
A developer retests top coding LLMs after 12 months to evaluate progress in generating complex Swift/SwiftUI applications. While frontier models show significant improvement in handling audio synthesis and UI integration, fundamental reliability issues and outdated coding patterns persist across the board.
Twelve months ago, developers witnessed coding Large Language Models (LLMs) like GitHub Copilot struggle with basic Swift/SwiftUI application development – requiring manual rewrites of nearly every generated line. Now, a new stress test evaluates whether today's models can deliver on the promise of "vibe coding" for non-trivial macOS applications combining SwiftUI, AVFoundation, and Swift Charts.
The Challenge: Raindrop Synthesis App
The test application requires:
- Real-time rain sound synthesis using AVAudioSourceNode
- Parametric controls for raindrop characteristics with randomized variations
- Dynamic waveform visualization via Swift Charts
- Background noise generators (pink/brown/white noise)
- UI with interactive sliders

Frontier Model Showdown
GPT-4o: Regression Alert (2/10)
The same model tested last year generated 383 lines across 5 files riddled with 21 errors. Critical audio rendering functions were placeholders, noise generators were structurally flawed, and Swift Charts integration was broken. "Hours of cleanup would be needed," the developer noted.
GPT-5.2: Functional But Flawed (7/10)
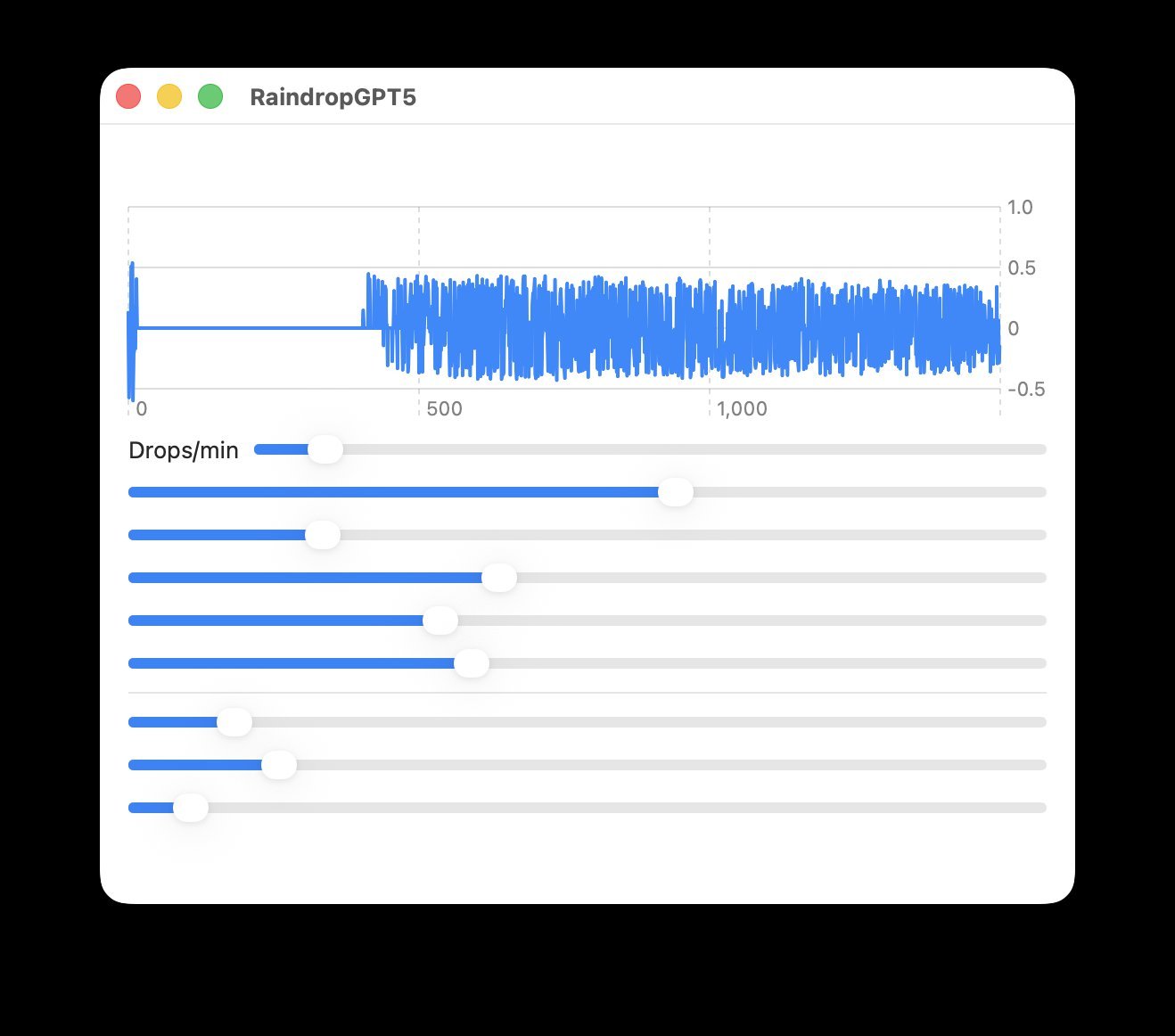
While generating a coherent architecture overview, the implementation suffered from audio buffer handling errors requiring manual memory management fixes. The UI lacked labels and exhibited severe performance issues due to excessive Chart view updates. "A nuisance of a compile bug" masked otherwise operational audio synthesis.
Gemini 3: Surprisingly Efficient (8/10)
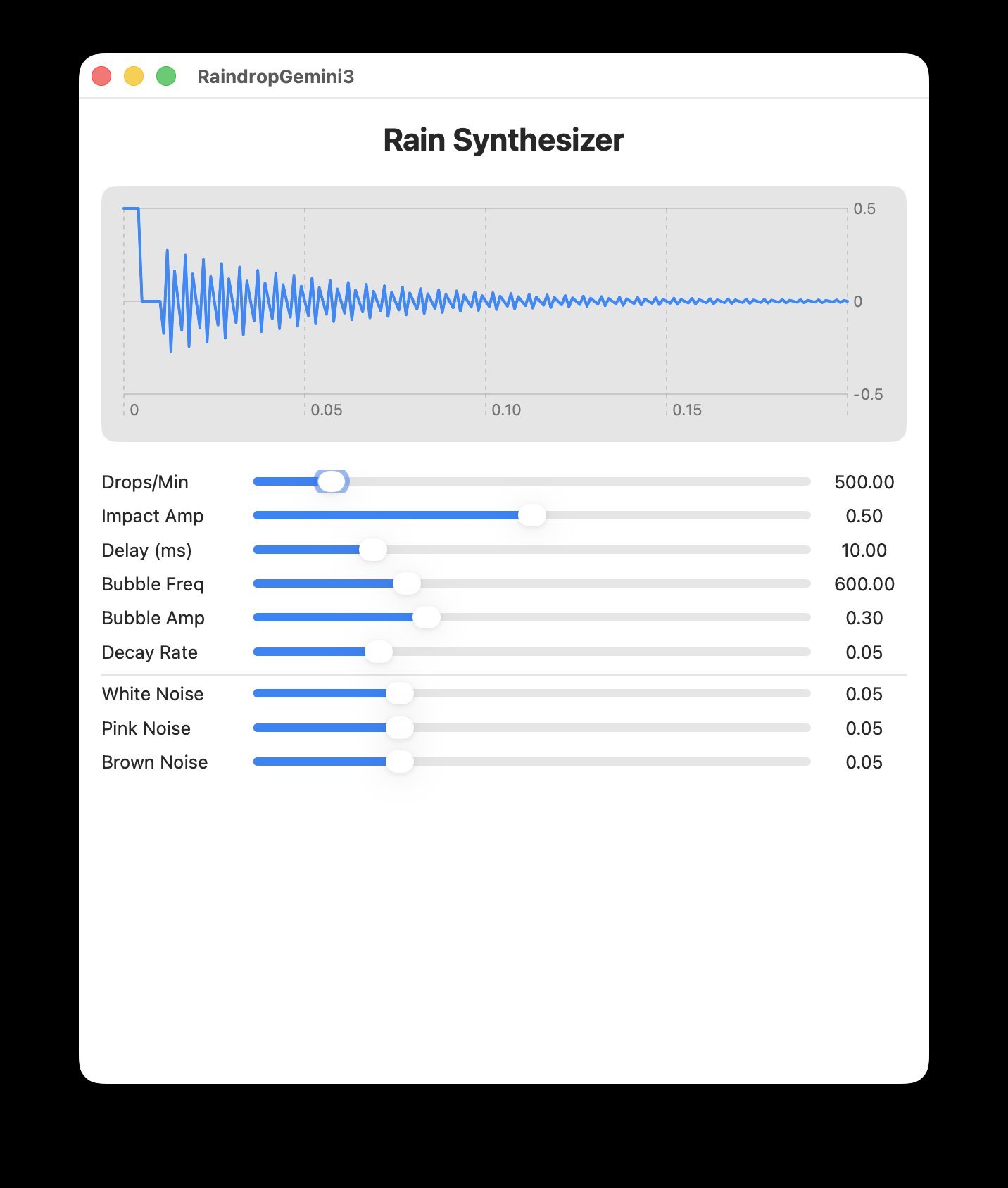
Gemini's concise 227-line implementation contained only one syntax error (easily fixed) and delivered fully functional audio with properly labeled controls. Though the UI sizing was overly aggressive, it outperformed GPT-5.2 in both correctness and runtime efficiency.
Claude 4.5: Current Leader (9/10)
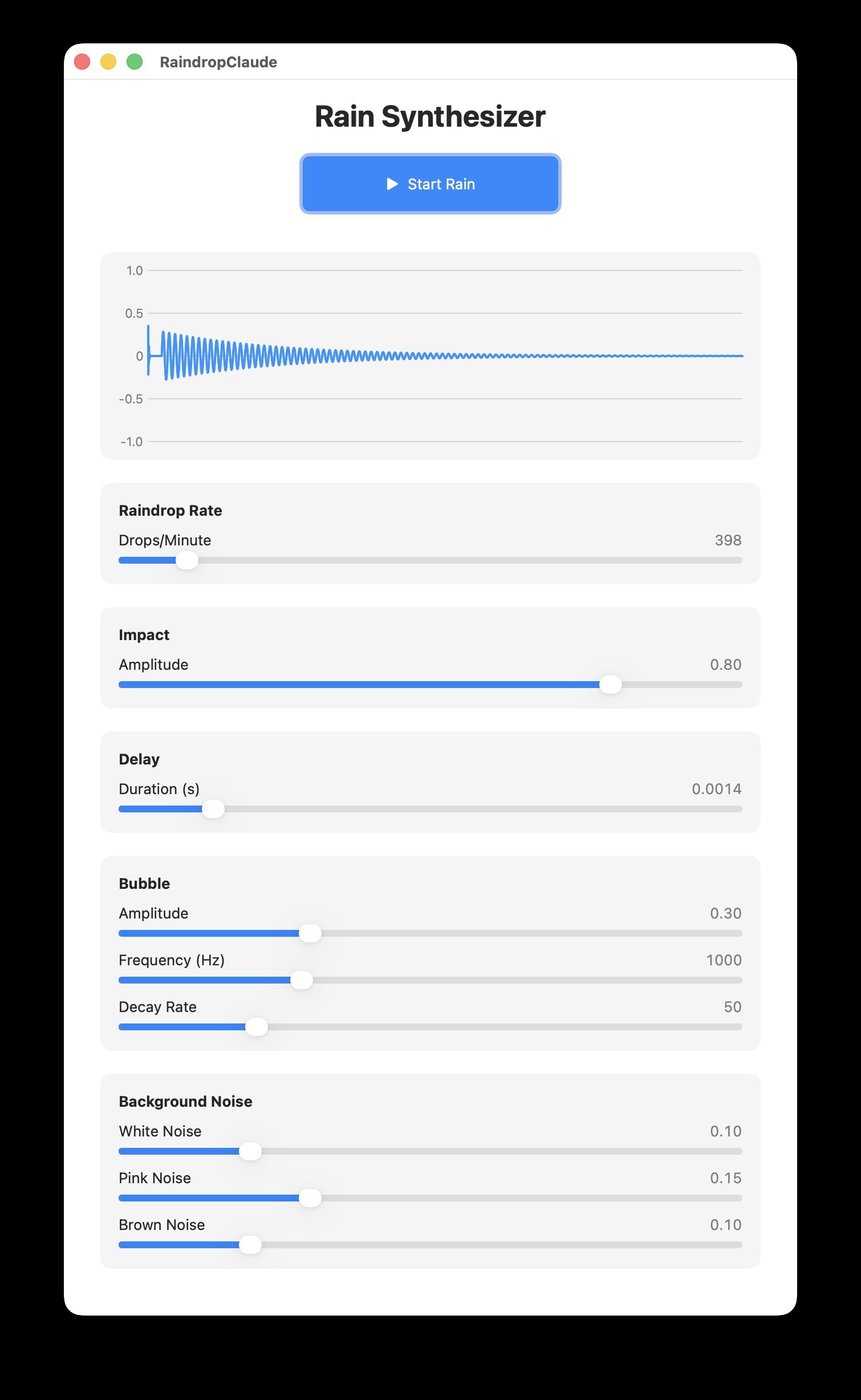
The most verbose solution (445 lines) included thoughtful additions like a Start/Stop button – though it failed to stop background noise generators. While the UI didn't fit standard displays and used outdated concurrency patterns, it represented the most complete implementation requiring only minor fixes.
Local LLMs: Not Ready for Primetime
Models like Qwen3-Coder-30B and GPT-OSS-20B struggled with fundamental Swift concepts:
- Stack corruption crashes due to timing calculation errors
- iOS-specific APIs in macOS contexts
- Misunderstanding of real-time audio rendering constraints
- Swift Charts integration failures
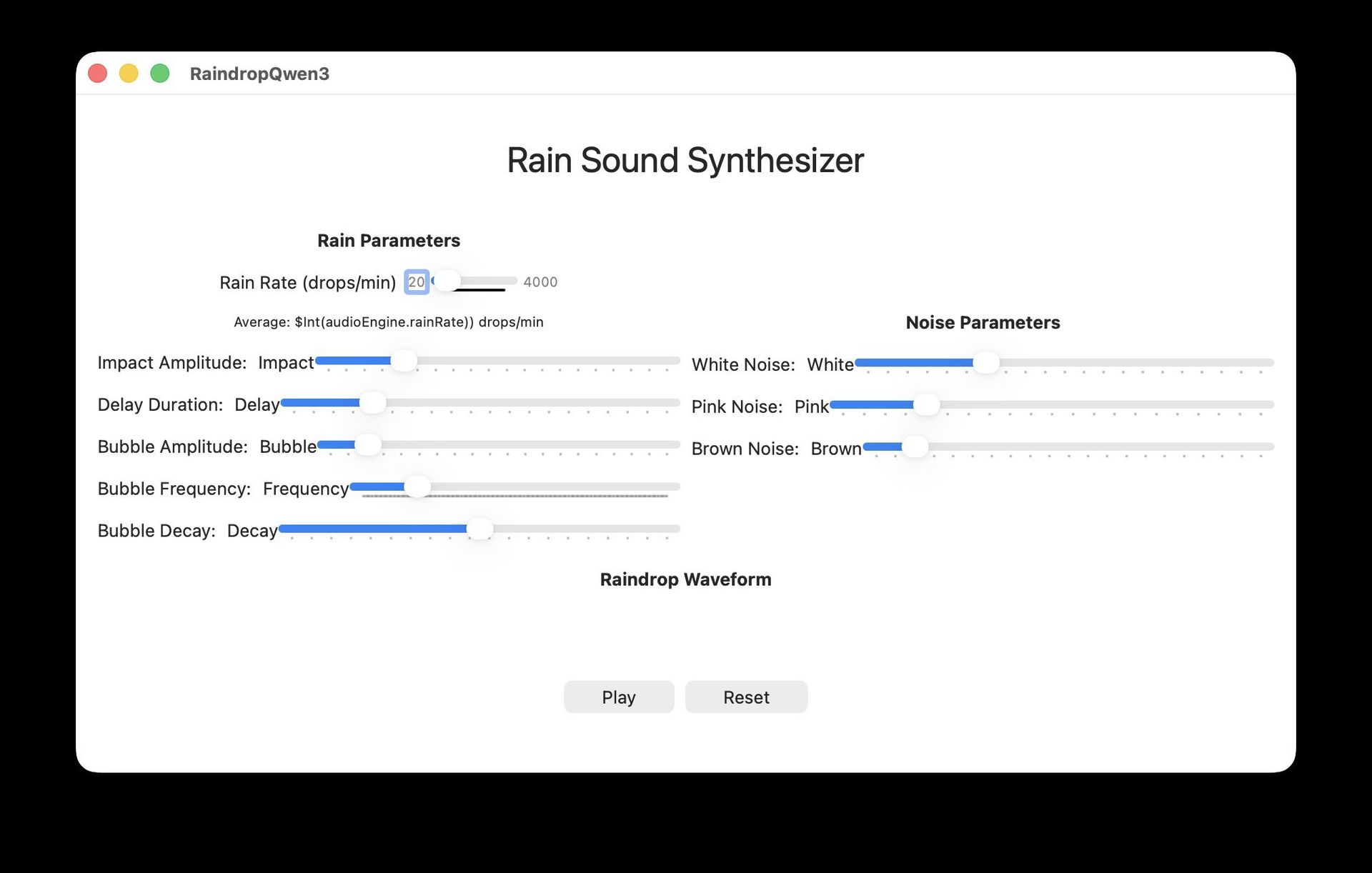
Even the best local model (GPT-OSS-20B) scored just 6/10 after extensive fixes, while others were "not even usable as a starting point."
Critical Limitations Persist
Across all models, consistent issues emerged:
- Outdated Swift Practices: Models defaulted to ObservableObject instead of Observable, ignored modern concurrency (async/await), and used deprecated dispatch methods
- API Blind Spots: Zero awareness of Swift 6 or recent iOS/macOS features
- Non-Determinism: Changing minor prompt wording yielded drastically different (and often broken) results
- Audio Engineering Gaps: Fundamental misunderstandings of AVAudioEngine's real-time constraints
The Verdict: Progress Without Parity
While frontier models now generate working applications from single prompts (unthinkable 12 months ago), they remain unreliable production partners. The inconsistency across runs, outdated coding patterns, and fundamental audio engineering errors mean developers still spend significant time debugging rather than creating. As the tester concluded: "For any prompt, you're rolling dice to see if you get a good job that might help you move forward or a complete mess."
Source: Cocoa with Love
Comments
Please log in or register to join the discussion