
South Korean researchers unveil HetCCL, a vendor-agnostic collective communications library that enables Nvidia and AMD GPUs to work together seamlessly via RDMA, potentially reducing costs and complexity in heterogeneous AI data centers.
A team of South Korean researchers has unveiled HetCCL, a groundbreaking collective communications library that enables Nvidia and AMD GPUs to communicate seamlessly within the same cluster, potentially transforming how heterogeneous AI data centers operate.
The Problem with Vendor Lock-in
In modern AI data centers, fast networked communication across nodes is as critical as the processing power of the nodes themselves. Currently, developers working on AI workloads are typically steered toward vendor-specific networking libraries like Nvidia's NCCL (NVIDIA Collective Communications Library) or AMD's RCCL (ROCm Collective Communications Library). This creates a significant barrier to building heterogeneous environments where different GPU vendors coexist.
How HetCCL Works
HetCCL takes a fundamentally different approach by providing a vendor-agnostic solution that allows clusters composed of GPUs from multiple vendors to operate as a unified system. The library leverages Remote Direct Memory Access (RDMA), which enables applications to pass data directly into GPU memory across the network without going through the traditional driver, TCP/IP stack, and OS networking layers. This approach dramatically reduces CPU overhead and latency.
The researchers claim HetCCL is a "world-first drop-in replacement" for vendor-specific CCLs, accomplishing several key objectives simultaneously:
- Cross-platform communication: Enables GPUs from different vendors to work together
- Load balancing: Distributes workloads efficiently across heterogeneous hardware
- Future-proofing: Implicitly supports any new GPU vendors that emerge
- Minimal overhead: Sometimes even outperforms original CCL implementations
Technical Implementation
Perhaps most impressively, HetCCL purports to be a direct library replacement that requires no source code changes. Developers simply need to link their applications to HetCCL instead of their vendor's CCL. The research team likens this to changing a DLL in a game to inject post-processing filters—the application code remains unchanged from top to bottom.
This abstraction layer means application developers don't need to worry about whether their data transfer calls will actually reach the intended GPUs, regardless of vendor. The library handles all the underlying complexity of cross-vendor communication.
Performance Results
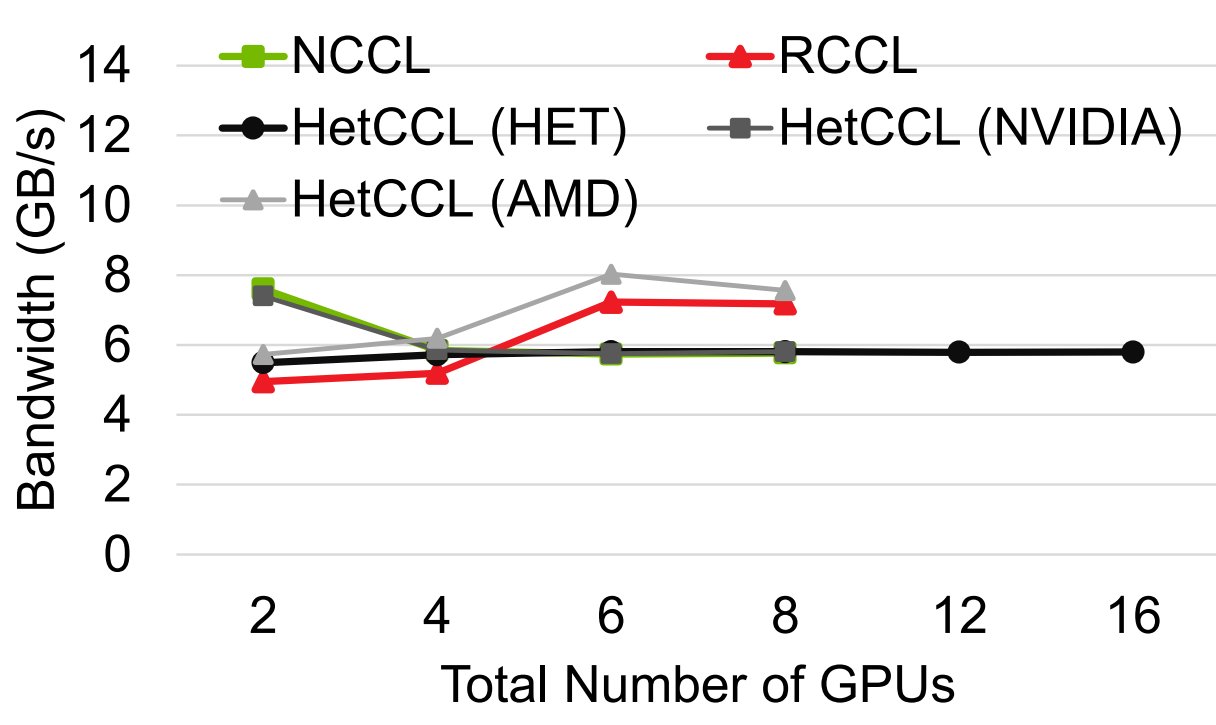
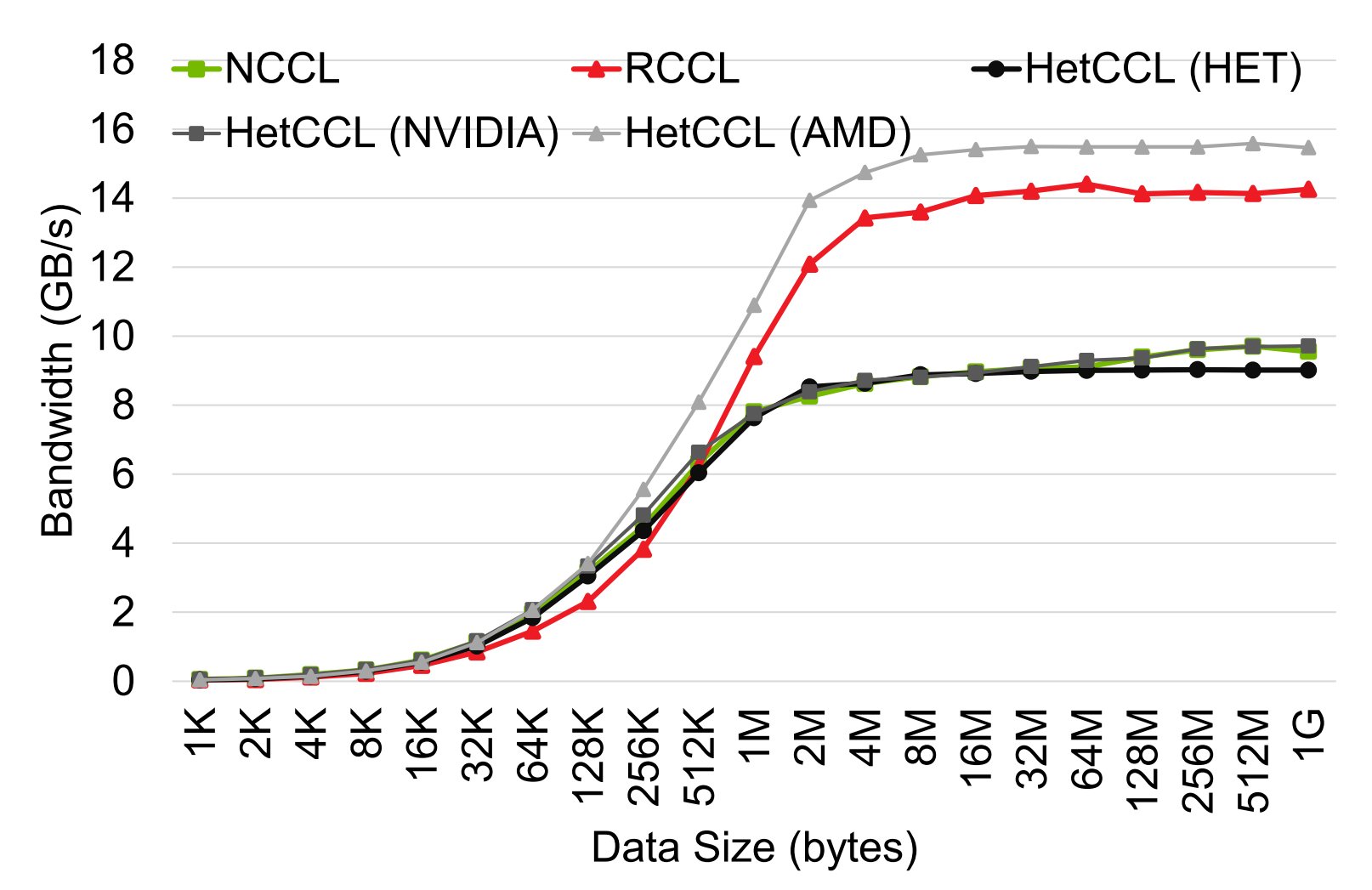
The research team conducted tests on a four-node cluster configuration:
- 2 nodes with 4 Nvidia GPUs each
- 2 nodes with 4 AMD GPUs each
It's important to note that these results aren't meant to be cross-vendor benchmarks but rather demonstrate HetCCL's potential with limited test resources. The Nvidia systems used PCI 3.0 GPUs while the AMD systems had PCIe 4.0 units—all older hardware by current standards.
In many test scenarios, HetCCL achieved results approaching theoretical maximums by effectively combining Nvidia and AMD computing power. While performance will naturally vary across different setups and workloads, the ability to approach these limits with heterogeneous hardware is noteworthy.
Market Implications
The introduction of HetCCL could have significant implications for AI data center economics:
Cost Reduction: By efficiently utilizing both Nvidia and AMD GPUs simultaneously, organizations can avoid splitting tasks between separate clusters that wait on each other. This could lower training costs for machine learning models.
Operational Efficiency: Managing tasks across heterogeneous environments becomes simpler, potentially saving man-hours in system administration and workload orchestration.
Vendor Flexibility: Organizations gain the freedom to choose the best hardware for specific workloads without being locked into a single ecosystem.
Challenges and Limitations
Despite its promise, several obstacles remain:
Ecosystem Lock-in: Choosing a GPU vendor typically implies committing to an entire software ecosystem. Nvidia's CUDA platform remains the de facto standard, making it difficult to justify heterogeneous deployments.
Conservative IT Practices: System administrators tend to prefer single-vendor solutions for ease of maintenance, support, and troubleshooting.
Beyond Networking: While HetCCL solves the networking abstraction problem, model training and most AI tasks still involve substantial GPU-specific code and optimization. The networking layer is just one piece of a complex puzzle.
The Road Ahead
HetCCL's primary achievement is demonstrating that removing a major roadblock for heterogeneous AI setups is technically feasible. The researchers hope their work will inspire others to develop similar solutions, potentially leading to a more open and competitive AI hardware ecosystem.
As AI workloads continue to grow in complexity and scale, the ability to mix and match hardware from different vendors could become increasingly valuable. HetCCL represents an important step toward breaking down the artificial barriers that currently fragment the AI computing landscape.

The research paper and implementation details are available through the HetCCL research team's publications, though specific URLs were not provided in the source material.
Comments
Please log in or register to join the discussion