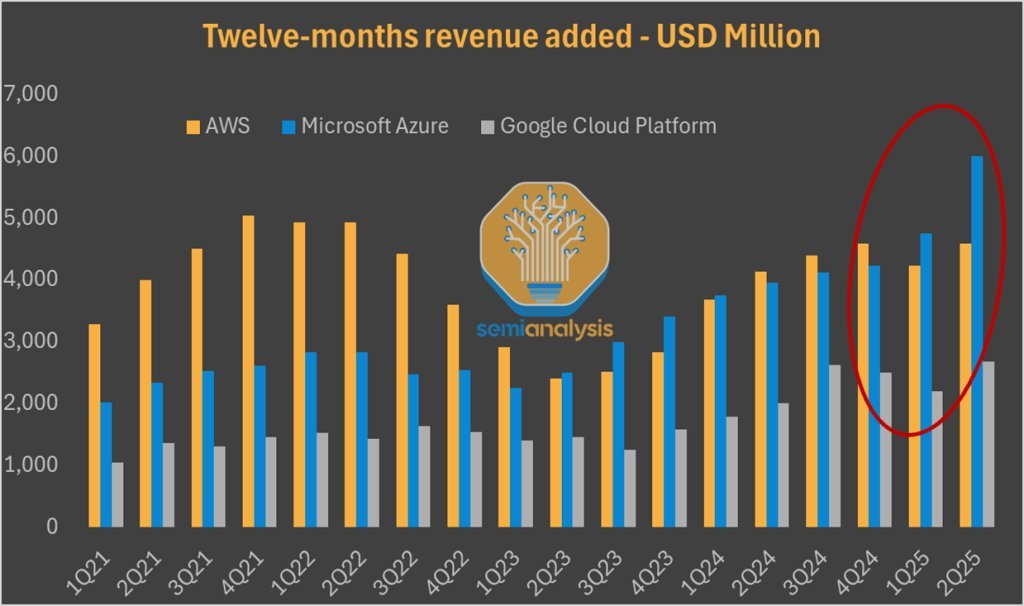 Source: SemiAnalysis Core Research, company filings – Cloud revenue growth trajectories.
Source: SemiAnalysis Core Research, company filings – Cloud revenue growth trajectories.
Systems-Level Innovation
Beyond chips, AWS is overhauling its infrastructure stack. The upcoming Teton PDS and Teton Max systems introduce NeuronLinkv3 – an all-to-all scale-up network mimicking Nvidia's NVLink but optimized for Anthropic's workflow. Four switch trays sit centrally in the rack with compute trays above and below, minimizing latency for parameter exchanges. This isn't off-the-shelf hardware; Anthropic engineers are deeply embedded in Annapurna Labs' design process, effectively using Amazon as a custom silicon partner. This co-design mirrors Google DeepMind's synergy with TPU teams – a rare advantage outside vertically integrated giants.
Scaling the Unscalable
Satellite imagery analyzed by SemiAnalysis shows three AWS campuses nearing completion, injecting over 1.3GW of AI-dedicated capacity. Construction velocity is unprecedented: "AWS is building datacenters faster than it ever has in its entire history," with another gigawatt-scale site already breaking ground. While yield issues delayed initial deployments, volumes are surging. Trainium2 production is scaling rapidly, positioning AWS to capture Anthropic's next training cycle – models requiring exaflops of sustained compute.
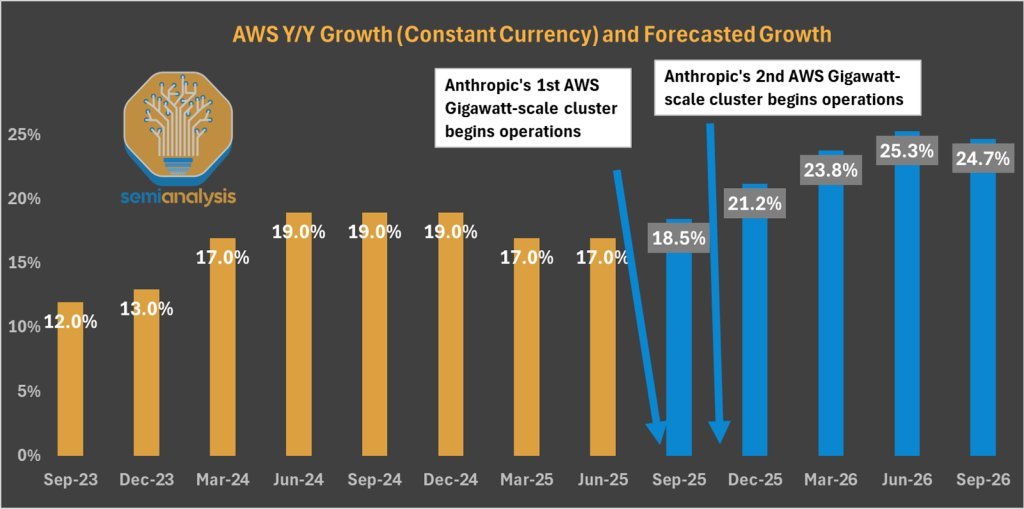 Source: SemiAnalysis Datacenter Industry Model – Tracking AI-dedicated capacity buildout.
Source: SemiAnalysis Datacenter Industry Model – Tracking AI-dedicated capacity buildout.
The Broader Battlefield
This isn't just about winning Anthropic's business. AWS is using the partnership to refine Trainium for its own services (Bedrock, Alexa) and future external customers. Yet challenges persist:
- Inference Gap: Google's TPUv5 still dominates Anthropic's inference workloads due to superior latency/throughput.
- Software Maturity: AWS's Elastic Fabric Adapter (EFA) networking still lags InfiniBand/RoCEv2 on performance and operational smoothness.
- Hybrid Loyalty: Anthropic's $13B funding round ensures it continues diversifying across AWS, Google, and possibly Azure.
The Trainium bet exemplifies a seismic shift: cloud differentiation now hinges on silicon. As one AI lab architect observed, "When training costs exceed $1B per model, TCO isn't an optimization – it's existential." AWS’s wager may soon determine whether cloud providers can escape the GPU scarcity trap by controlling their silicon destiny.
Comments
Please log in or register to join the discussion