Microsoft's Azure SQL now offers native JSON binary storage, reducing storage needs by 82% and improving query performance by 2.5-4x compared to traditional text-based JSON storage in enterprise benchmark tests.
Microsoft has fundamentally changed how Azure SQL handles JSON data with its new native binary storage format, shifting from text-based (nvarchar/varchar) storage to an optimized binary representation. This architectural change addresses core performance limitations in modern application workloads that blend relational and semi-structured data.
The Performance Transformation
When storing JSON as text, every query requires full document parsing - a resource-intensive operation that scales poorly with document size and query volume. The native JSON type eliminates this overhead by storing pre-parsed documents in a compressed binary format with three key advantages:
- Instant Read Optimization: JSON elements are indexable without parsing
- Efficient Partial Updates: Modify specific values without rewriting entire documents
- Storage Compression: Binary encoding reduces footprint by 4-7x based on structure
Comparative Benchmark Results
In controlled tests using real-world schemas on General Purpose Gen5 instances:
| Metric | Text JSON (nvarchar) | Native JSON | Improvement |
|---|---|---|---|
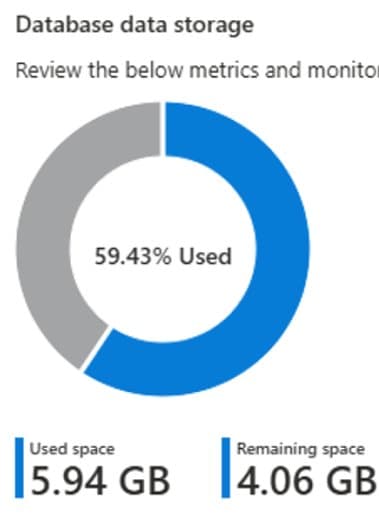
| Storage Footprint | 5.94GB | 1.06GB | 82% reduction |
| Avg Query Duration | 1360ms | 340ms | 4x faster |
| Throughput (records/s) | 60 | 240 | 4x increase |
| Logical Reads | 168,507 | 33,880 | 80% less IO |
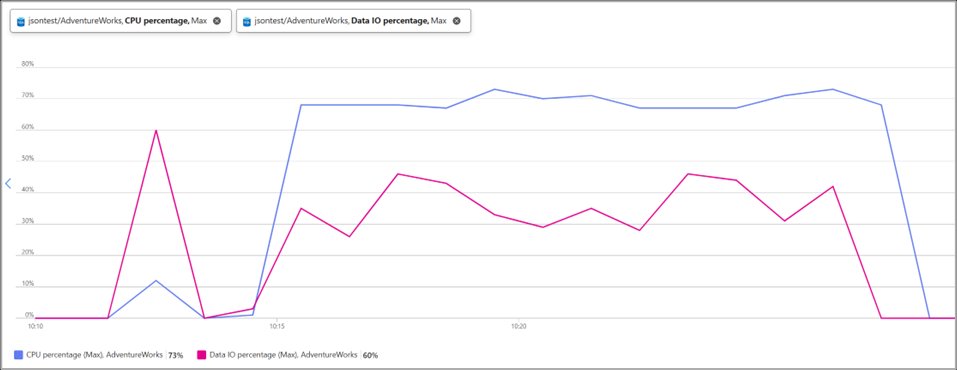 Performance comparison across identical workloads (Source: Microsoft Performance Lab)
Performance comparison across identical workloads (Source: Microsoft Performance Lab)
Business Impact Analysis
- Cost Efficiency: Reduced storage needs directly lower Azure storage costs while decreased CPU/IO consumption allows smaller instance sizes
- Migration Simplicity: Existing JSON functions remain compatible, enabling low-risk adoption via
CAST(original_column AS JSON) - Hybrid Workload Optimization: Combines relational integrity with document flexibility - ideal for:
- Microservices storing event payloads
- E-commerce product configurations
- IoT device telemetry ingestion
Strategic Considerations
While AWS Aurora and Google Cloud Spanner offer JSON support, Azure SQL's implementation uniquely combines:
- Transactional Consistency: ACID compliance for JSON modifications
- Indexing Flexibility: Combine relational indexes with JSON path expressions
- Gradual Adoption: Per-column migration path without schema overhaul
 Storage reduction after migration to native JSON format (Source: Microsoft Performance Lab)
Storage reduction after migration to native JSON format (Source: Microsoft Performance Lab)
Implementation Guidance
For teams evaluating adoption:
- Profile existing JSON query patterns using Query Store
- Test migration scripts in staging using
CASToperations - Monitor
sys.dm_db_index_physical_statsfor storage changes post-conversion
This evolution positions Azure SQL as a competitive option for polyglot persistence scenarios, particularly for enterprises already invested in Microsoft's data ecosystem. The native JSON type bridges the gap between NoSQL flexibility and relational reliability - a strategic advantage for cloud architects designing mixed-workload systems.
For migration planning, reference Microsoft's Azure SQL JSON documentation and database migration guide.
Comments
Please log in or register to join the discussion