
The trycua/cua project provides a comprehensive, open-source platform for developing, benchmarking, and deploying AI agents capable of interacting with full desktop environments across macOS, Linux, and Windows, featuring isolated sandboxes, specialized SDKs, and standardized evaluation frameworks.
The emergence of AI agents that can autonomously navigate and manipulate computer interfaces represents a significant frontier in artificial intelligence, moving beyond text-based interactions to direct manipulation of graphical user interfaces. The open-source project Cua from trycua addresses this challenge by providing a unified infrastructure for building, benchmarking, and deploying such computer-use agents. Unlike narrow tools designed for specific tasks, Cua offers a holistic ecosystem that spans the entire agent development lifecycle—from creating isolated execution environments to training models and evaluating their performance on standardized tasks.
At its core, Cua is built around three primary components that work in concert: the main Cua framework for agent development, Cua-Bench for benchmarking and reinforcement learning environments, and Lume for high-performance virtualization on Apple Silicon. The architecture is designed to be both modular and extensible, allowing researchers and developers to choose the components that fit their specific needs while maintaining compatibility across the entire stack. This approach acknowledges that building effective computer-use agents requires addressing multiple challenges simultaneously: reliable environment isolation, realistic interaction capabilities, standardized evaluation metrics, and efficient training infrastructure.
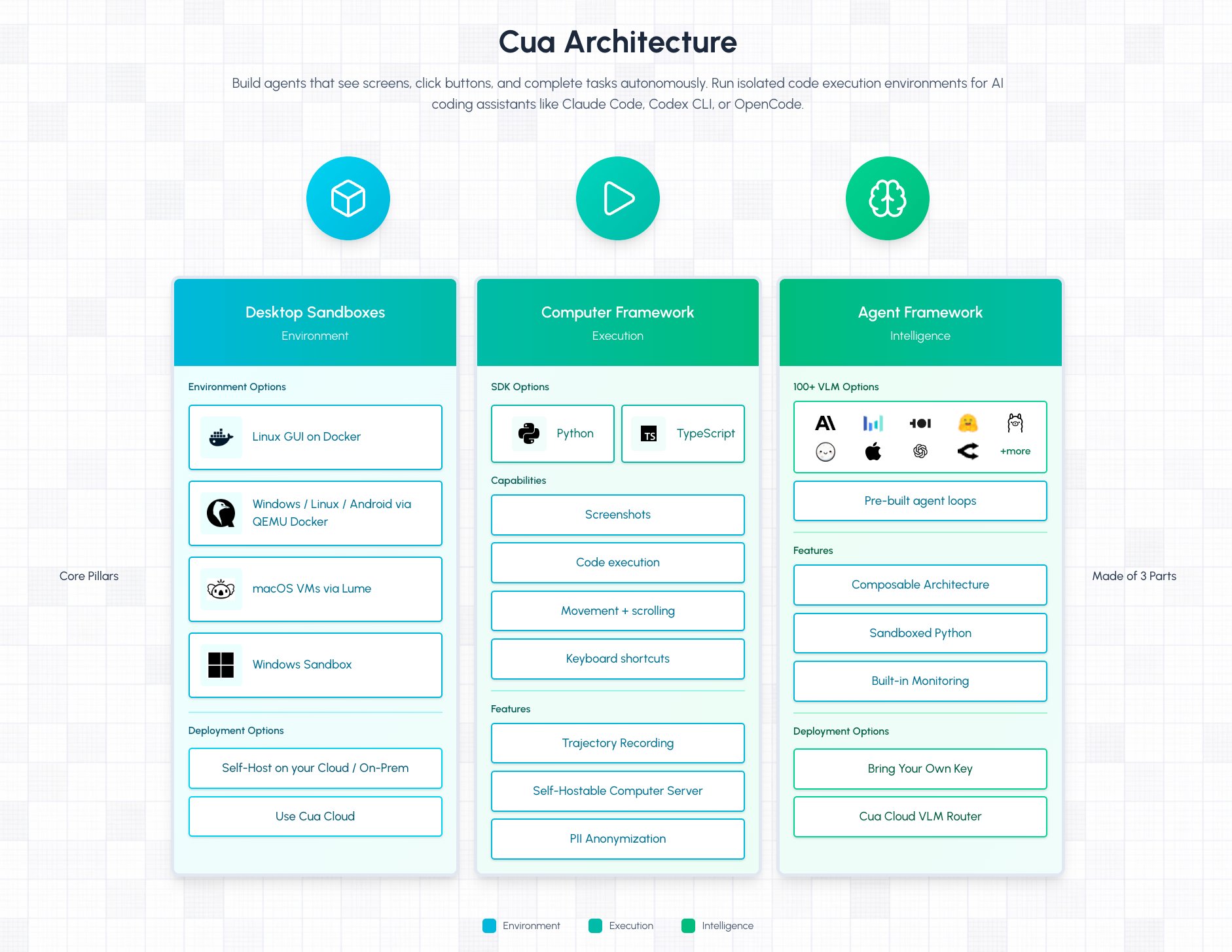
The Cua framework itself provides the foundational SDK for controlling desktop environments through a clean Python interface. The example code demonstrates the simplicity of the API: a Computer object represents the target desktop environment, while a ComputerAgent orchestrates the interaction using a specified model. The agent can be instructed to perform complex multi-step tasks, such as opening a browser and performing a search, with the system handling the underlying UI interactions. This abstraction is crucial because it allows developers to focus on agent behavior rather than the intricacies of screen parsing, input simulation, or cross-platform compatibility. The framework supports multiple providers, including cloud-based and local sandboxes, enabling both development and production deployment scenarios.
The sandboxing capabilities are particularly important for safety and reproducibility. Cua supports multiple isolation technologies: Docker containers for Linux environments, QEMU for broader virtualization needs, and Apple's Virtualization Framework for macOS. This multi-provider approach ensures that agents can be tested in environments that closely match their intended deployment targets. For AI coding assistants like Claude Code or Codex CLI, these isolated sandboxes provide secure code execution environments that prevent malicious code from affecting host systems while maintaining the necessary permissions for legitimate development tasks.

Cua-Bench addresses one of the most critical challenges in computer-use agent research: standardized evaluation. Without consistent benchmarks, comparing different agent architectures or training approaches becomes nearly impossible. Cua-Bench provides pre-configured evaluation environments for established benchmarks like OSWorld, ScreenSpot, and Windows Arena, along with support for custom task definitions. The system includes tools for creating base images, running parallel evaluations, and exporting interaction trajectories for downstream analysis or reinforcement learning. This infrastructure enables researchers to measure agent performance across multiple dimensions: task completion rates, efficiency, robustness to interface variations, and generalization capabilities.
The reinforcement learning integration is particularly sophisticated. By exporting complete interaction trajectories—including screen states, actions taken, and outcomes—Cua-Bench creates the data necessary for training agents through methods like imitation learning or direct policy optimization. This closed-loop system, where agents can be evaluated, trained, and re-evaluated, is essential for developing agents that improve over time rather than relying solely on pre-trained models. The ability to run benchmarks with configurable parallelism also makes practical experimentation feasible, as researchers can iterate quickly on different model architectures or training strategies.

Lume, the virtualization component, deserves special attention for its performance characteristics. By leveraging Apple's Virtualization Framework on Apple Silicon, Lume achieves near-native execution speeds for macOS and Linux virtual machines. This performance is critical for computer-use agents, which need to process screen content and execute actions in real-time. Traditional virtualization approaches often introduce latency that can make agent-environment interactions feel sluggish or unreliable. Lume's architecture, as shown in the documentation, optimizes the entire stack from the hypervisor level through to the guest OS, enabling smooth operation of GUI applications within the virtual environment. This makes it practical to run complex desktop applications as part of agent training or evaluation scenarios.
The project's modular package structure reflects its comprehensive scope. The cua-agent package provides the high-level agent framework, cua-computer offers the low-level SDK for UI control, and cua-computer-server handles the driver layer for actual interaction with desktop environments. This separation of concerns allows developers to use only the components they need—for instance, using just the computer SDK for a custom automation script, or employing the full agent framework for a research project. The inclusion of lumier as a Docker-compatible interface for Lume VMs further simplifies integration with existing container-based workflows.
From a practical standpoint, Cua's approach to computer-use agents addresses several fundamental limitations of current AI systems. Most language models, despite their impressive capabilities, operate in isolated text environments without direct access to graphical interfaces. This creates a disconnect between the agent's understanding and the actual user experience. By providing tools that can see screens, interpret visual information, and execute precise UI actions, Cua bridges this gap. The system's support for multiple operating systems also acknowledges that real-world deployment requires cross-platform compatibility—agents trained on Linux interfaces may need to adapt to macOS or Windows environments.
The project's commitment to open-source development, evidenced by its MIT license and contribution guidelines, positions it as a community-driven alternative to proprietary solutions. This openness is particularly valuable for research, where reproducibility and transparency are essential. The inclusion of third-party components with their respective licenses (Kasm under MIT, OmniParser under CC-BY-4.0, and optional ultralytics under AGPL-3.0) demonstrates careful attention to licensing compliance, which is crucial for commercial adoption.
Looking at the broader implications, infrastructure like Cua could accelerate progress in several AI research directions. For reinforcement learning, the ability to generate large-scale interaction data from real desktop environments provides rich training signals beyond traditional text corpora. For human-computer interaction research, it enables systematic study of how agents learn to use interfaces designed for humans. For software engineering, it opens possibilities for agents that can assist with complex development tasks that require navigating multiple applications and tools.
The architecture also suggests interesting possibilities for distributed agent systems. Since the components are designed to be self-hostable, organizations could deploy fleets of agents across different environments, each specialized for particular tasks or domains. The isolated sandboxing ensures that these agents can operate safely without risking system integrity, while the benchmarking tools provide the means to maintain quality standards across deployments.
As computer-use agents become more capable, the infrastructure supporting their development will only grow in importance. Projects like Cua provide the foundational tools needed to explore this frontier systematically, offering both the practical components for building agents and the evaluation frameworks for measuring progress. The integration of virtualization, benchmarking, and agent development into a single cohesive platform represents a thoughtful approach to a complex problem, one that acknowledges the multifaceted nature of creating AI that can truly understand and interact with the digital world as humans do.
For those interested in exploring computer-use agents, Cua offers a comprehensive starting point. The project's documentation provides detailed guides for getting started with each component, and the active community on Discord offers support for both newcomers and experienced developers. As the field continues to evolve, infrastructure projects like this will play a crucial role in shaping how AI agents interact with our digital environments.
Comments
Please log in or register to join the discussion