DS Serve turns any in‑house corpus into a high‑throughput, memory‑efficient neural search engine, leveraging DiskANN to break the latency–memory trade‑off that has plagued ANN at scale. With over 10 000 index‑only QPS and less than 200 GB RAM, the framework matches or surpasses commercial search endpoints while opening new avenues for RAG, data attribution, and RL training.
DS Serve: Scaling Neural Retrieval to Billion‑Vector Datasets with DiskANN
The last decade has seen neural retrieval grow from a niche research idea into a core component of large‑language‑model (LLM) pipelines. Yet scaling these systems to the size of a full LLM pre‑training corpus—hundreds of billions of tokens—has remained a bottleneck. DS Serve, a joint effort from UC Berkeley, UIUC, and UW, tackles this challenge head‑on by marrying the high‑accuracy, disk‑backed graph search of DiskANN with a production‑ready stack that includes a web UI, API, and built‑in feedback collection.
The Scaling Problem
Traditional approximate nearest neighbor (ANN) methods such as IVFPQ and HNSW hit a wall once datasets exceed a few hundred million vectors. IVFPQ’s heavy quantization either degrades recall or forces the index to spill to disk, while HNSW’s memory footprint grows linearly with the number of vectors—making a billion‑vector deployment impractical.
Figure‑1 illustrates the stark contrast in throughput and latency between the two approaches.

The result is a trade‑off triangle: accuracy, latency, and memory. For many use cases—RAG, RL agents, or large‑scale data attribution—neither side of the triangle is acceptable.
DiskANN to the Rescue
DiskANN flips the script by storing compressed vectors in RAM and full‑precision vectors plus a navigation graph on NVMe SSDs. Search begins with a candidate queue built from compressed distances, then iteratively pulls exact vectors from disk for refinement. This hybrid approach yields:
- Higher recall: full‑precision vectors eliminate quantization noise.
- Higher throughput: graph traversal reduces the number of distance computations.
- Lower latency: efficient I/O and selective disk access.
The DS Serve prototype, backed by the 380‑billion‑word CompactDS corpus, reaches >10 000 index‑only QPS and 200+ end‑to‑end QPS with <200 GB RAM.
DiskANN vs. IVFPQ comparison.
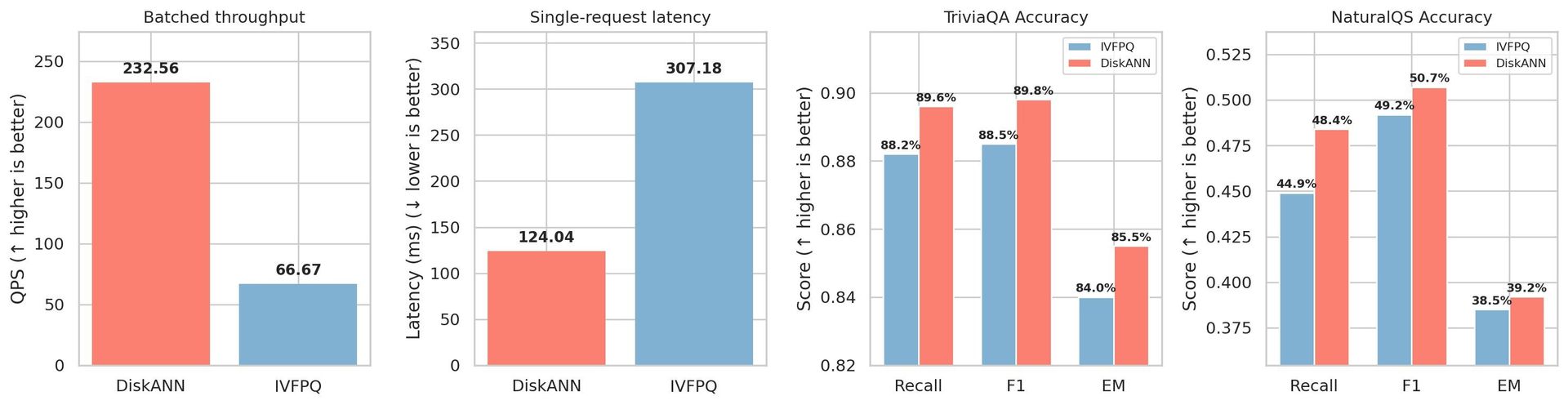
The chart shows DiskANN achieving roughly 2.3× higher throughput and 2.2× lower latency than IVFPQ at comparable recall settings.
A Full‑Featured Retrieval Stack
Beyond raw search performance, DS Serve ships a ready‑to‑deploy stack:
- Web UI for interactive exploration (see the animated demo).
- API endpoint for programmatic access.
- Voting system to collect user feedback and generate labeled data.
- Diverse Search (MMR) to reduce redundancy.
- Exact Search (GPU‑backed) for critical queries.
The UI lets developers tweak parameters on the fly, visualise results, and collect feedback—all essential for iterative RAG model training.
Applications that Benefit
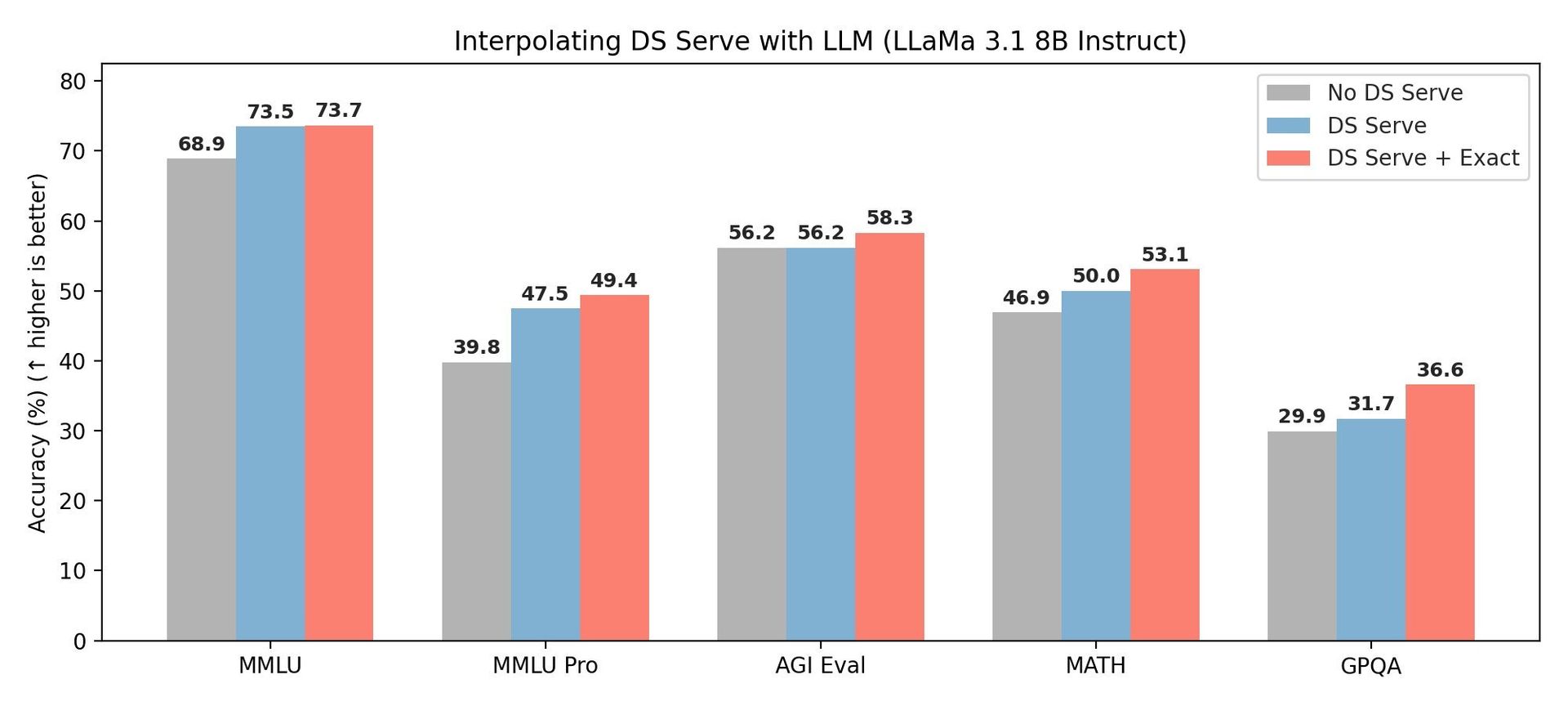
- Retrieval‑Augmented Generation (RAG) – DS Serve feeds high‑quality, low‑latency results into LLMs. Benchmarks show LLaMA 3.1 8B achieving higher downstream accuracy on MMLU, AGI‑Eval, and MATH when paired with DS Serve compared to commercial search APIs.
- Data Attribution & Curation – Indexing the entire pre‑training corpus enables semantic attribution, deduplication, and de‑contamination, surpassing n‑gram‑based tools like OLMoTrace.
- Training Search Agents – RL agents no longer suffer from costly API rate limits; DS Serve delivers a free, high‑throughput backend.
- Pushing Search Frontiers – The vector‑based approach handles long, complex queries that traditional engines struggle with, and the built‑in voting system creates realistic benchmarks.
Figure‑3 shows LLM interpolation accuracy with DS Serve.
Deployment Lessons
The engineering team documented best practices for deploying DiskANN at scale, covering index construction, SSD layout, and query‑time optimizations. Their blog post, How to Build and Use DiskANN Perfectly, is a must‑read for anyone deploying billion‑vector systems.
Performance vs. Commercial Search
DS Serve matches or exceeds Google Custom Search Engine (CSE) on downstream accuracy while delivering 30× higher throughput (batched) and 2× lower single‑request latency—all for free.
Figure‑5 compares latency and throughput between DS Serve and Google CSE.
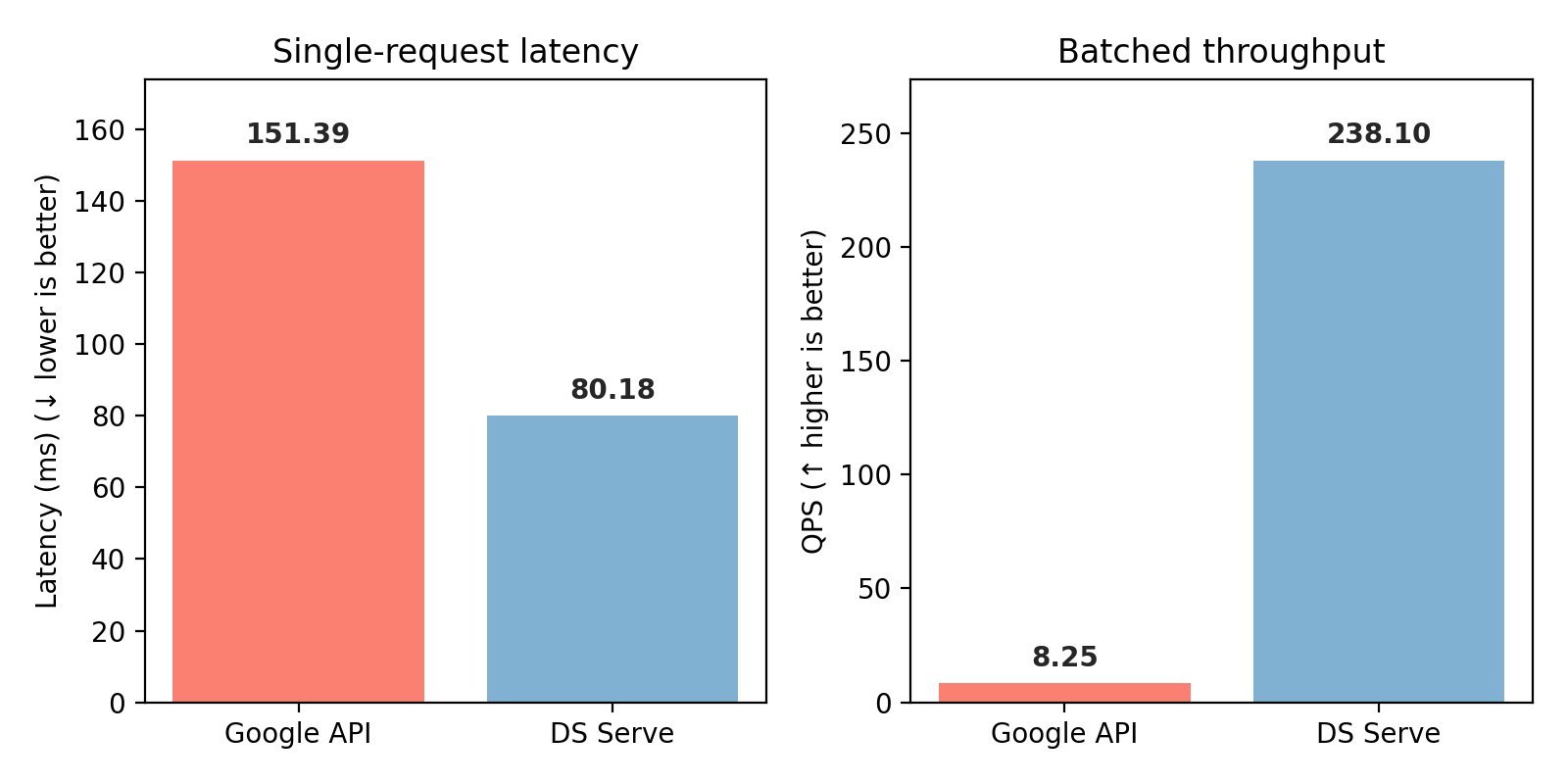
The results underscore DS Serve’s potential to replace costly commercial APIs in production RAG pipelines.
Looking Forward
With a publicly accessible vector store of 2 B vectors and 5 TB embeddings, DS Serve sets a new benchmark for open‑source neural retrieval. Its open‑source code and tooling lower the barrier for researchers and practitioners to experiment with large‑scale retrieval, potentially accelerating advances in LLMs, RL agents, and data‑centric AI.
The next frontier will involve tighter integration with GPU‑accelerated exact search, smarter caching strategies for repeated queries, and broader adoption of the built‑in feedback loop to continuously refine retrieval quality.
Comments
Please log in or register to join the discussion