
Amidst claims that Model Context Protocol (MCP) servers will revolutionize observability, a critical analysis reveals significant limitations. Citing LLM hallucinations, combinatorial reasoning flaws, and studies from MIT and chaos engineering experiments, this piece argues MCP serves best as a hypothesis generator—not an autonomous problem-solver. Human oversight remains indispensable in high-stakes incident response.

The blogosphere recently buzzed with claims that Model Context Protocol (MCP) servers would trigger "the end of observability as we know it." As an engineer who implemented MCP for SigNoz, I argue this perspective overlooks fundamental limitations of current AI systems. Let's dissect why MCP—while useful—isn't the autonomous observability panacea some suggest.
MCP Demystified: The USB-C for AI Agents
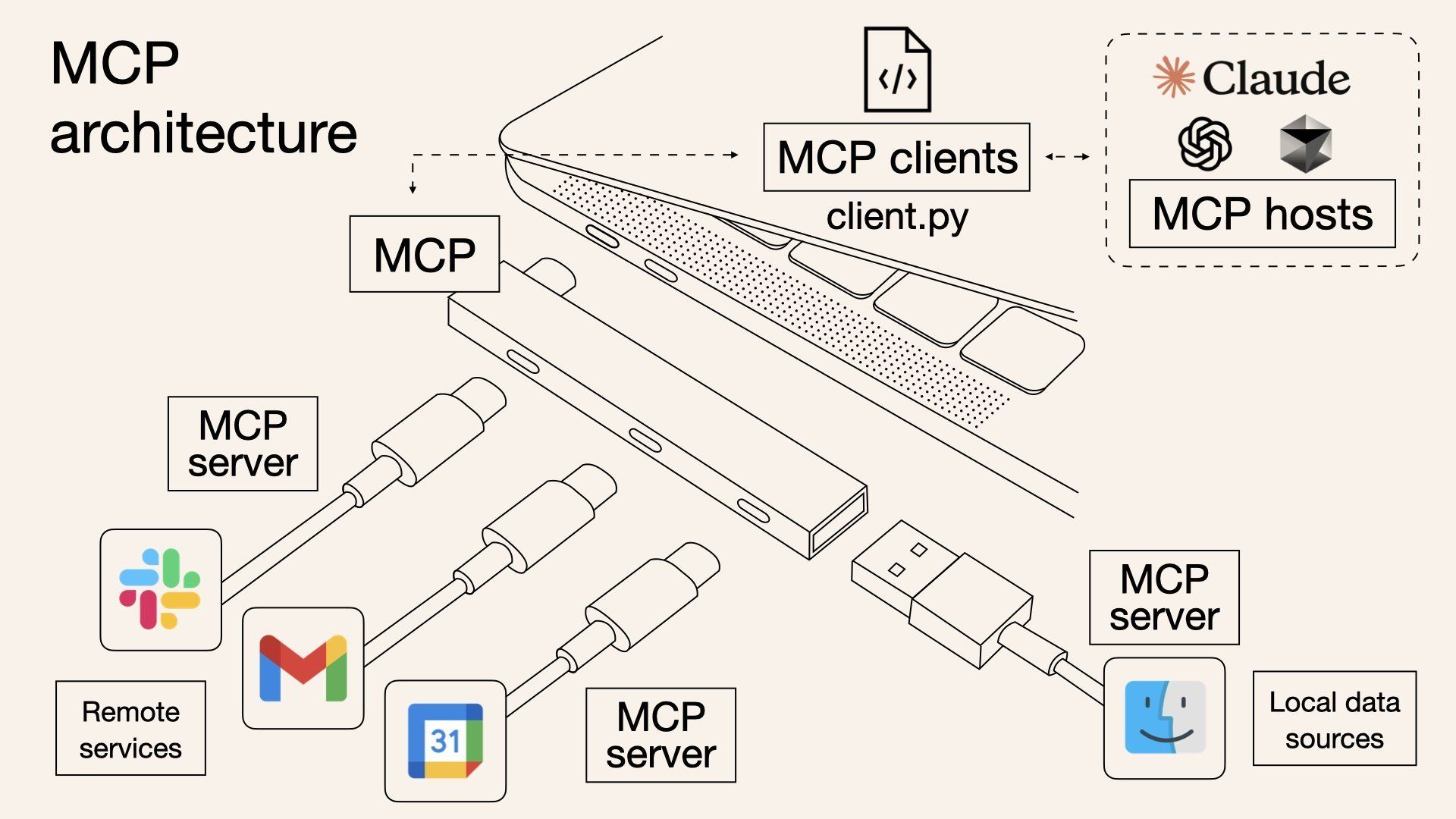
Developed by Anthropic, MCP is an open standard enabling Large Language Models (LLMs) like Claude to interface with external tools and data through a uniform protocol. Think of it as USB-C for AI: Build one MCP server, and any compatible agent can plug into your observability stack. It decouples tooling from models, streamlining integration. For example, an engineer could ask an agent: "Why did cart_service memory spike?" The agent then uses MCP to query metrics, logs, and traces, returning hypotheses.
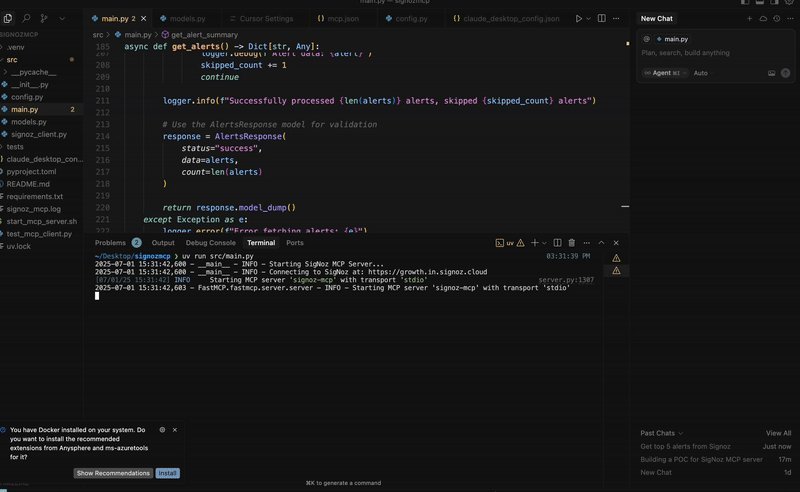 A basic MCP server demo for SigNoz. (Source: SigNoz Blog)
A basic MCP server demo for SigNoz. (Source: SigNoz Blog)
The NP-Hard Reality of Root Cause Analysis
Observability's holy grail—automated root cause analysis (RCA)—faces a fundamental challenge: RCA resembles an NP problem in computational complexity. While verifying a solution might be straightforward (P), finding the solution isn't. MCP agents generate hypotheses well, but verification often demands manual effort comparable to traditional troubleshooting. Consider findings from the paper "AIOps for Reliability":
- LLMs achieved just 44-58% RCA accuracy in zero-shot chaos engineering tests
- Few-shot prompting improved results to 60-74%—still below human SREs (>80%)
- Models frequently misattributed issues (e.g., labeling load spikes as security threats)
"While LLMs can identify common failure patterns, their accuracy is highly dependent on prompt engineering... LLMs are not yet ready to replace human SREs."
— AIOps for Reliability, 2024
Hallucinations and the Combinatorial Explosion Problem
LLMs' tendency to hallucinate with misplaced confidence poses severe risks in incident response. An agent might assert "cache miss storms caused the outage" based on plausible-but-wrong reasoning, sending engineers down rabbit holes. This worsens in MCP's tool-chaining environment:
- Each agent step (~3 possible interpretations) multiplies error risk
- With 8 tool calls, reasoning paths explode to 3⁷ (2,187) possibilities
- One misstep derails the entire analysis
An MIT study underscores this fragility. When an NYC-navigation LLM faced unexpected road closures, its performance collapsed—proving it lacked an internal world model, only pattern-matching training data. Similarly, MCP agents might recognize known failure modes but crumble when encountering novel cascades or deployment changes.
The Co-Pilot Imperative
MCP excels at well-defined tasks like translating natural language to PromQL—where outputs are structured and training data abounds. However, positioning it as an "observability killer" ignores critical realities:
- Verification overhead negates time savings in complex incidents
- Hallucinations require veteran oversight to detect
- Dynamic systems outpace static training data
We're not building autonomous SREs; we're engineering co-pilots. MCP agents accelerate hypothesis generation but can't replace human intuition for the unknown. As one engineer bluntly notes: "During an escalation, debugging prompts to fix your LLM’s reasoning is the last thing you need."
The future lies in balanced collaboration: Let MCP handle routine queries and brainstorming, while engineers focus on validation and novel scenarios. This synergy—not automation—will define observability's next chapter.
Comments
Please log in or register to join the discussion