Uber has transitioned its in-house search indexing system to OpenSearch's pull-based ingestion framework, replacing push-based ingestion to improve reliability, backpressure handling, and recovery for real-time indexing workloads.
Uber has moved its in-house search indexing system to OpenSearch by introducing a pull-based ingestion framework for large-scale streaming data. The change goal was to improve reliability, backpressure handling, and recovery for real-time indexing workloads, after evolving product requirements revealed the growing cost and complexity of maintaining a homegrown search platform, including challenges around schema evolution, relevance tuning, and multi-region consistency.
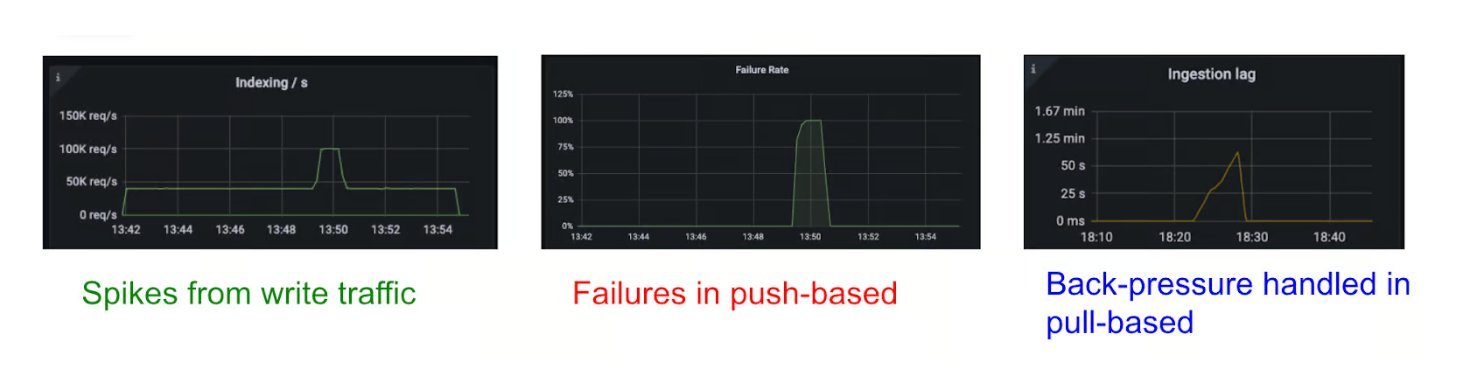
Uber's search infrastructure supports ride discovery, delivery selection, and location-based queries, processing continuous event streams in near real time. Its in-house search platform relied on push-based ingestion, where upstream services wrote directly to clusters. While effective at a small scale, this approach struggled with bursts and failures, causing dropped writes and complex retries. Pull-based ingestion shifts responsibility to the OpenSearch cluster. Shards pull data from durable streams such as Kafka or Kinesis, which act as buffers, allowing controlled rates, internal backpressure, and replay for recovery. Uber engineers report that this approach reduces indexing failures during spikes and simplifies operational recovery. Bursty traffic that previously overwhelmed shard queues is now absorbed by per-shard bounded queues, improving throughput and stability.
Architecture Components
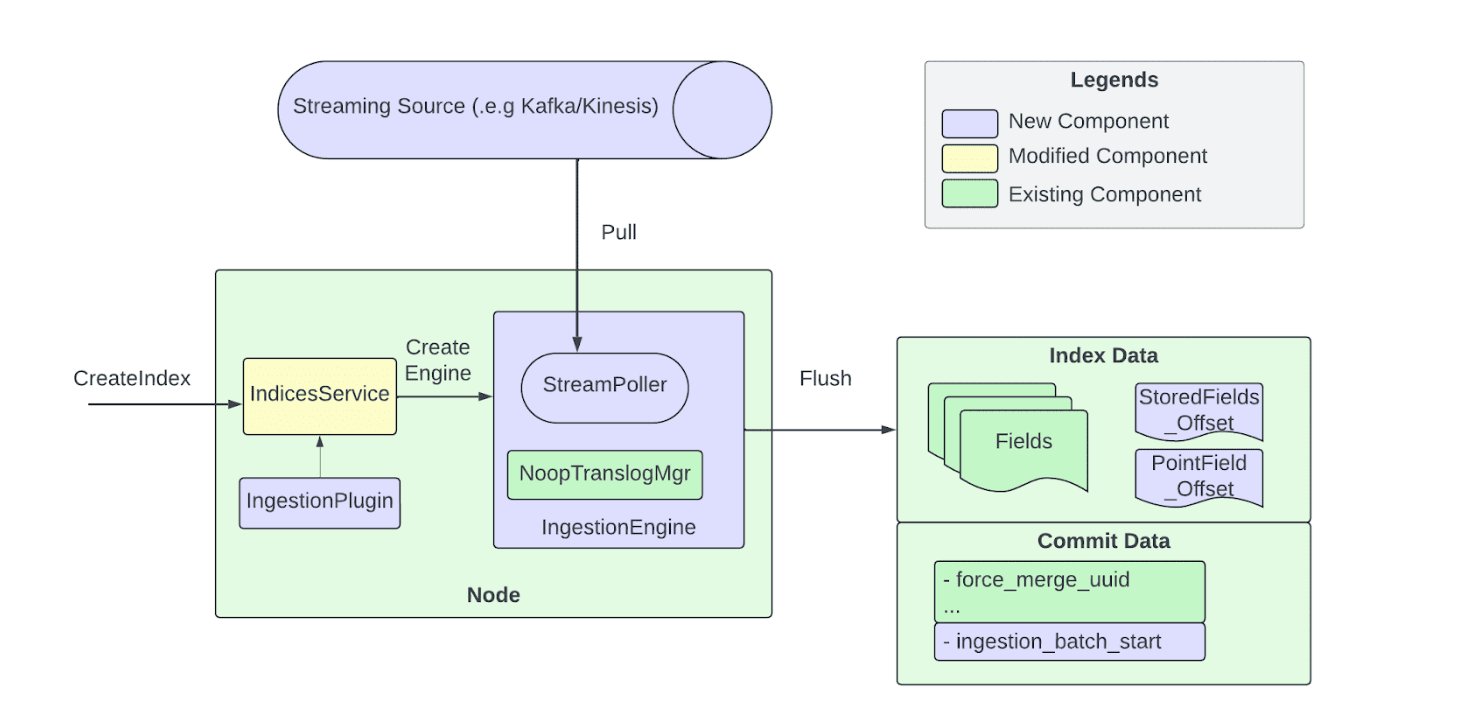
The pull-based pipeline includes multiple interacting components. Events are produced into Kafka or Kinesis topics, with each shard mapped to a stream partition for deterministic replay. A stream consumer polls messages into a blocking queue, decoupling consumption from processing and enabling parallel writers. Messages are processed by separate threads that validate, transform, and prepare indexing requests before passing them to the ingestion engine. The engine writes directly to Lucene, bypassing the translog, while tracking processed offsets for deterministic recovery.
Operational Controls and Reliability
According to Uber Engineers, pull-based ingestion also provides fine-grained operational controls. External versioning ensures out-of-order messages do not overwrite newer updates, and at-least-once processing guarantees consistency. Operators can configure failure policies: messages may be discarded under a drop policy or retried indefinitely under a block policy. APIs allow ingestion to be paused, resumed, or reset to specific offsets, helping teams manage backlogs after outages.
Uber supports two ingestion modes. Segment replication ingests data only on primary shards, with replicas fetching completed segments, reducing CPU usage with a slight visibility lag. All-active mode ingests on all shard copies, providing near-instant visibility at a higher compute cost.
Multi-Region Architecture
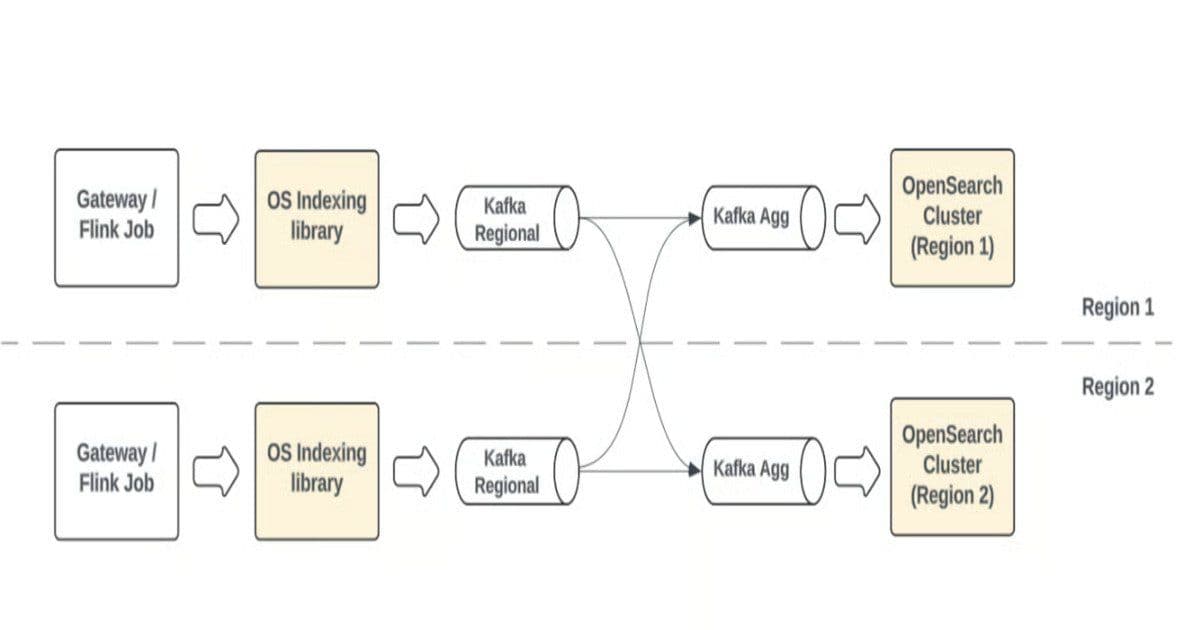
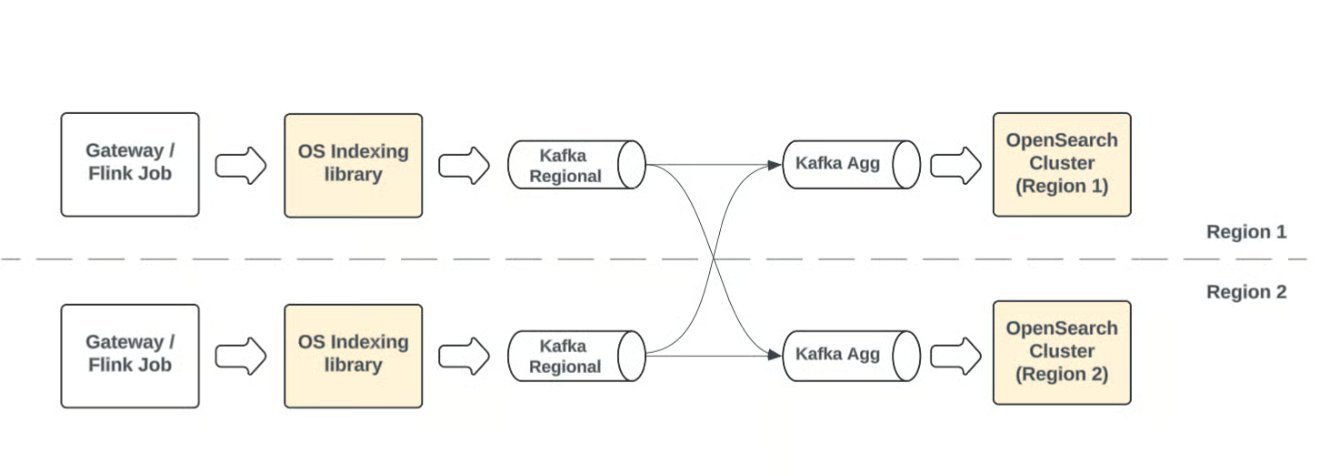
Pull-based ingestion is central to Uber's highly available, multi-region search architecture. Each regional OpenSearch cluster consumes from globally aggregated Kafka topics to build complete, up-to-date indexes. This design ensures redundancy, global consistency, and seamless failover, so users worldwide interact with a consistent search view while maintaining high availability.
Migration and Future Plans
Uber is gradually migrating all search use cases to OpenSearch's pull-based ingestion, moving toward a cloud-native, scalable architecture while continuing to enhance the platform and contribute to the OpenSearch community. This transition represents a significant architectural shift that addresses the limitations of push-based systems while providing better operational controls and reliability for large-scale search workloads.
Comments
Please log in or register to join the discussion