
A technical deep dive into the forensic analysis of 4,085 PDF files released by the U.S. Department of Justice under the Epstein Files Transparency Act reveals meticulous—though imperfect—redaction techniques. Cybersecurity experts uncover hidden metadata quirks and incremental update patterns while debunking claims of recoverable text, highlighting the complexities of secure document sanitization.
The recent release of documents related to the Epstein case under the "Epstein Files Transparency Act" thrust thousands of PDFs into public view—and under forensic scrutiny. Unlike public speculation about content, a technical analysis by PDF experts reveals critical insights into document integrity, redaction robustness, and metadata handling that every developer and security professional should understand.
The Forensic Playbook: Validating PDF Structure
Forensic analysis began with validating PDF conformance across 4,085 files. Using specialized tools including the Arlington PDF Data Model, researchers assessed:
- File Structure: Only one minor validity flaw surfaced—109 files had incorrect FontDescriptor descent values—but no impact on document rendering.
- Version Inconsistencies: Tooling discrepancies highlighted PDF version reporting challenges. Header declarations (
%PDF-1.3) conflicted with catalog entries (PDF 1.5) due to incremental updates:
| Reported PDF Version | Tool A | Tool B |
|----------------------|--------|--------|
| 1.3 | 209 | 3,817 |
| 1.5 | 3,875 | 267 |
Tool A correctly accounted for incremental updates; Tool B did not—a stark reminder to never trust a single forensic tool.
Incremental Updates: The Hidden Layers
PDFs like EFTA00000001.pdf contained multiple revisions appended as incremental updates. These layers exposed operational workflows:
Bates Numbering Implementation: A final update injected page identifiers via a Helvetica font resource and content stream:
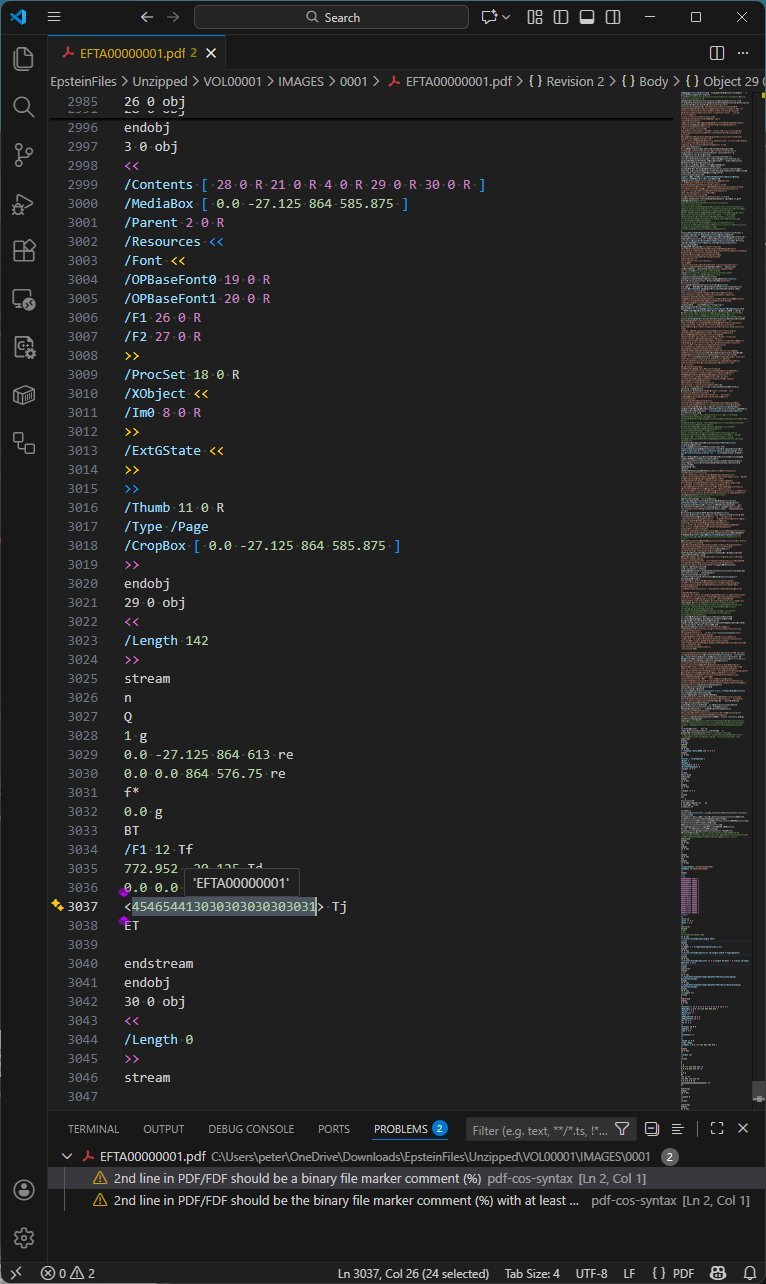 Visualization: Bates numbering added via incremental update (Source: PDF Association)
Visualization: Bates numbering added via incremental update (Source: PDF Association)Orphaned Metadata: Initial updates left hidden document info dictionaries containing creation software details (
OmniPage CSDK 21.1) unreferenced in final trailers—invisible to standard viewers but recoverable forensically.
Metadata and Image Sanitization: Hits and Misses
- Redaction Success: Black-box redactions were burned into pixel data, preventing text recovery. No XMP metadata or JavaScript was detected.
- Metadata Leaks: File
EFTA00003212.pdfretained a document info dictionary withTitle,Author, andCreatorfields—plus unresolved PDF comments.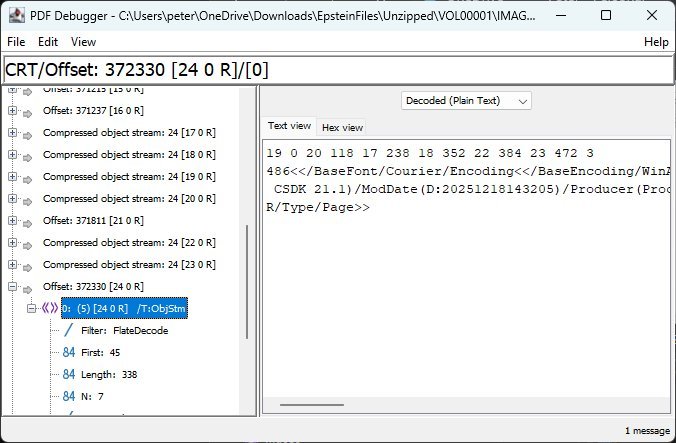 Debugger view exposing retained metadata (Source: PDF Association)
Debugger view exposing retained metadata (Source: PDF Association) - Image Processing: JPEG originals were converted to 96 DPI FLATE-encoded bitmaps with indexed color palettes, stripping EXIF/GPS data but reducing legibility.
OCR Limitations and "Scanned" Illusions
Optical Character Recognition (OCR) quality varied significantly. Handwritten notes in EFTA00000001.pdf showed poor accuracy, suggesting limited NLP/ML enhancement. Meanwhile, some "scanned" documents lacked physical artifacts (staples, paper texture), indicating digital-to-image conversion—not actual scanning.
"DoJ processes correctly redacted EFTA PDFs in Datasets 01-07. Claims of recoverable text are unfounded," the analysis emphasizes, contrasting these with past DoJ redaction failures.
The Bigger Picture: Sanitization Trade-Offs
While DoJ’s workflow removed sensitive content effectively, forensic traces remained: orphaned objects, inefficient file structures, and residual comments. Optimizations like removing empty streams, compressing updates, and purging comments could reduce file sizes and attack surfaces. This case underscores a universal truth: PDF sanitization requires threat modeling beyond surface-level redaction—demanding scrutiny of incremental updates, compressed objects, and metadata layers. As legal disclosures proliferate, robust document hygiene becomes non-negotiable for governments and enterprises alike.
Source: Technical analysis by Peter Wyatt, PDF Association
Comments
Please log in or register to join the discussion