IBM's Docling Serve hits a major milestone with its stable v1 API release, offering developers a robust toolkit for AI-driven document processing. With new container deployments and an interactive UI, this open-source solution simplifies converting complex documents while supporting diverse hardware configurations.
IBM has unveiled the first stable release of Docling Serve, an open-source toolkit designed to revolutionize AI-powered document processing. Now featuring a production-ready v1 API, this Python-based solution enables developers to convert complex documents—including PDFs, images, and web content—into structured data using cutting-edge AI models. The release marks a significant evolution from research prototype to deployable infrastructure, backed by IBM's commitment to open-source AI innovation.
One-Click Deployment, Flexible Architectures
Getting started is streamlined for diverse environments. Developers can install via pip with GPU acceleration support:
pip install "docling-serve[ui]"
docling-serve run --enable-ui
Or deploy using optimized container images for specific hardware needs:
podman run -p 5001:5001 -e DOCLING_SERVE_ENABLE_UI=1 \
quay.io/docling-project/docling-serve
 The built-in FastAPI documentation interface provides interactive endpoint testing
The built-in FastAPI documentation interface provides interactive endpoint testing
Hardware-Optimized Containers
Docling offers specialized Docker images catering to different compute requirements:
| Image Variant | Description | GPU Support | Size |
|---|---|---|---|
| docling-serve | Base PyPI installation | AMD64/ARM64 | 4.4-8.7GB |
| docling-serve-cpu | CPU-only optimization | None | 4.4GB |
| docling-serve-cu126/128 | NVIDIA CUDA 12.6/12.8 builds | NVIDIA GPUs | 10-11.4GB |
| docling-serve-rocm | AMD ROCm 6.3 (build manually) | AMD GPUs | N/A |
These pre-configured images eliminate dependency headaches while maximizing hardware utilization—critical for compute-intensive document processing tasks.
Interactive Playground & API Capabilities
The bundled UI playground (/ui endpoint) allows non-technical users to test document conversions visually. For developers, the REST API enables pipeline integrations:
curl -X 'POST' 'http://localhost:5001/v1/convert/source' \
-H 'Content-Type: application/json' \
-d '{"sources": [{"kind": "http", "url": "https://arxiv.org/pdf/2501.17887"}]}'
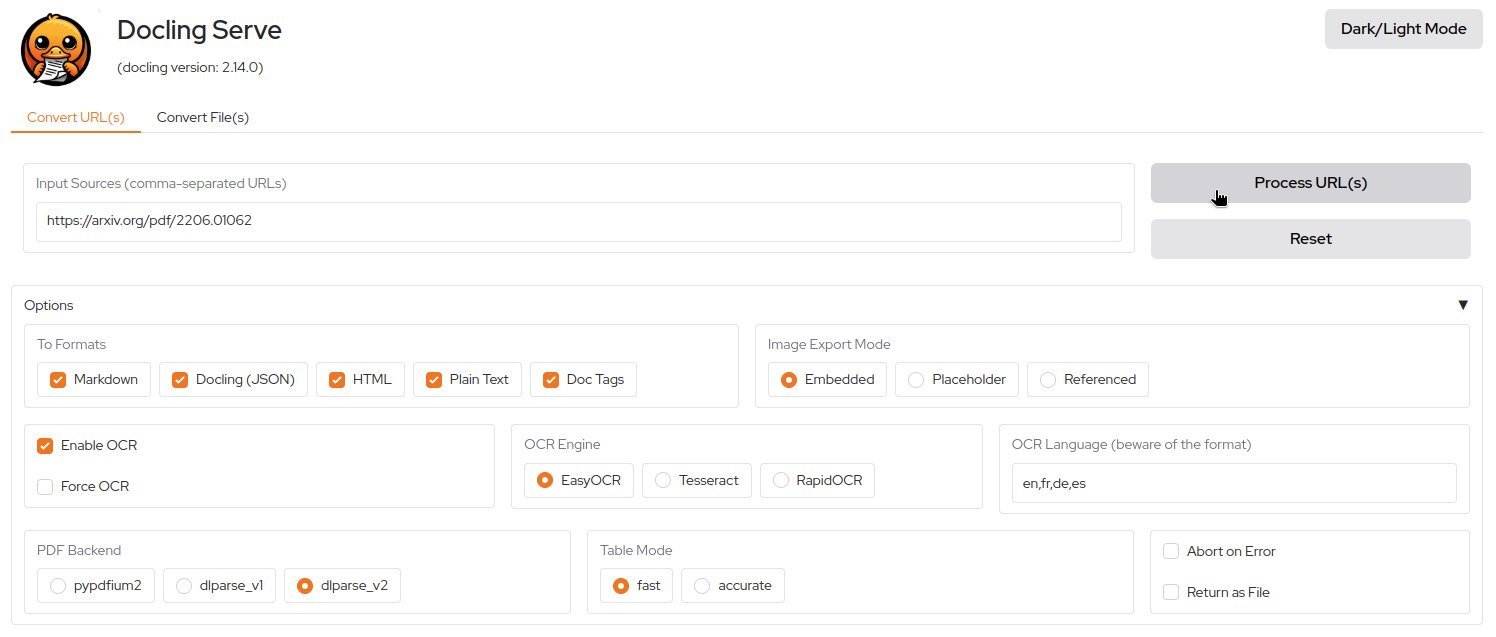
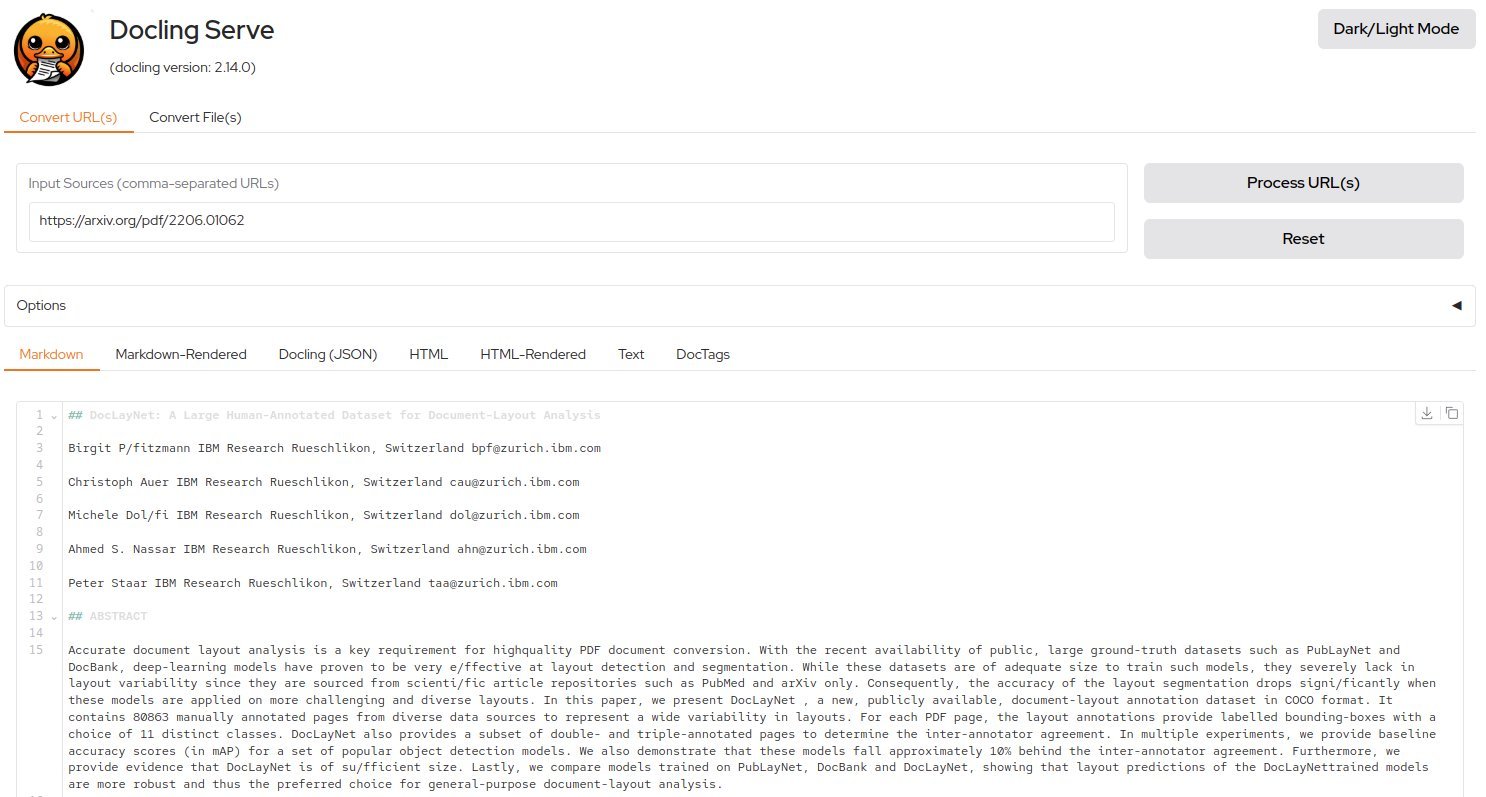 The UI interface (top) accepts document inputs while visualizing extracted outputs (bottom)
The UI interface (top) accepts document inputs while visualizing extracted outputs (bottom)
Why This Matters for Developers
Docling Serve tackles the perennial challenge of extracting meaningful data from unstructured documents—a task traditionally requiring custom OCR setups and NLP pipelines. By abstracting these complexities behind a unified API, it accelerates development of:
- Automated contract analysis systems | Research paper metadata extractors
- Archival document digitization workflows
The MIT-licensed toolkit also exemplifies IBM's open-source AI strategy, providing enterprise-grade capabilities without vendor lock-in. With upcoming "slim" container images promising reduced footprint, Docling is poised to become a staple in document processing stacks.
As organizations increasingly rely on extracting insights from document troves, tools like Docling Serve transform academic research (as detailed in their arXiv paper) into tangible infrastructure. For developers building the next generation of intelligent document processors, this v1 release delivers a battle-tested foundation—containerized, extensible, and ready for production.
Docling Serve is available on GitHub under MIT license.
Comments
Please log in or register to join the discussion