
Mistral AI unveils Voxtral Transcribe 2 with sub-200ms latency for real-time applications, offering industry-leading accuracy at unprecedented prices across 13 languages.
Mistral AI is making waves in the speech-to-text landscape with the launch of Voxtral Transcribe 2, a family of next-generation models that promise to transform how developers build voice applications. The new lineup includes Voxtral Mini Transcribe V2 for batch processing and Voxtral Realtime for live transcription, both engineered to deliver exceptional accuracy at prices that undercut the competition by significant margins.
At the heart of this release is Voxtral Realtime, a model purpose-built for applications where latency isn't just a feature—it's the entire value proposition. Unlike traditional approaches that adapt offline models by processing audio in chunks, Realtime employs a novel streaming architecture that transcribes as audio arrives. This architectural choice enables configurable delays down to sub-200ms, opening up possibilities for voice agents and real-time applications that simply weren't feasible before.
The performance metrics are compelling. At 2.4 seconds delay—ideal for subtitling—Realtime matches the accuracy of Voxtral Mini Transcribe V2, Mistral's latest batch model. Push the latency down to 480ms, and the model maintains word error rates within 1-2% of offline accuracy, enabling voice agents that feel natural and responsive. This is the kind of performance that transforms conversational AI from clunky to conversational.
Natively multilingual, Voxtral Realtime achieves strong transcription performance across 13 languages including English, Chinese, Hindi, Spanish, Arabic, French, Portuguese, Russian, German, Japanese, Korean, Italian, and Dutch. With a 4B parameter footprint, it runs efficiently on edge devices, making it suitable for privacy-first applications where data never leaves the device.
Perhaps most significantly for the open-source community, Mistral is releasing Voxtral Realtime under the Apache 2.0 license on Hugging Face. This move democratizes access to cutting-edge speech technology, allowing developers to deploy the model on-premises or on edge devices without the constraints of proprietary APIs.
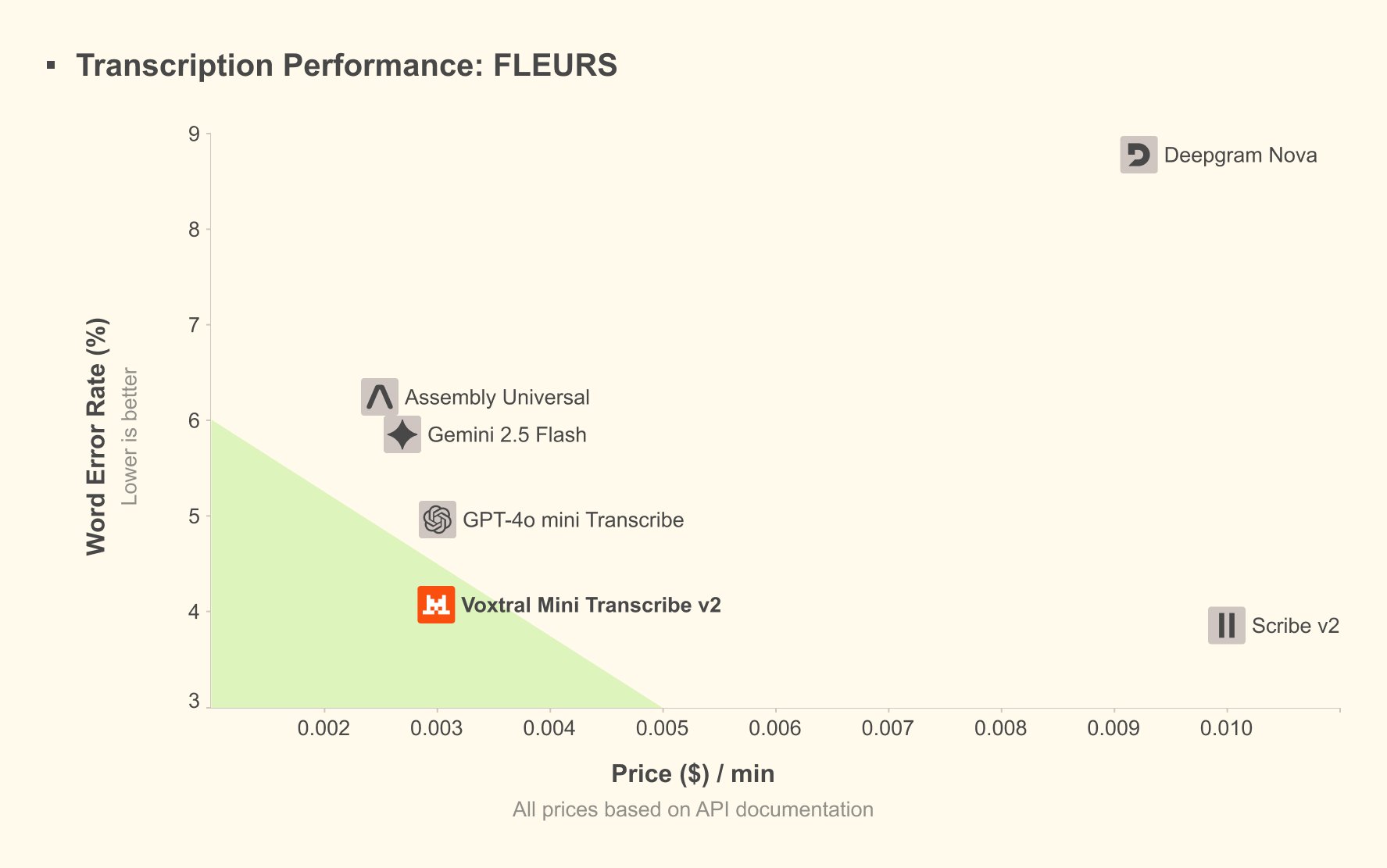
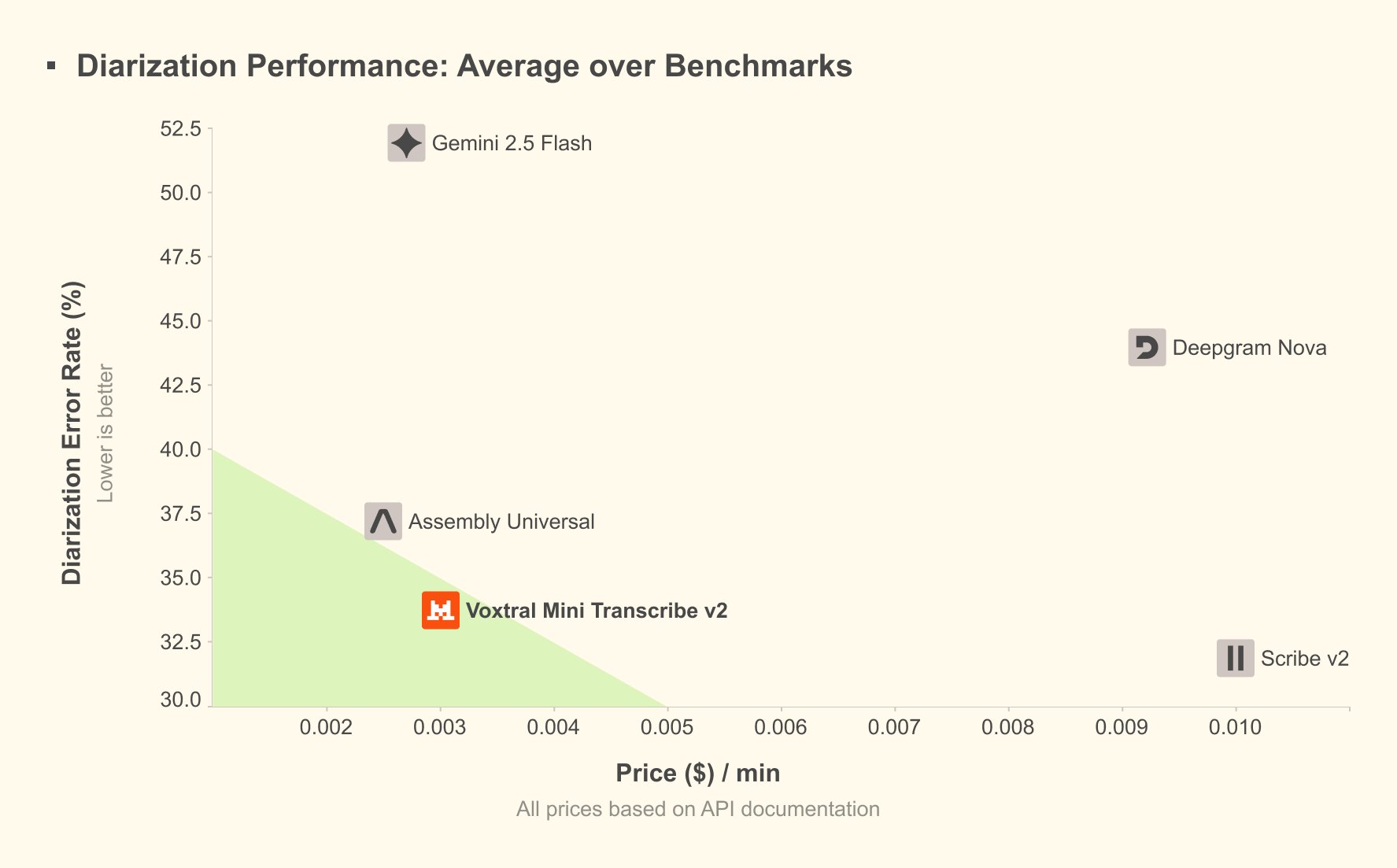
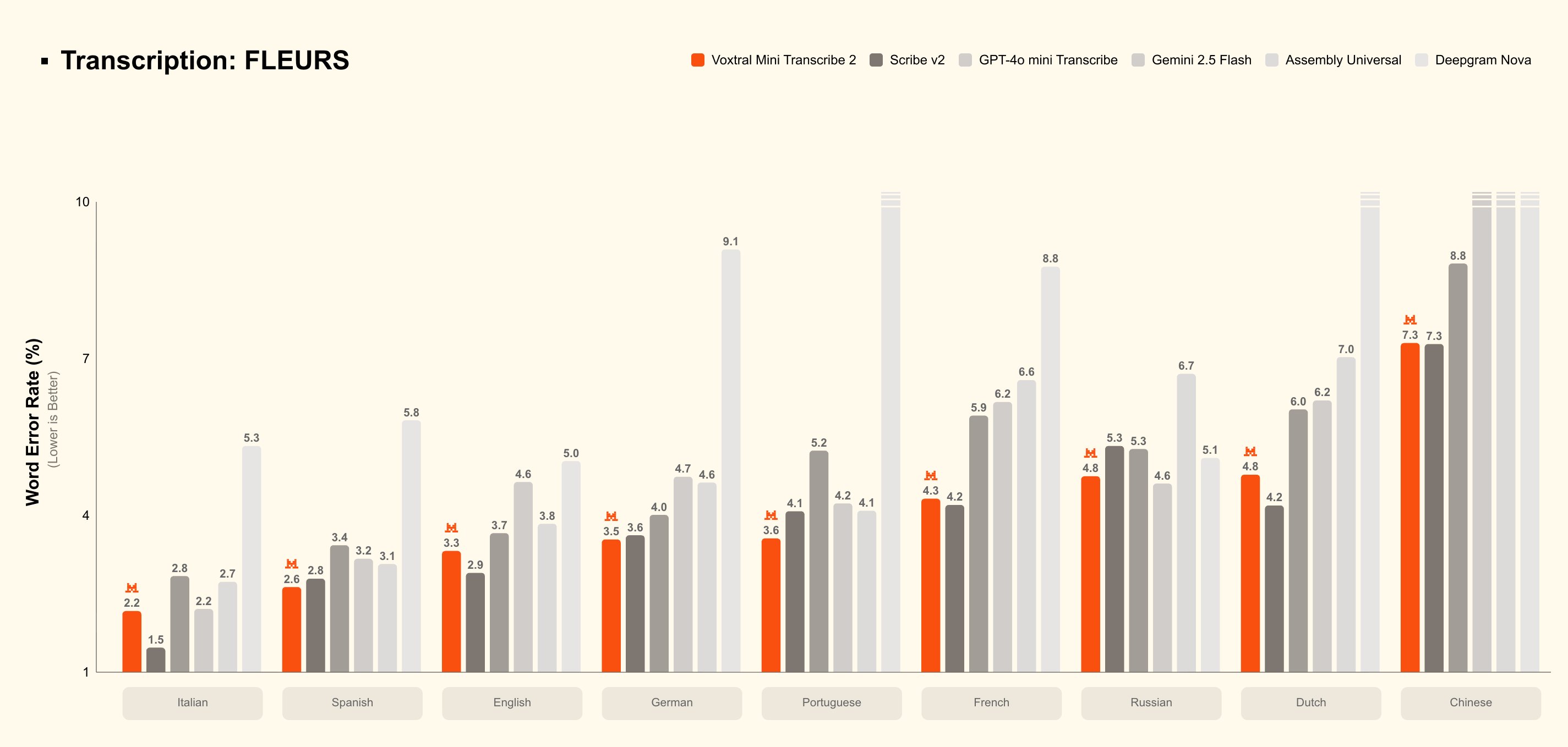
Voxtral Mini Transcribe V2, the batch counterpart, delivers its own impressive achievements. The model achieves approximately 4% word error rate on the FLEURS benchmark while charging just $0.003 per minute—a price point that makes large-scale transcription economically viable for the first time. In head-to-head comparisons, Voxtral outperforms GPT-4o mini Transcribe, Gemini 2.5 Flash, Assembly Universal, and Deepgram Nova on accuracy while processing audio approximately 3x faster than ElevenLabs' Scribe v2 at one-fifth the cost.
The enterprise features built into Voxtral Mini Transcribe V2 address real-world deployment challenges. Speaker diarization generates transcriptions with speaker labels and precise start/end times, essential for meeting transcription, interview analysis, and multi-party call processing. Context biasing allows up to 100 words or phrases to guide the model toward correct spellings of names, technical terms, or domain-specific vocabulary—particularly valuable for proper nouns that standard models often miss. Word-level timestamps enable applications like subtitle generation, audio search, and content alignment with millisecond precision.
Noise robustness ensures the model maintains accuracy in challenging acoustic environments like factory floors, busy call centers, and field recordings. The ability to process recordings up to 3 hours in a single request eliminates the need for complex audio segmentation in many use cases.
To showcase these capabilities, Mistral has launched an audio playground in Mistral Studio where developers can test Voxtral Transcribe 2 directly. The playground supports uploading up to 10 audio files in formats including .mp3, .wav, .m4a, .flac, and .ogg (up to 1GB each), with toggles for diarization, timestamp granularity, and context bias terms for domain-specific vocabulary.
The applications enabled by Voxtral span industries and use cases. Meeting intelligence platforms can now transcribe multilingual recordings with speaker diarization that clearly attributes who said what and when, at price points that make annotating large volumes of meeting content economically viable. Voice agents and virtual assistants built with Voxtral Realtime can achieve sub-200ms transcription latency, creating conversational AI that feels natural rather than robotic. Contact centers can transcribe calls in real time, enabling AI systems to analyze sentiment, suggest responses, and populate CRM fields while conversations are still happening.
Media and broadcast companies can generate live multilingual subtitles with minimal latency, while context biasing handles the proper nouns and technical terminology that trip up generic transcription services. Compliance and documentation workflows benefit from clear speaker attribution and precise timestamps that enable audit trails.
Both models support GDPR and HIPAA-compliant deployments through secure on-premise or private cloud setups, addressing the stringent requirements of regulated industries.
Availability is immediate: Voxtral Mini Transcribe V2 is accessible via API at $0.003 per minute and can be tested in the Mistral Studio audio playground or in Le Chat. Voxtral Realtime is available via API at $0.006 per minute and as open weights on Hugging Face for self-hosting.
This release represents more than just incremental improvement in speech-to-text technology. By combining sub-200ms latency with enterprise-grade features and unprecedented price-performance ratios, Mistral AI is lowering the barrier to entry for sophisticated voice applications. The open-source release of Voxtral Realtime in particular signals Mistral's commitment to democratizing access to frontier AI models, putting powerful speech technology into the hands of developers worldwide.
The next chapter of AI is increasingly voice-first, and with Voxtral Transcribe 2, Mistral AI has positioned itself at the forefront of this transformation.
Comments
Please log in or register to join the discussion