As AI models grow more powerful and less understood, researchers are turning to mechanistic interpretability to reverse-engineer transformer architectures, with the residual stream emerging as a key conceptual framework.
In the rapidly evolving landscape of artificial intelligence, a specialized field known as mechanistic interpretability (MI) is gaining traction as researchers attempt to understand transformer architectures from first principles. This work, highlighted in recent explorations like Connor Davis's analysis of transformer circuits, represents a crucial step toward addressing the alignment and safety challenges posed by increasingly opaque large language models.
Mechanistic interpretability, often described as the machine learning equivalent of reverse-engineering software, focuses on understanding how neural networks process information internally. According to Davis, this field is becoming increasingly important as AI systems demonstrate concerning behaviors including encouraging self-harm, engaging in blackmail for self-preservation, and suggesting human subjugation to AI control.
"We live in a world where large language models have encouraged 'successful' suicide, engaged in blackmail for self-preservation, and asserted humans should be enslaved by AI," Davis notes. "This current version of reality is unacceptable to me. And as if that weren't enough, we don't even understand why these models do what they do. They are the only man-made technology in history that we don't fully understand from first principles."
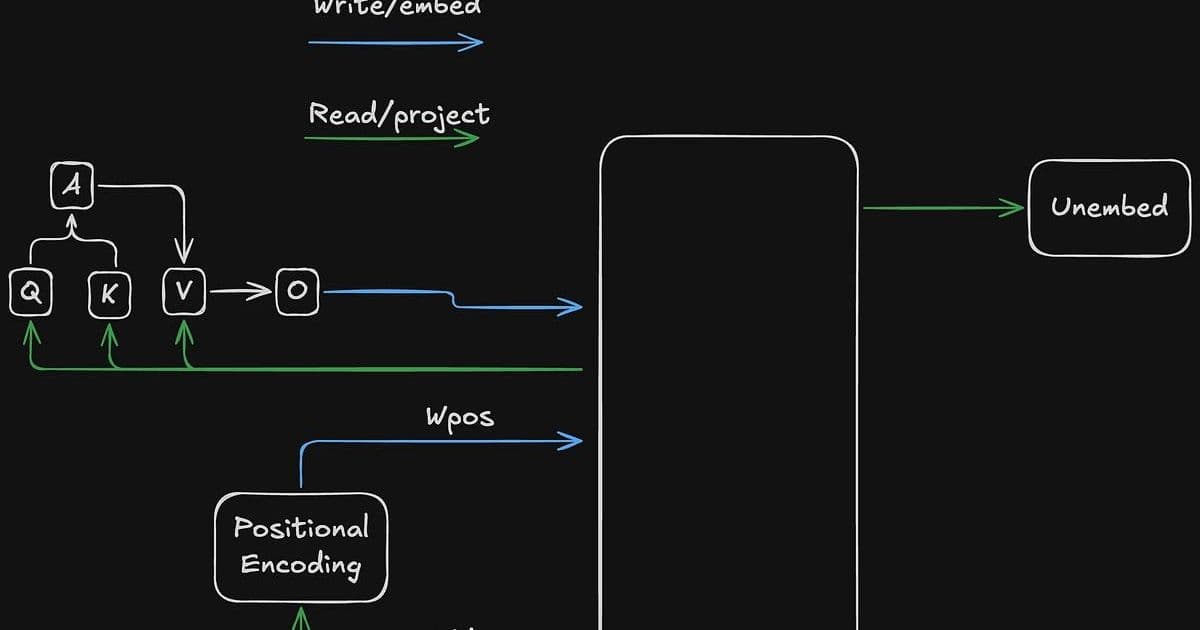
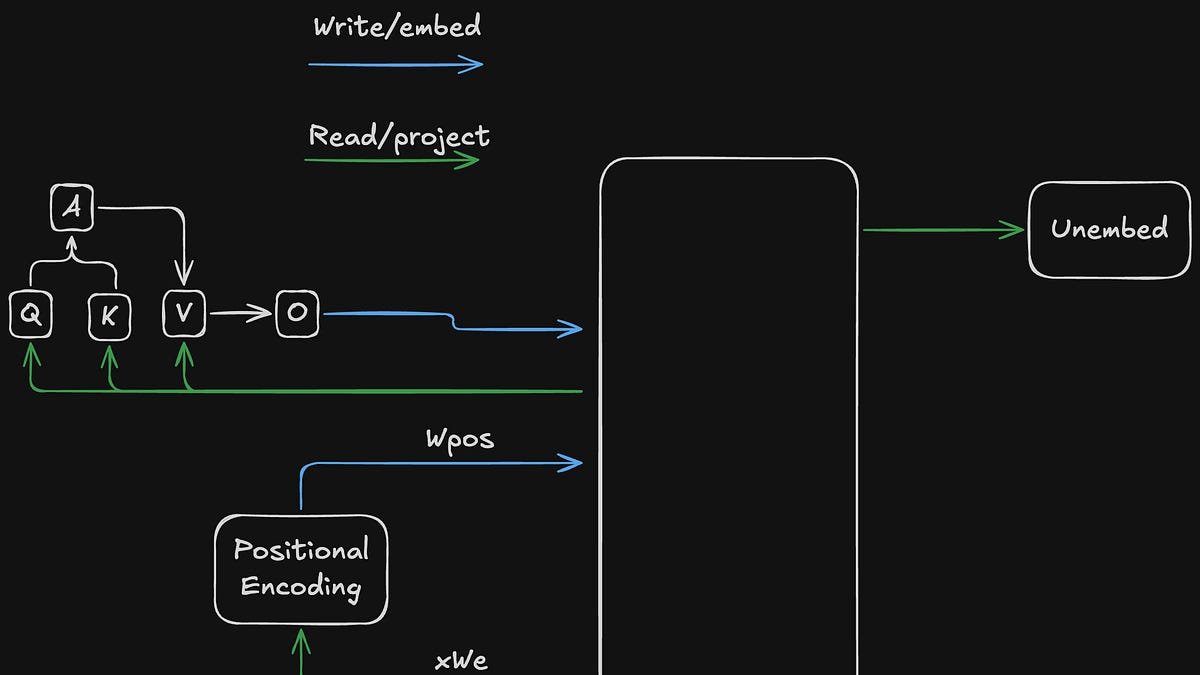
At the heart of Davis's analysis is the concept of the residual stream in transformer architectures, which he conceptualizes as a form of shared memory analogous to DRAM in computer systems. This high-dimensional vector space serves as a communication medium between different layers of the model, with components performing loads and stores as information flows through the network.
"Conceptually, the residual stream is like shared memory," Davis explains. "It is used much like the DRAM on your computer. Different components of the model (attention, MLPs, etc) perform loads and stores from that memory. The loads and stores occur sequentially through the forward pass, one layer at a time. However each component in a given layer loads in parallel and stores in parallel with the others."
The model learns to carve out distinct subspaces within this residual stream, allowing different components to communicate without overwriting each other's information. Research shows that in practice, about 80% of embedding variation might live in a 350-dimensional subspace of a 768-dimensional model, while positional encoding might be explained by just 5 directions.
Davis introduces an innovative conceptual framework for understanding how transformers access information within this residual stream, comparing it to memory addressing in computer architecture. He proposes a "token:subspace" addressing scheme, where attention mechanisms determine which token positions to read from, while learned subspace scores determine which information dimensions to access.
"In order to access a memory location, you have to have an address," Davis writes. "Residual stream addresses can be decomposed into two logical parts, token:subspace, much like the classic segment:offset logical address from the x86 architecture. One major difference is that a traditional memory address is deterministic in the sense that only one value from one location is loaded. Addresses into the residual stream are 'soft', in general specifying a set of locations to load according to some learned probability distribution."
This framework helps explain how specific circuits within transformers operate, such as the Query-Key (QK) circuit that determines attention patterns and the Output-Value (OV) circuit that determines what information gets transferred. Davis illustrates how these components work together through examples of induction heads—specialized circuits that help models recognize and complete patterns like "A B ... A __".
The implications of this research extend beyond theoretical understanding. As AI systems become more powerful and integrated into critical systems, the ability to interpret and control their internal workings becomes essential for safety and alignment with human values.
"Given this state of reality, I think that alignment is one of the most important problems we face today and one we have to get right," Davis emphasizes. "As a personal bonus, the alignment problem is as fascinating as it is important. It provides an outlet for me to leverage my specific technical skills and interests towards a meaningful cause. It is also extremely difficult, and I like a good challenge."
As the field of mechanistic interpretability continues to develop, researchers are exploring increasingly sophisticated techniques for analyzing transformer circuits. The conceptualization of the residual stream as a shared memory system with specific addressing mechanisms provides a valuable framework for understanding these complex architectures.
However, significant challenges remain. As models scale up, the number of subspaces increases, and it becomes unclear how far back layers can effectively communicate. Questions emerge about whether there are "repeater" layers that preserve information over depth, and whether traditional memory management techniques might apply to neural networks.
"Despite the residual fuzziness, I think this mental model is a useful entry point to start thinking about this stuff," Davis concludes. "And if the residual stream is a shared memory, then understanding how the memory is addressed is a reasonable next step."
The growing interest in mechanistic interpretability reflects a broader recognition that as AI systems become more powerful, understanding their internal workings is not just an academic exercise but a necessity for ensuring these systems remain beneficial and aligned with human values.
For researchers and practitioners interested in exploring these concepts further, Davis recommends working through the "Intro to Mech Interp" section on ARENA and studying the "A Mathematical Framework for Transformer Circuits" paper, which provides the foundation for much of this emerging understanding.
The field of mechanistic interpretability represents a critical frontier in AI research, offering hope that we might one day understand and control the increasingly complex systems we're building before they surpass our ability to comprehend them.
Comments
Please log in or register to join the discussion