Sentry solved the database performance nightmare of analyzing billions of unstructured performance spans by applying classic hash table principles to ClickHouse. Their innovative bucketing strategy reduced query times from seconds to milliseconds, unlocking real-time observability at scale. This breakthrough now powers critical features like custom dashboards and distributed tracing across their platform.
At Sentry, we ingest billions of performance spans daily—discrete measurements capturing everything from webpage load times to phone call durations. Unlike structured analytics data, these spans are fundamentally unstructured: attributes like browser or callResolved appear inconsistently across different event types. This posed an existential challenge for our three core use cases:
- Alerting: Trigger notifications when metrics exceed thresholds
- Graphing: Visualize metric trends over time
- Tracing: Investigate specific user transaction failures
All rely on our ClickHouse-based Snuba service, but traditional schemas buckled under unstructured data volumes. Our journey reveals how rethinking database architecture through first principles yielded dramatic performance gains.
The Unstructured Data Dilemma
-- Problematic schema attempting to handle unstructured attributes
CREATE TABLE spans_v1(
id UInt(64),
browser String,
mobile_device String,
duration_ms Float(64),
/* 1000+ other optional columns */
)
Our initial approach—creating columns for every possible attribute—failed catastrophically. ClickHouse allocates memory per column during inserts, causing terabytes of wasted space for sparse attributes. The Map type offered hope:
CREATE TABLE spans_v2(
id UInt(64),
attributes_string Map(String, String),
attributes_float Map(String, Float(64))
)
But this consolidated all attributes into monolithic files. Querying a single key like attributes_float['duration_ms'] required scanning every numeric attribute—like searching a phone book by reading every page.
Hash Tables: A 70-Year-Old Solution to a Modern Problem
{{IMAGE:3}}
We drew inspiration from hash tables—a fundamental data structure since the 1950s. By distributing keys across multiple "buckets" via hashing, lookup times become constant. We implemented this in ClickHouse:
CREATE TABLE spans_v3(
id UInt(64),
attributes_string_0 Map(String, String),
/* ... */
attributes_string_49 Map(String, String),
attributes_float_0 Map(String, Float(64)),
/* ... */
attributes_float_49 Map(String, Float(64))
)
Each attribute key (e.g., 'duration_ms') hashes to a specific bucket (0-49). Queries now target only relevant buckets:
# Pseudocode for query routing
bucket_idx = fnv_1a_hash("duration_ms") % 50 # e.g., returns 23
query_column = "attributes_float_23['duration_ms']"
This reduced data scanned per query by ~98% (50 buckets → 2% scan per query).
Performance Transformation: Benchmarks That Speak Volumes
| Query Type | Original (v2) | Bucketed (v3) | Improvement |
|---|---|---|---|
| OLAP: Aggregate filtered spans | 2.643 sec | 0.042 sec | 62x |
| Trace retrieval | 4.076 sec | 2.334 sec | 1.7x |
| Span fetching for trace | 0.016 sec | 0.021 sec | Comparable |
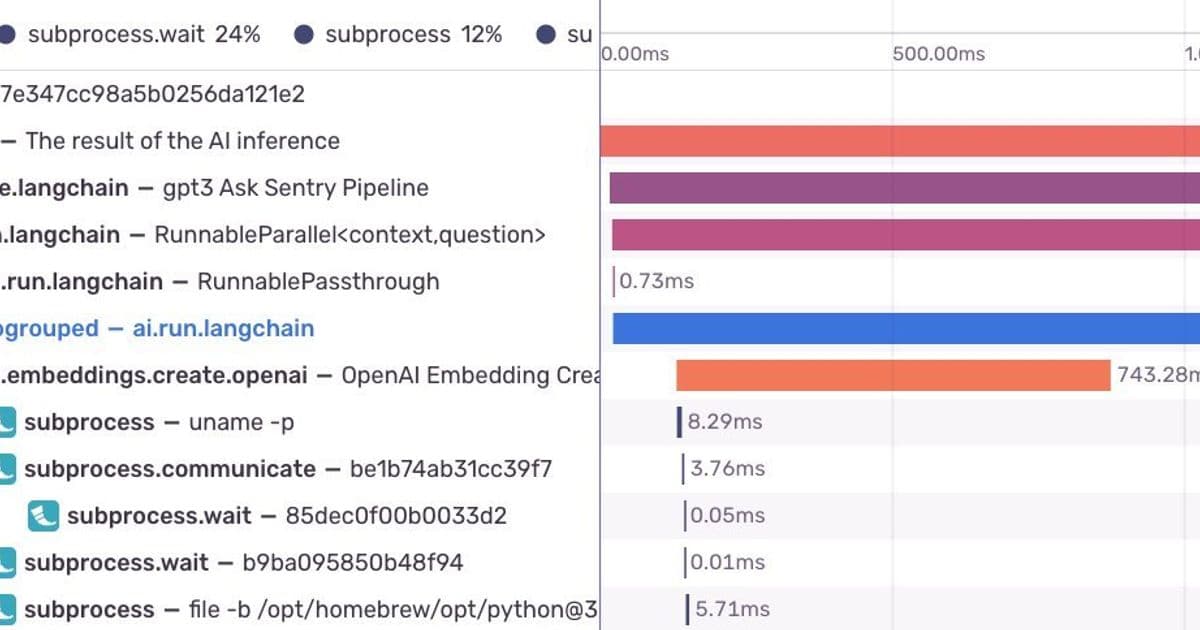
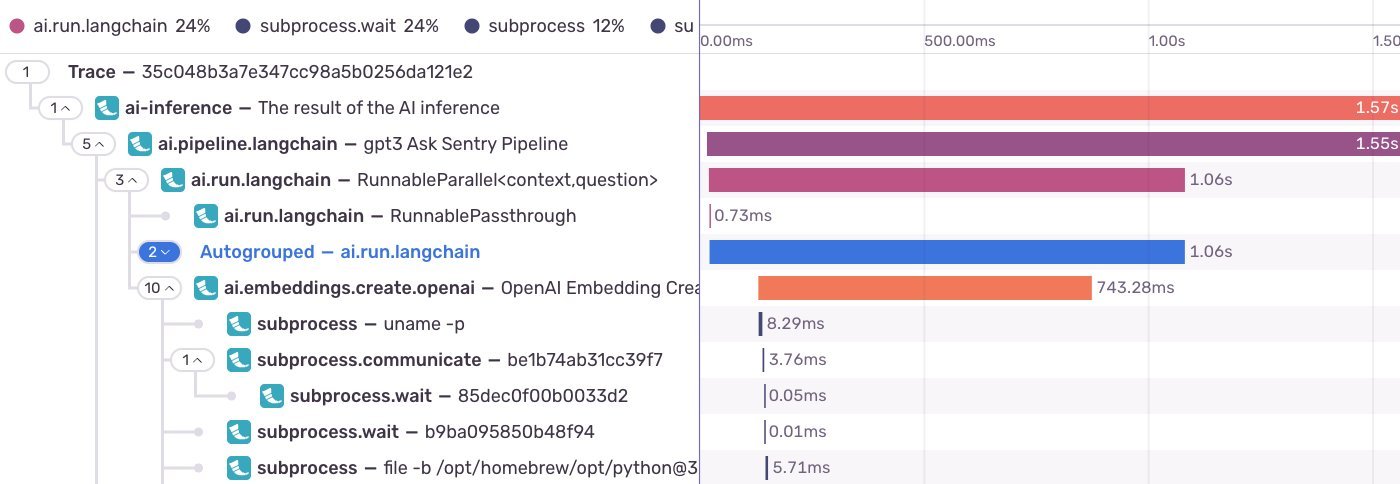
The star performer—analytical queries powering dashboards—accelerated by 62x. Even complex trace searches nearly doubled in speed. 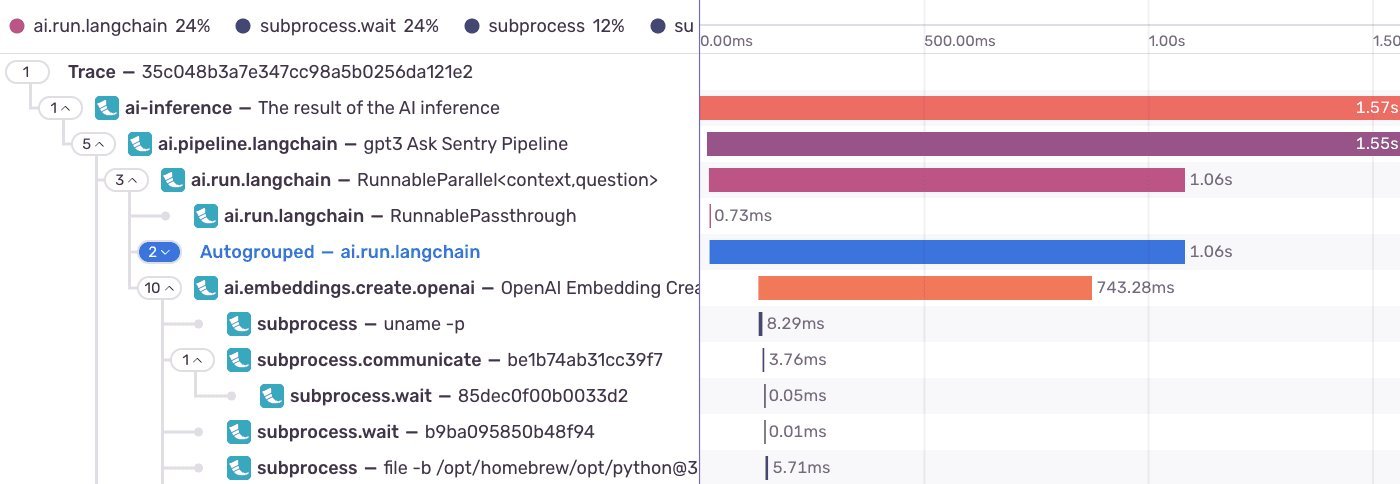 shows how these optimizations manifest in Sentry's tracing UI.
shows how these optimizations manifest in Sentry's tracing UI.
Beyond Benchmark Hype: Real-World Impact
This architecture now underpins Sentry's most demanding features:
- Custom dashboards with real-time metric visualizations
- Log storage with rapid attribute-based filtering
- Distributed tracing at billion-event scale
By revisiting computer science fundamentals, we avoided costly infrastructure expansion while achieving sub-second query performance. The lesson? Sometimes the most powerful solutions aren't found in new tools—but in creatively applying timeless concepts to modern challenges.
Comments
Please log in or register to join the discussion