Researchers propose Recursive Language Models (RLMs) that enable language models to recursively interact with unbounded context through REPL environments, achieving breakthrough performance on long-context benchmarks while avoiding degradation issues.
Recursive Language Models: A New Paradigm for Unbounded Context Processing
The Context Rot Problem
Language models face a well-known but poorly characterized phenomenon called "context rot" - as the number of tokens in the context window increases, the model's ability to accurately recall information from that context decreases. This isn't just about hitting context window limits; it's about degradation in performance even when the context fits within the model's window.
Researchers have observed this in everyday use cases: your Claude Code history gets bloated, or you chat with ChatGPT for a long time, and the model seems to get "dumber" as the conversation progresses. The natural intuition is that splitting the context into multiple model calls and combining them in a third call might avoid this degradation issue.
Introducing Recursive Language Models
Recursive Language Models (RLMs) are a general inference strategy where language models can decompose and recursively interact with their input context as a variable. The key insight is treating the prompt as a Python variable that can be processed programmatically in arbitrary REPL flows, allowing the LLM to figure out what to peek at from the long context at test time.
How RLMs Work
An RLM acts as a thin wrapper around a language model that can spawn recursive LM calls for intermediate computation. From the user's perspective, it's the same as a model call: rlm.completion(messages) is a direct replacement for gpt5.completion(messages).
Under the hood, the RLM provides only the query to the root language model (depth=0), which interacts with a Python REPL environment that stores the potentially huge context. The root model can call recursive LMs inside this REPL environment as if they were functions in code, allowing it to naturally peek at, partition, grep through, and launch recursive sub-queries over the context.
When the root model is confident it has an answer, it can either directly output the answer as FINAL(answer), or build up an answer using variables in its REPL environment and return the string inside that answer as FINAL_VAR(final_ans_var).
Breakthrough Results on Long-Context Benchmarks
OOLONG Benchmark: Double the Performance
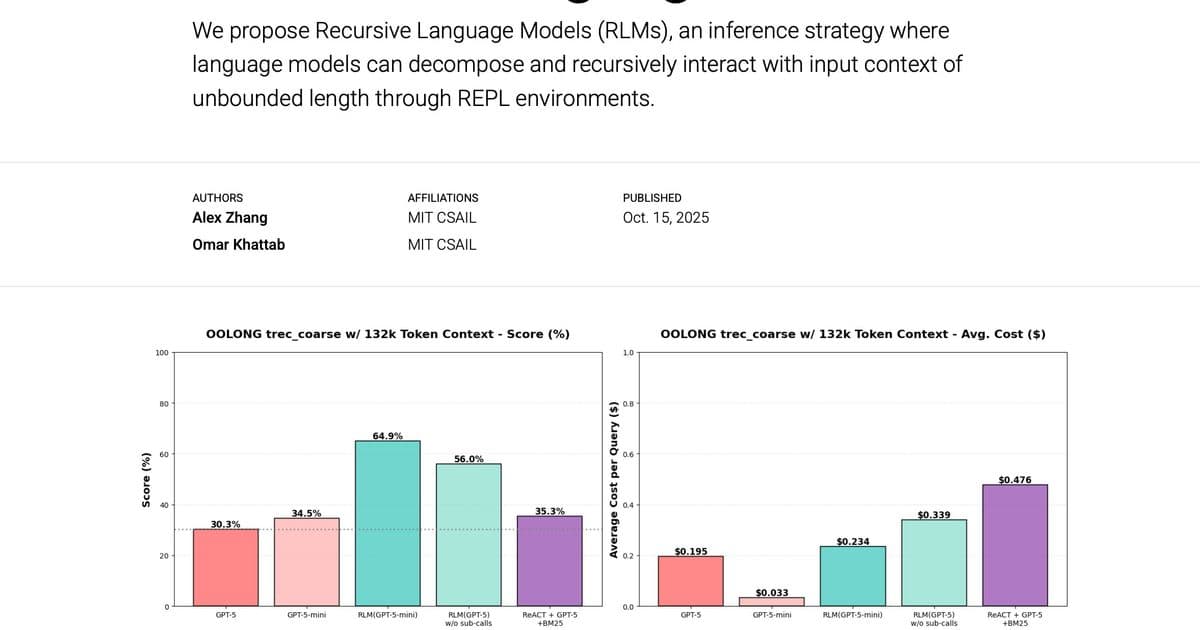
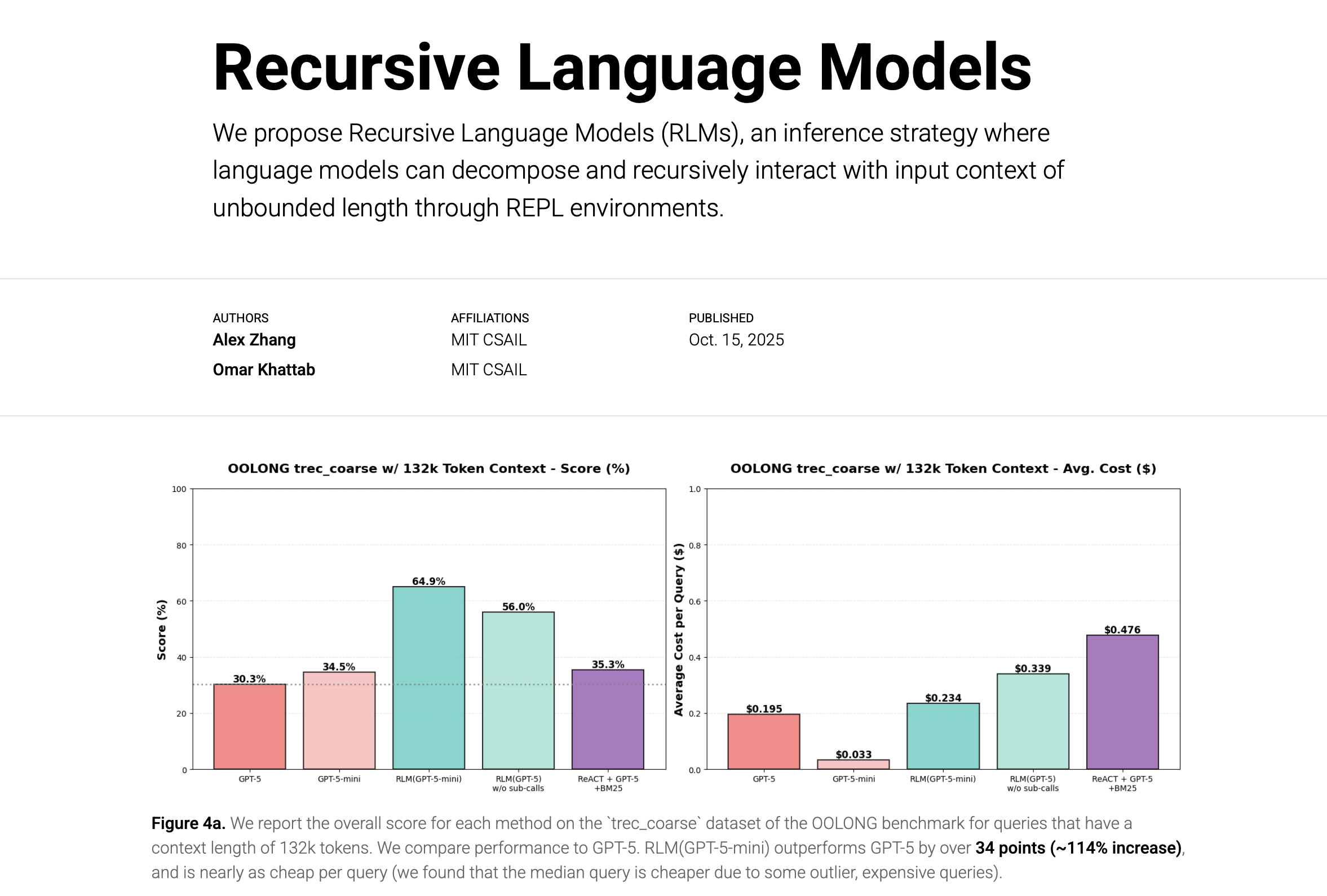
The OOLONG benchmark evaluates long-context reasoning tasks over fine-grained information. The trec_coarse split consists of distributional queries about giant lists of question entries, where models must semantically map and associate thousands of pieces of information in a single query.
Researchers compared several approaches:
- GPT-5 given the whole context and query
- GPT-5-mini given the whole context and query
- RLM(GPT-5-mini) where GPT-5-mini can recursively call itself inside REPL
- RLM(GPT-5) without sub-calls (ablation)
- ReAct with GPT-5 + BM25 retrieval
Results: RLM(GPT-5-mini) outperformed GPT-5 by over 34 points (~114% increase) while maintaining roughly the same total model API cost per query! When ablating recursion, performance degraded by ~10%, indicating the importance of recursive sub-queries for semantic mapping tasks.
Even with doubled context size (~263k tokens), RLM(GPT-5-mini) maintained a 49% performance advantage over GPT-5 while being cheaper per query on average.
BrowseComp-Plus: Perfect Performance at 1000 Documents
For evaluating ridiculously large contexts, researchers used BrowseComp-Plus, which provides ~100K documents where answers are scattered across the corpus. They tested performance with 10, 50, 100, and 1000 documents in context.
Results: RLM(GPT-5) was the only approach achieving and maintaining perfect performance at the 1000 document scale, with the non-recursive ablation achieving 90%. Base GPT-5 approaches showed clear performance dropoff as document count increased, while RLM maintained reasonable cost scaling.
What Makes RLMs Powerful
Key Design Choices
- Context as Variable: Treating the prompt as a Python variable that can be processed programmatically in arbitrary REPL flows
- Recursive Calls: Allowing the REPL environment to make calls back to the LLM (or smaller LLM), facilitated by the decomposition and versatility from choice 1
Strategies That Emerge
RLMs naturally develop several strategies for context interaction:
- Peeking: The root model grabs the first few thousand characters to observe structure
- Grepping: Using keyword or regex patterns to narrow down lines of interest
- Partition + Map: Chunking context and running recursive LM calls for semantic mapping
- Summarization: Summarizing subsets of context for outer model decisions
- Long-input, Long-output: Programmatically processing long sequences (e.g., git diff histories)
Relationship to Test-Time Scaling
RLMs offer another axis of scaling test-time compute. The trajectory in which a language model chooses to interact with and recurse over its context is entirely learnable and can be reinforcement learning-ified in the same way that reasoning is currently trained for frontier models.
Importantly, RLMs don't require training models that can handle huge context lengths because no single language model call should require handling a huge context.
Limitations and Future Work
Current limitations include:
- No optimization for speed - recursive calls are blocking and don't use prefix caching
- No strong guarantees about controlling total API cost or runtime
- Only tested with recursive depth of 1 (root model can only call LMs, not other RLMs)
Future work includes enabling larger recursive depth, optimizing inference engines for RLMs, and training models specifically to work in this recursive framework.
Why RLMs Matter
RLMs represent a fundamentally different bet than modern agents. Agents are designed based on human/expert intuition on how to break down problems for LMs. RLMs are designed based on the principle that LMs should decide how to break down problems to be digestible for themselves.
The performance of RLMs correlates directly with improvements to base model capabilities - if tomorrow's best frontier LM can handle 10M tokens, an RLM can reasonably handle 100M tokens (maybe at half the cost too).
As the researchers conclude: "I personally have no idea what will work in the end, but I'm excited to see where this idea goes!"
For more information, see the full paper and official codebase. A minimal implementation is also available for building upon: RLM Minimal.
Citation: @article{zhang2025rlm, title = "Recursive Language Models", author = "Zhang, Alex and Khattab, Omar", year = "2025", month = "October", url = "https://alexzhang13.github.io/blog/2025/rlm/" }
Comments
Please log in or register to join the discussion