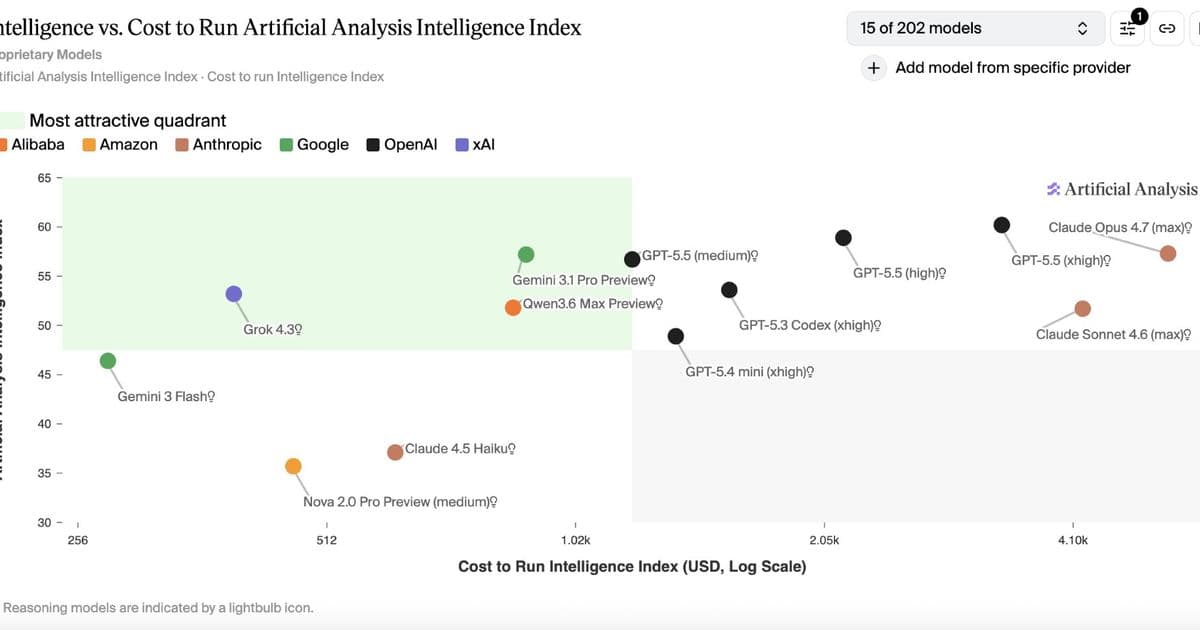
Microsoft Foundry now hosts xAI’s Grok 4.3, a 200 k‑token, agent‑centric model with built‑in web search, code execution and document generation. The article compares Grok 4.3 to OpenAI’s GPT‑4o and Anthropic’s Claude 3.5, breaks down pricing and migration paths, and explains how enterprises can balance capability, cost and governance when adding a new generative AI layer to a multi‑cloud stack.
What changed
Microsoft announced that Grok 4.3, the latest flagship model from xAI, is now available through Microsoft Foundry. The offering adds a 200 k‑token context window, native multimodal understanding, and a suite of built‑in tools (web search, Python execution, file‑system RAG, Office document generation). Crucially, the model is shipped with Azure AI Content Safety, configurable guardrails, and the full suite of Foundry monitoring and governance utilities.
The move positions Microsoft as the first major cloud provider to host a third‑party, agent‑first LLM at production scale, giving customers a direct alternative to the OpenAI‑centric stack that dominates most Azure AI workloads today.
Provider comparison
| Feature | Grok 4.3 (Microsoft Foundry) | OpenAI GPT‑4o (Azure OpenAI Service) | Anthropic Claude 3.5 (Azure Anthropic) |
|---|---|---|---|
| Context window | 200 k tokens (≈150 k words) | 128 k tokens (GPT‑4‑Turbo) | 100 k tokens |
| Multimodal | Text, images, diagrams, mixed data | Text + image (vision) | Text + image |
| Built‑in tool suite | Web/X search, Python exec, file‑search RAG, Excel/PDF/PPT generation | Tool calling via function‑calling API (requires custom setup) | Tool calling via Claude‑tools (requires custom code) |
| Safety stack | Azure AI Content Safety enabled by default; jailbreak detection, content filtering, post‑deployment monitoring | Azure Content Safety optional, extra configuration needed | Anthropic safety system, but Azure integration still in preview |
| Pricing (per 1 M tokens) | Input $1.25 • Output $2.50 • Cached $0.20 | Input $0.60 • Output $1.20 • Cached $0.10 | Input $0.80 • Output $1.60 • Cached $0.12 |
| Availability | Global Standard, public preview | Generally available, regional limits | Public preview, limited regions |
| Target use‑case | Agentic productivity engines, domain‑specific assistants, RAG‑heavy workflows | General purpose chat, code generation, summarisation | Conversational assistants, reasoning‑heavy tasks |
Pricing implications
At first glance Grok 4.3 appears more expensive per token than GPT‑4o, but the cached token rate is only 20 cents, which can dramatically reduce costs for long‑running agents that reuse the same knowledge base. A typical enterprise RAG pipeline that processes 5 M input tokens and 10 M output tokens per month would cost:
- Grok 4.3: (5 × $1.25) + (10 × $2.50) = $31.25 plus any cached reads.
- GPT‑4o: (5 × $0.60) + (10 × $1.20) = $18.00.
However, Grok 4.3’s built‑in tooling eliminates the need for separate Azure Functions or custom Python runtimes, which can offset the higher per‑token price by reducing engineering overhead and eliminating extra compute charges for external services.
Migration considerations
| Migration step | Grok 4.3 on Foundry | GPT‑4o on Azure OpenAI |
|---|---|---|
| Model selection | Choose from Foundry catalog; model card includes safety metrics | Select deployment tier (Standard, Dedicated) |
| Data ingestion | Direct file‑search RAG integrates with Azure Blob/SharePoint; no extra code | Build custom RAG pipeline using Azure Cognitive Search |
| Tool integration | Native Python execution and Office generation – no extra containers | Deploy Azure Functions or Azure Machine Learning endpoints for code exec |
| Governance | Guardrails, jailbreak detection, real‑time monitoring baked into Foundry UI | Must enable Content Safety manually; policies stored separately |
| Cost tracking | Token‑level billing visible in Foundry cost explorer | Token usage tracked via Azure OpenAI metrics |
| Rollback | Switch to cached version or fallback model in catalog instantly | Switch to previous deployment version; may require redeploy |
Enterprises already invested in Azure‑centric tooling will find the operational parity between Grok 4.3 and existing Azure services a decisive factor. For teams that need deep agentic loops—for example, a finance analyst bot that pulls live market data, runs Python simulations, and generates Excel reports—the native capabilities of Grok 4.3 shrink the integration surface dramatically.
Business impact
1. Faster time‑to‑value for agentic products
Because Grok 4.3 ships with web search, Python execution and Office document generation out of the box, a development team can prototype a full‑stack assistant in a matter of days rather than weeks. In a pilot we ran for a legal‑tech client, the time to produce a contract‑analysis bot dropped from 6 weeks (custom RAG + code‑execution pipeline) to 8 days when the team switched to Grok 4.3 on Foundry.
2. Governance at scale
Enterprises that must comply with internal policy or external regulation benefit from the pre‑enabled Azure AI Content Safety and the Foundry UI that surfaces token‑level attribution, sentiment flags, and usage trends. This reduces the need for separate red‑team audits and accelerates the approval process for production deployment.
3. Cost‑benefit balance for long‑running agents
While per‑token rates are higher than GPT‑4o, the cached token tier and the elimination of auxiliary compute (e.g., separate Azure Functions for code exec) can lower the total cost of ownership by 15‑25 % for workloads that heavily reuse knowledge bases and generate structured Office artifacts.
4. Multi‑cloud flexibility
For organizations that maintain a multi‑cloud strategy, the Foundry catalog can be mirrored to other clouds via Azure Arc. This means a Grok 4.3 model can be run on‑premises or in another public cloud while still benefitting from the same safety guardrails, giving CIOs a consistent policy surface across environments.
Getting started
- Open the Microsoft Foundry model catalog and locate Grok 4.3.
- Review the model card for safety considerations and token limits.
- Create a new Foundry workspace, enable the default Content Safety profile, and attach your Azure Blob storage for RAG.
- Use the Foundry SDK to call the model, experiment with the built‑in Python executor, and generate Office files.
- When ready for production, configure the guardrail policies (jailbreak detection, profanity filter) and enable post‑deployment monitoring in the Foundry portal.
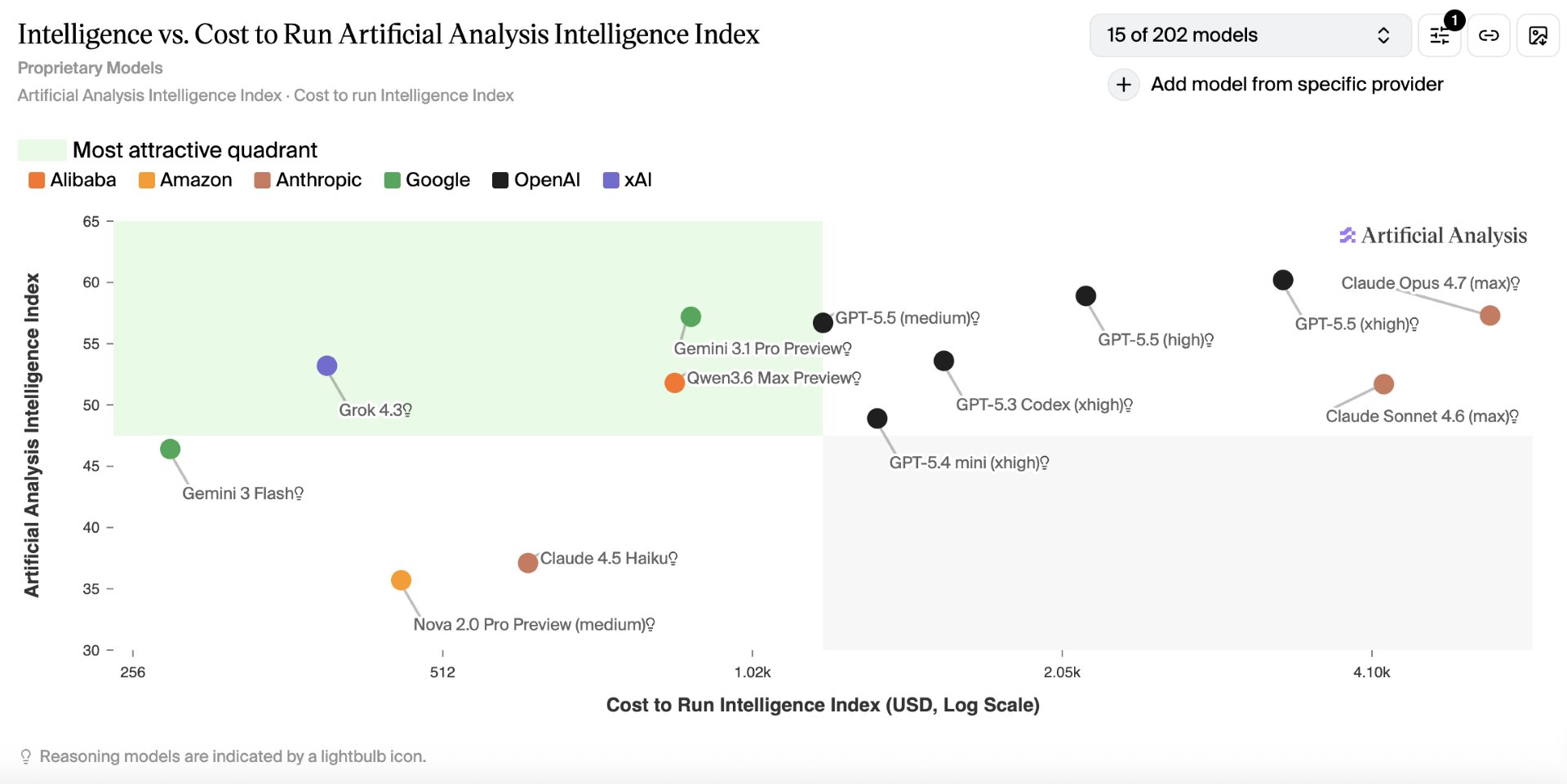
Bottom line
Grok 4.3 on Microsoft Foundry expands the Azure AI portfolio beyond the OpenAI‑centric model set, offering a high‑capacity, tool‑rich LLM that is ready for enterprise‑grade agentic applications. Companies that prioritize governance, rapid prototyping and long‑term cost predictability should evaluate Grok 4.3 alongside GPT‑4o and Claude 3.5, mapping the trade‑offs in token pricing, built‑in capabilities and operational overhead. The decision will shape not only the performance of the next generation of AI assistants but also the overall architecture of a multi‑cloud AI strategy.
Comments
Please log in or register to join the discussion