Datascale AI releases a comprehensive open-source book covering the entire data engineering pipeline for large language models, including pre-training, multimodal alignment, and RAG systems, accompanied by five practical projects.
"Data is the new oil, but only if you know how to refine it."
This opening statement from Datascale AI's newly released Data Engineering for Large Models book underscores a critical challenge in AI development. While large language models dominate headlines, systematic resources on the data engineering pipelines powering them remain scarce. Most teams rely on trial-and-error approaches when preparing training data—a gap this 13-chapter technical book aims to fill.
The book provides a complete technical roadmap spanning six key areas:
- Infrastructure & Core Concepts: Foundational principles including data-centric AI philosophy and infrastructure selection
- Text Pre-training Engineering: Techniques for extracting high-quality corpora from noisy sources like Common Crawl using Trafilatura, KenLM, and MinHash LSH
- Multimodal Processing: Alignment strategies for image-text pairs, video, and audio data using tools like CLIP and img2dataset
- Alignment & Synthetic Data: Automated generation of instruction data (SFT), human preference data (RLHF), and reasoning data (CoT)
- Application Engineering: Production-ready RAG pipelines for document parsing, semantic chunking, and multimodal retrieval
- Capstone Projects: Five end-to-end implementations with runnable code
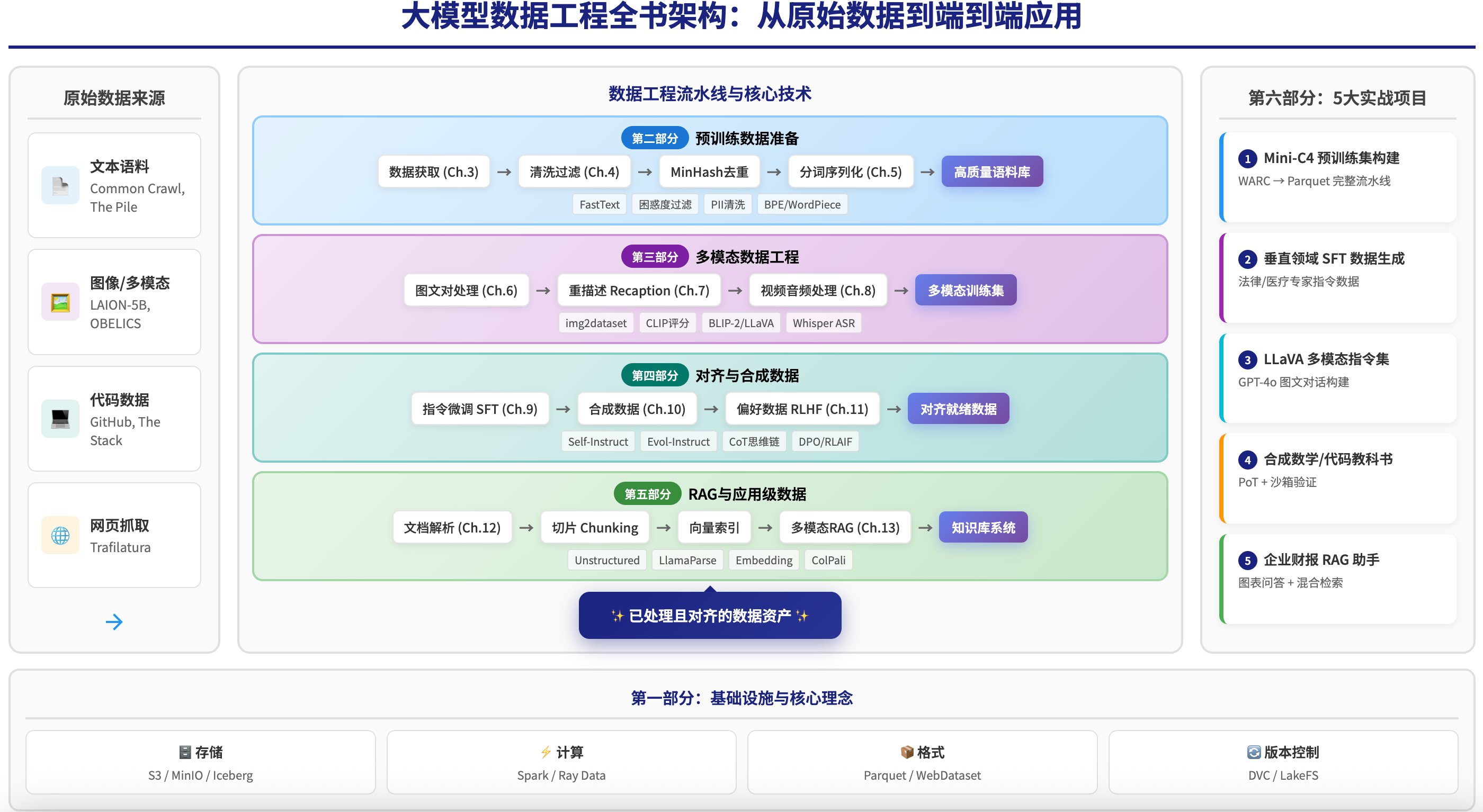
What sets this resource apart is its hands-on approach. The included projects demonstrate real-world implementations:
- Mini-C4 Pre-training Set: Building high-quality text corpora with Ray Data pipelines
- Legal Expert SFT: Domain-specific instruction tuning using Self-Instruct and Chain-of-Thought
- LLaVA Multimodal Dataset: Visual instruction tuning with bounding box alignment
- Synthetic Math Textbook: Generating problems-of-theory datasets with Evol-Instruct
- Financial RAG Assistant: Multimodal Q&A system combining ColPali and Qwen-VL
The technology stack reflects modern best practices including distributed processing (Ray Data, Spark), storage formats (Parquet, WebDataset), vector databases, and data versioning tools like DVC and LakeFS. Each section includes practical implementations—for example, demonstrating how MinHash LSH enables efficient deduplication at web-scale.
Available in English and Chinese, the book runs on MkDocs with live preview capabilities. Developers can clone the repository and run mkdocs serve for immediate local access.
As AI shifts focus from model architecture to data quality, this resource provides much-needed structure for what's traditionally been an ad-hoc process. With its combination of theoretical depth—covering everything from scaling laws to multimodal alignment—and executable projects, it offers tangible solutions for teams building production LLM systems.
Access the book:
Online Version | GitHub Repository
Comments
Please log in or register to join the discussion