
Parseable's stress test reveals how its S3-native architecture handles 100TB of daily telemetry data at 1/5th the cost of traditional solutions. With optimized Rust code and intelligent caching, the platform maintained millisecond query speeds while slashing cross-AZ data transfer taxes inherent in Elasticsearch deployments.

The 100TB-Per-Day Challenge
Modern enterprises generate staggering telemetry volumes—logs, metrics, and traces exceeding 100TB daily. At this scale, physics and economics collide: What infrastructure can sustain such firehoses? How do you avoid bankrupting the company on cloud bills? Parseable tackled these questions head-on with a real-world stress test, revealing surprising efficiencies in cloud-native observability.
Breaking Conventional Architectures
Traditional solutions like Elasticsearch rely on cross-AZ data replication for reliability, triggering punishing AWS data transfer fees ($0.01/GB each way). At 100TB/day, that's $10,000 daily just for ingestion—before query costs. Parseable's diskless architecture bypasses this by using S3 as its primary storage layer. Nodes run in the same AZ as applications, eliminating cross-AZ transfers while maintaining durability via object storage's built-in replication.
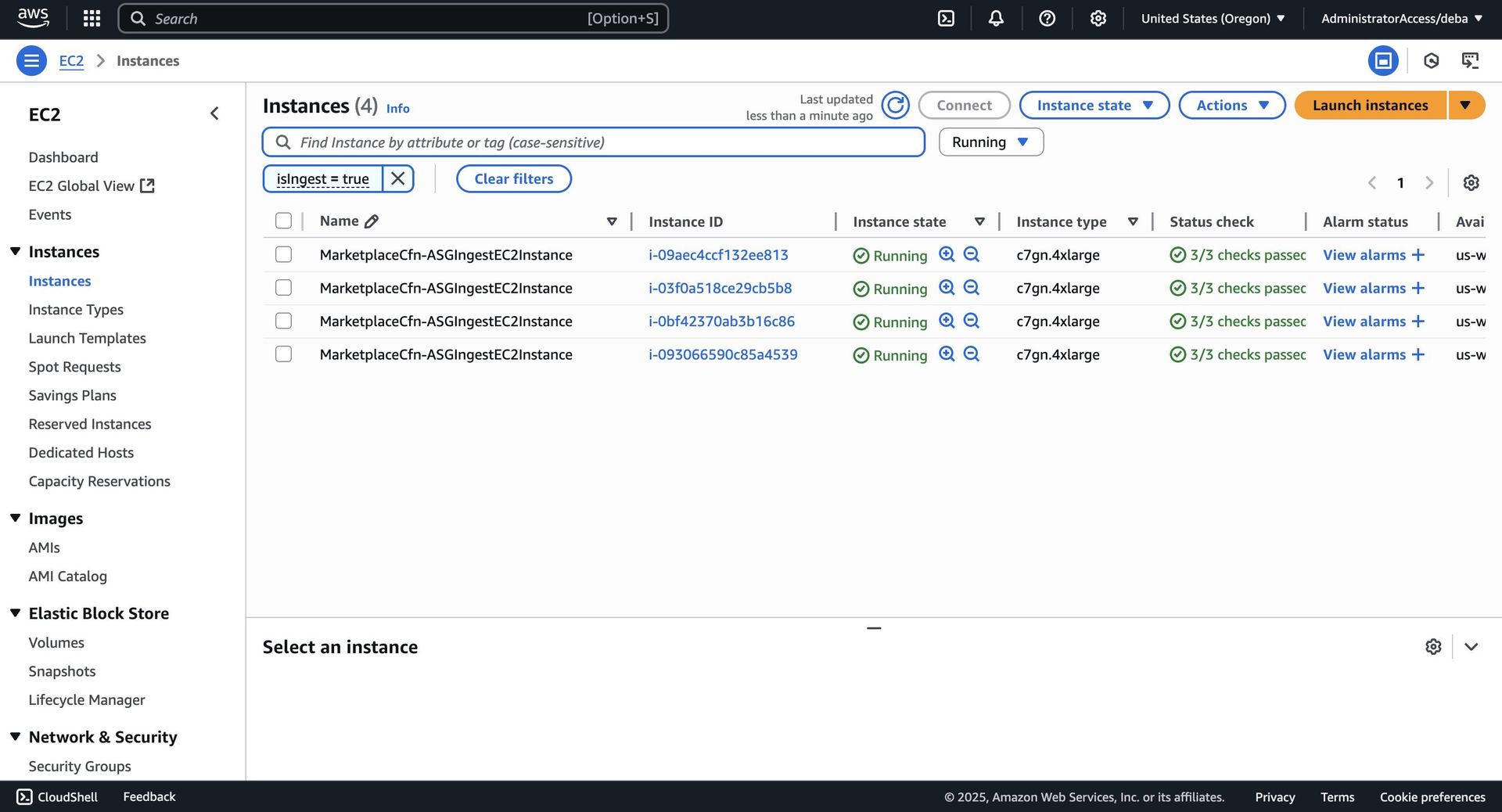
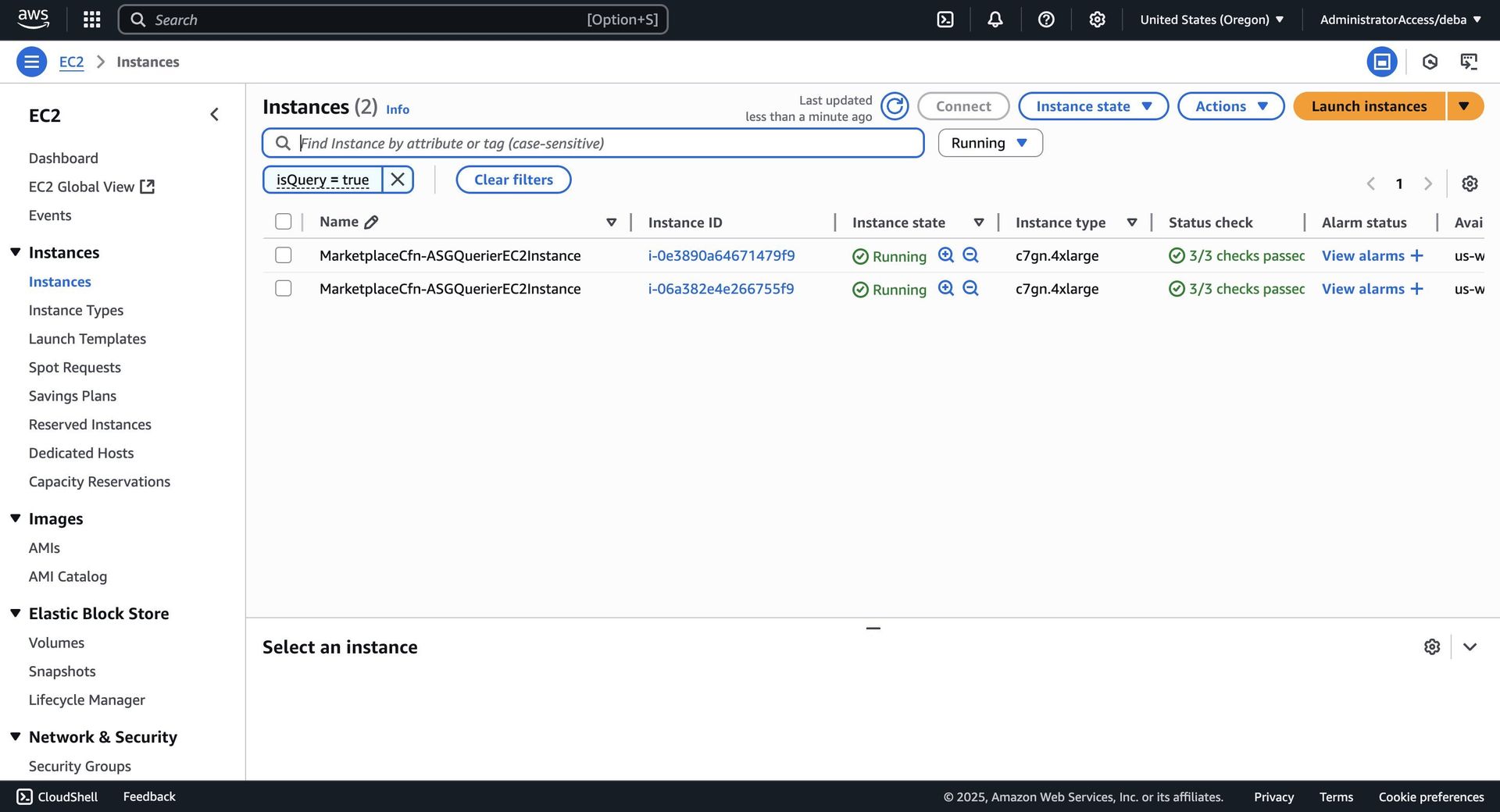
Anatomy of a 100TB Stress Test
Parseable deployed a battle-ready cluster on AWS:
- Ingestion: 4× c7gn.4xlarge nodes (ARM-based, high networking throughput)
- Load Generation: 12× matching instances running k6 scripts
- Query/Control: Dedicated querier and "Prism" coordinator nodes
Key design principles:
1. Ephemeral local disks (24GB) for buffering ~2 hours of peak data
2. Rapid offloading to S3 using columnar storage formats
3. Rust-based engine for zero-copy parsing and compression
Performance Under Fire
During the hour-long trial, Parseable ingested 2TB across 4 nodes (500GB/node/hour) with near-linear scaling. Despite the torrent, query latency remained firmly in the millisecond range—even during peak load. 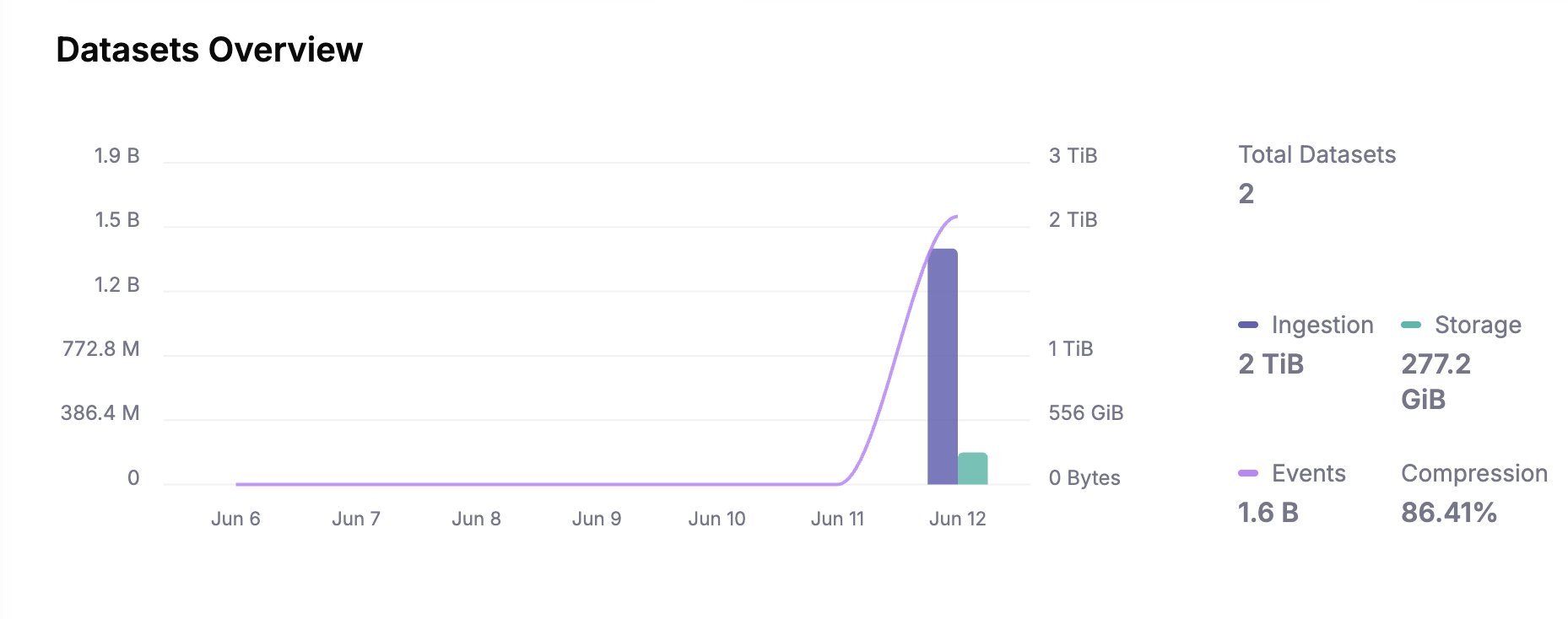
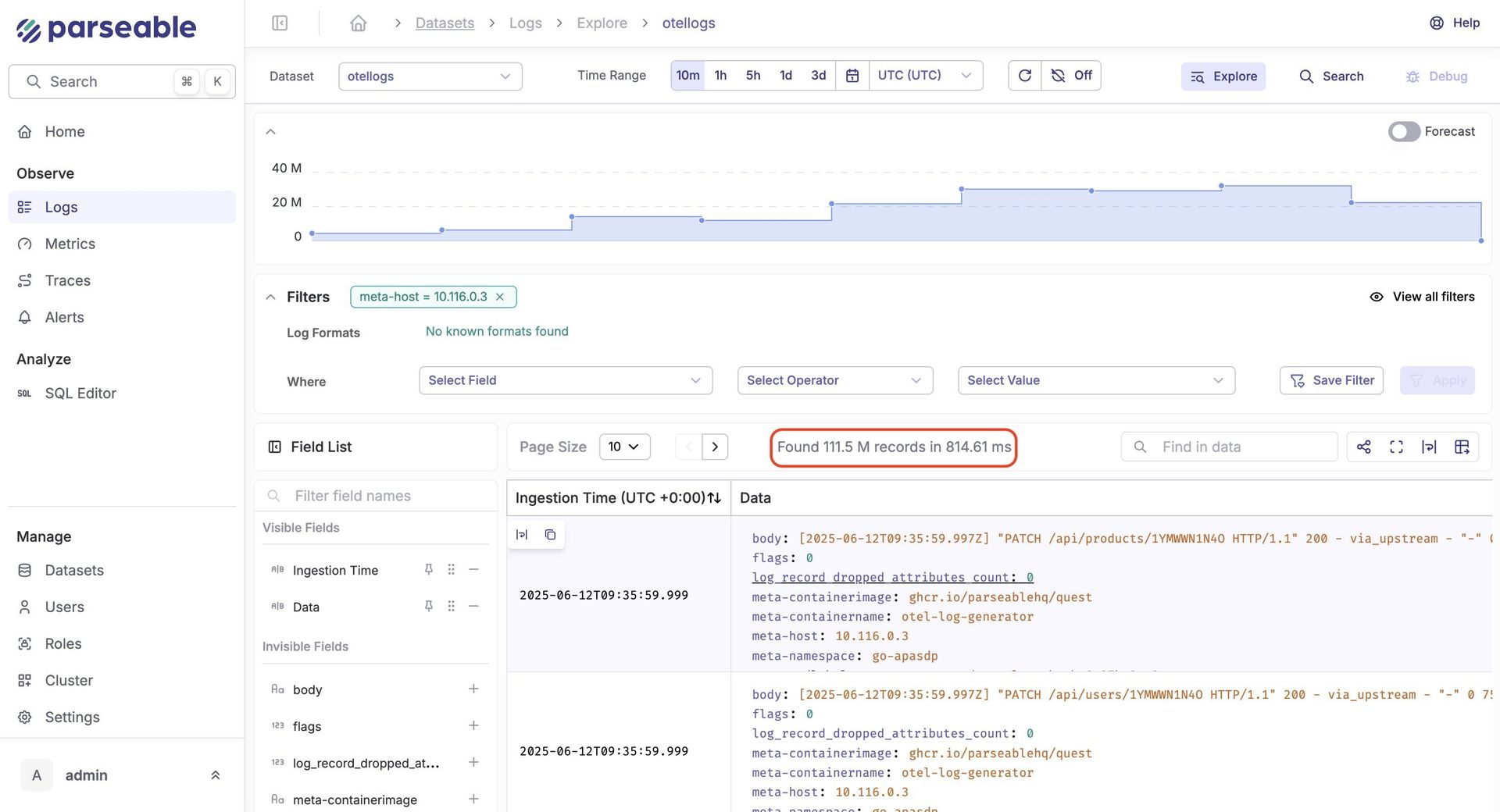
"Our S3-first approach with intelligent caching proves you don't need petabyte-scale local SSDs for high-performance observability," noted the engineering team. "The real magic happens in the compression layer and metadata indexing."
The Cost Calculus
Extrapolating to 100TB/day revealed compelling economics:
| Resource | Qty | Monthly Cost |
|---|---|---|
| EC2 (11× c7gn.4xlarge) | 11 | $4,910 |
| S3 Storage (300TB)* | - | $6,900 |
| Total | $11,810 |
*After 10:1 compression
Compare this to estimated costs:
- Elasticsearch/OpenSearch: ~$100,000/month
- Grafana Loki: ~$55,000/month
Parseable's 88% savings stem from avoiding cross-AZ taxes, leveraging S3's economies of scale, and aggressive compression using Apache Arrow and Zstandard.
The New Observability Physics
This test demonstrates that cloud-native architectures rewrite the rules of scalability. By treating object storage as the "source of truth" and local disks as transient buffers, Parseable achieves:
- Linear scaling: Add nodes to match ingestion spikes
- Predictable costs: No hidden cross-AZ transfer fees
- Zero fragmentation: Unified storage for logs/metrics/traces
As enterprises drown in telemetry data, solutions that master both physics (throughput/latency) and economics (TCO) will define the next era of observability—proving that sometimes, the most powerful architecture is the one that strategically does less.
Source: Parseable Blog
Comments
Please log in or register to join the discussion