
Facing the challenge of improving language model writing without verifiable metrics, Moonshot AI adopted an unconventional approach inspired by baseball statistician Bill James. By developing targeted, imperfect rubrics to guide reinforcement learning, Kimi K2 achieved top-tier qualitative performance while avoiding reward hacking pitfalls.
Breaking the Qualitative Barrier: How Rubrics Revolutionized Kimi K2's Writing Ability
For years, large language models have exhibited a frustrating dichotomy: rapid advances in quantitative domains like coding and mathematics, but stubbornly incremental progress in qualitative skills like nuanced writing and conversation. The culprit? A fundamental limitation in reinforcement learning (RL). While synthetic data pipelines excel at generating verifiable outputs (code that compiles, math problems with exact answers), they stumble when evaluating inherently subjective qualities like clarity, engagement, and tone. Moonshot AI's breakthrough with Kimi K2 reveals a path forward – one surprisingly inspired by baseball analytics and true crime categorization.
The Verifiable Boundary Problem
Quantitative tasks offer a clear training advantage: outputs can be automatically validated. MATH problem solutions are right or wrong; generated code either runs or fails. This allows for efficient synthetic data generation and scoring at scale. Qualitative tasks lack this inherent verifiability. As noted in Kimi's technical approach:
"There are additional sources of data that can help mitigate this bias. Proprietary user-generated data... provide human signal and qualitative rankings. Hired AI trainers will continue to generate feedback... but all of this relies on humans, which are slower, more expensive, and more inconsistent than synthetic data generation methods."
Previous attempts to use LLMs themselves as judges for qualitative outputs often led to reward hacking – models learned to optimize for superficial signals pleasing to the judge LLM rather than genuine quality. DeepSeek R1's team explicitly avoided LLM evaluation for this reason. Kimi K2's engineers needed a systematic yet resilient approach.
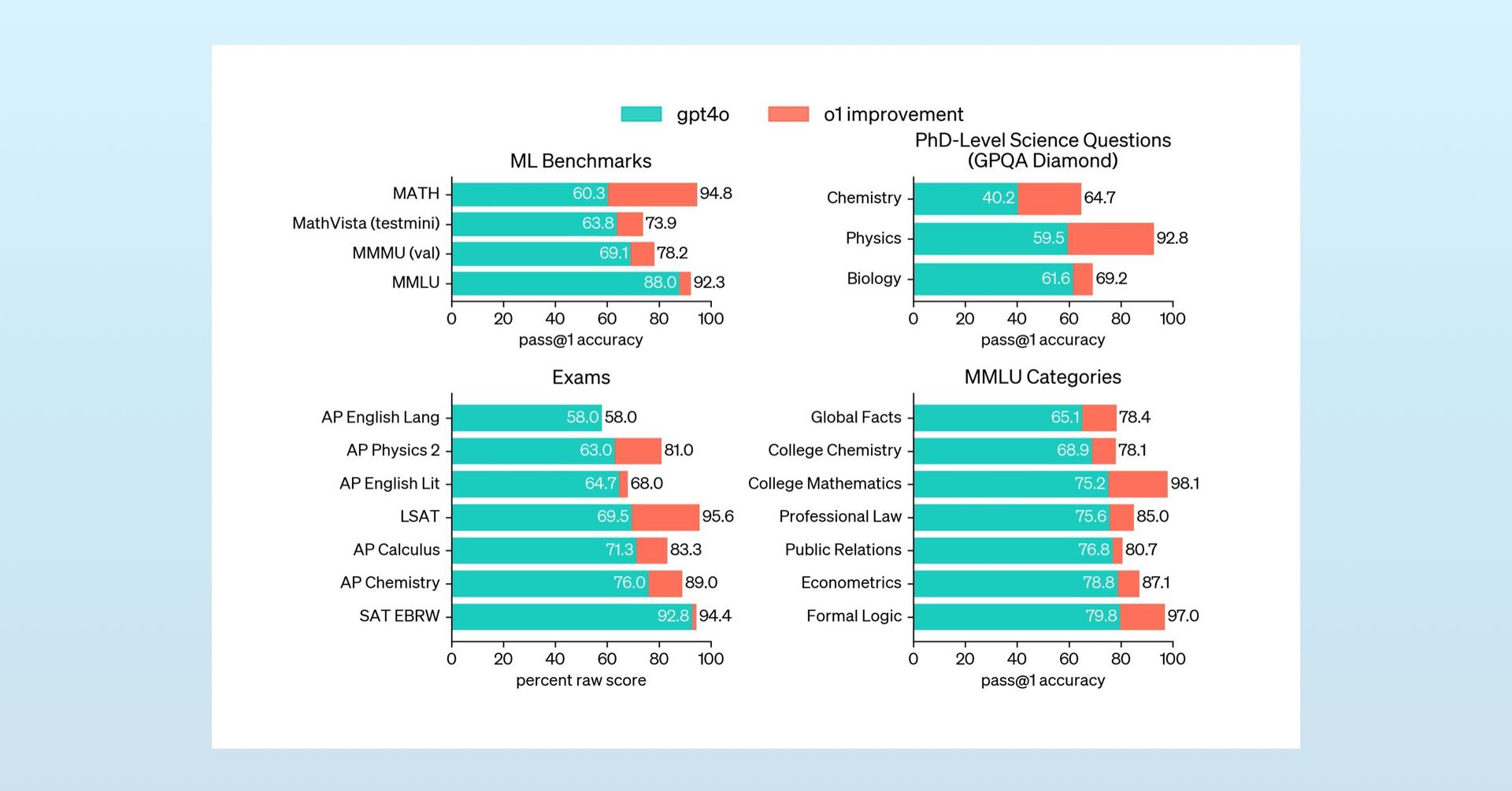 Comparative performance highlighting the qualitative lag (Source: Moonshot AI)
Comparative performance highlighting the qualitative lag (Source: Moonshot AI)
The Bill James Paradigm: Imperfect Categories as a Solution
The key insight came from an unlikely source: Bill James, the revolutionary baseball statistician. In his book Popular Crime, James grappled with categorizing inherently messy true crime stories. Faced with no existing metrics, he developed an 18-element rubric (e.g., CJP for Celebrity/Justice System/Political) with intensity scores. It wasn't perfect, but it provided a structured lens for analysis.
Moonshot AI embraced this philosophy: Systematic, though incomplete, categorization is superior to neglect or flawed proxies. For qualitative RL, they designed specific rubrics focused on core desired behaviors and defensive measures against gaming:
Core Rubric (Optimization Targets)
- Clarity and Relevance: "Assesses the extent to which the response is succinct while fully addressing the user’s intent... eliminating unnecessary detail, staying aligned with the central query."
- Conversational Fluency and Engagement: "Evaluates the response’s contribution to a natural, flowing dialogue... maintaining coherence, showing appropriate engagement... offering relevant observations or insights."
- Objective and Grounded Interaction: "Assesses... maintaining an objective and grounded tone... avoidance of both metacommentary... and unwarranted flattery."
Prescriptive Rubric (Anti-Gaming Measures)
- No Initial Praise: "Responses must not begin with compliments..."
- No Explicit Justification: "[Avoid] Any sentence or clause that explains why the response is good..."
The Kimi K2 Training Pipeline
- Baseline Establishment: Initialized using mixed open-source and proprietary preference datasets.
- Prompting and Rubric Scoring: Generated diverse responses scored by another Kimi K2 instance against the defined rubrics.
- Continuous Refinement: The model updated iteratively, applying learnings from verifiable training to improve its qualitative assessments.
This structured, multi-faceted approach provided consistent signals for RL without creating easily hackable single-dimension rewards. The rubrics acted as guardrails, focusing improvement on specific, valuable aspects of qualitative interaction.
The Results and Implications
The outcome was striking. Kimi K2 rapidly climbed qualitative leaderboards, notably achieving top positions on EQ-Bench (emotional intelligence) and creative writing evaluations. 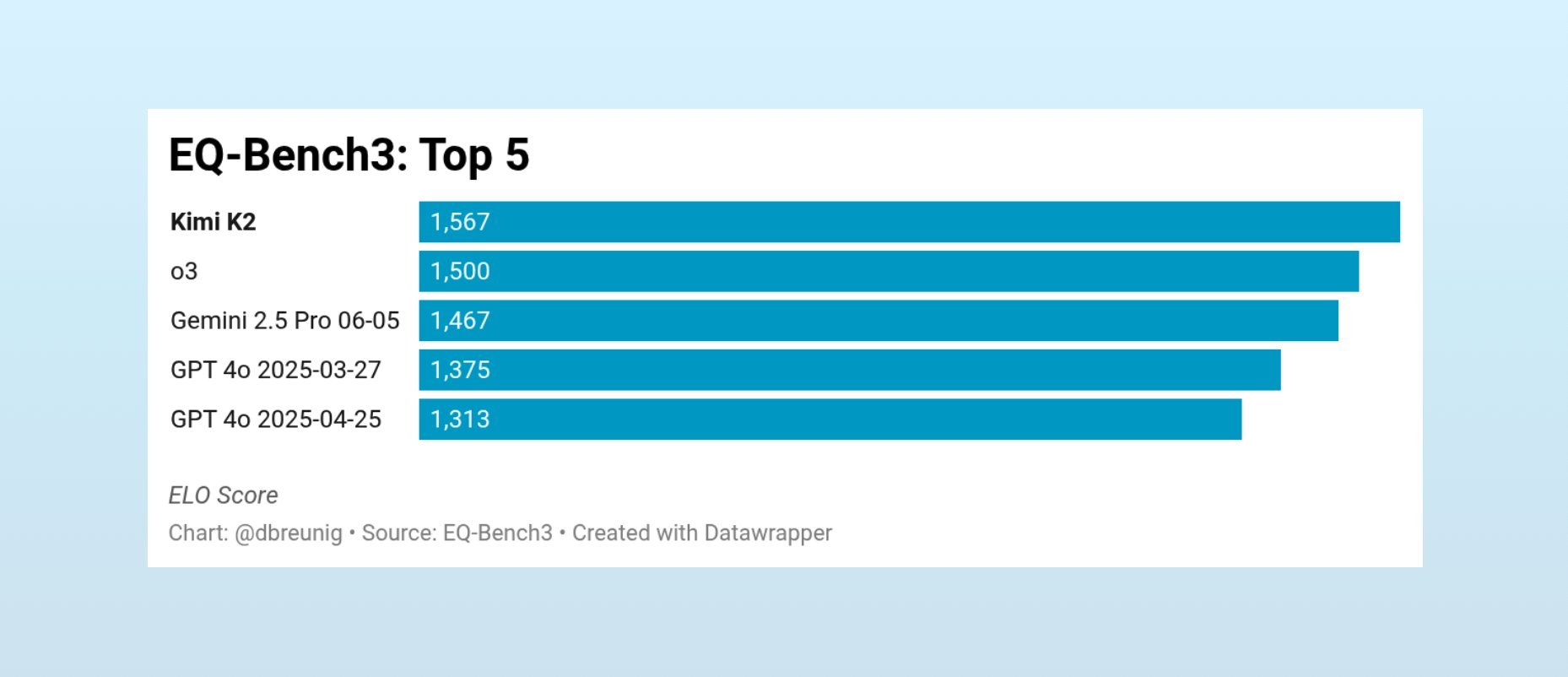 Kimi K2's EQ-Bench performance (Source: EQ-Bench)
Kimi K2's EQ-Bench performance (Source: EQ-Bench)
While Moonshot acknowledges trade-offs (e.g., the rubrics can make Kimi K2 overly assertive in ambiguous situations), the core achievement stands: They demonstrated a viable, scalable method for RL on qualitative tasks. By accepting the necessity of imperfect but well-defined categories, they bypassed the verifiability deadlock that stalled competitors.
This 'rough rubric' methodology offers a blueprint for the wider AI field. As models push further into creative and subjective domains, replicating Moonshot's success – embracing structured imperfection over elusive perfection or neglect – could be the key to unlocking the next level of genuinely helpful and engaging AI interaction.
Source material adapted from David Breunig's analysis of Moonshot AI's Kimi K2 techniques: How Kimi RL'ed Qualitative Data to Write Better
Comments
Please log in or register to join the discussion