A new GitHub project pits reinforcement learning algorithms against each other in a simulated car navigation task. Using PyBullet and Stable-Baselines3, SAC emerges as the clear winner in training efficiency and navigation success while A2C trails significantly behind.
In a compelling demonstration of reinforcement learning (RL) capabilities, a new open-source project leverages PyBullet's physics simulation to train virtual cars to autonomously navigate toward a target. The implementation compares three major algorithms—SAC (Soft Actor-Critic), PPO (Proximal Policy Optimization), and A2C (Advantage Actor-Critic)—revealing stark performance differences with real implications for robotics and autonomous system development.
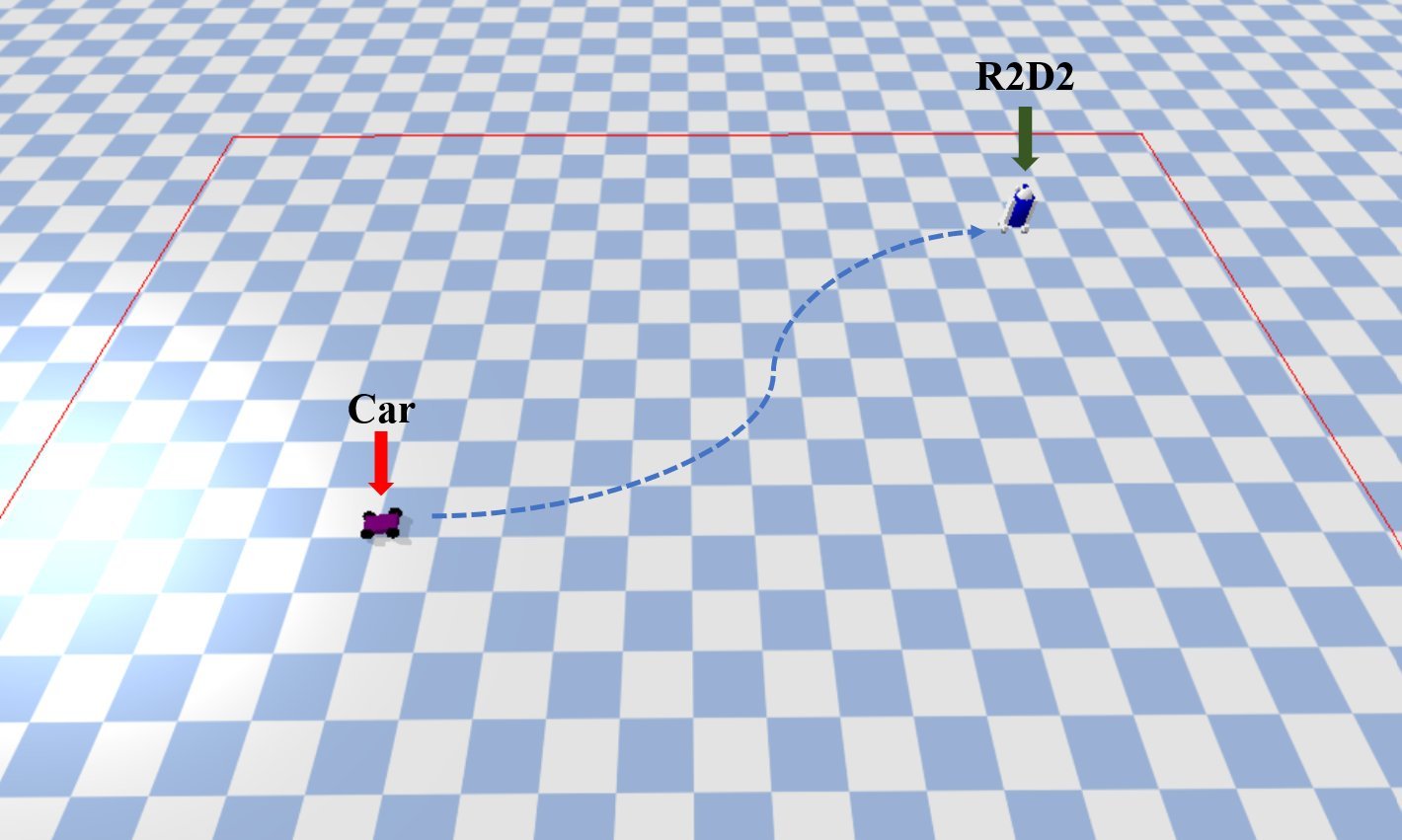 The car and R2D2 target in PyBullet's simulation environment (Source: GitHub/leesweqq)
The car and R2D2 target in PyBullet's simulation environment (Source: GitHub/leesweqq)
The Algorithm Arena
Using Stable-Baselines3, the project trains agents to control a car's acceleration, deceleration, and steering based on an observation space comprising:
- Car position (x, y coordinates)
- Orientation and velocity vectors
- Target (R2D2) position
The reward system incentivizes efficient navigation:
reward = distance_reduction + boundary_penalty + goal_bonus
Where boundary violations trigger episode termination, and reaching the target yields a significant bonus. This setup mirrors real-world autonomous navigation challenges where safety and precision are critical.
Training Insights and Performance Battle
During training, SAC demonstrated superior sample efficiency and stability. The reward comparison chart highlights its rapid convergence and higher cumulative rewards versus PPO and A2C:
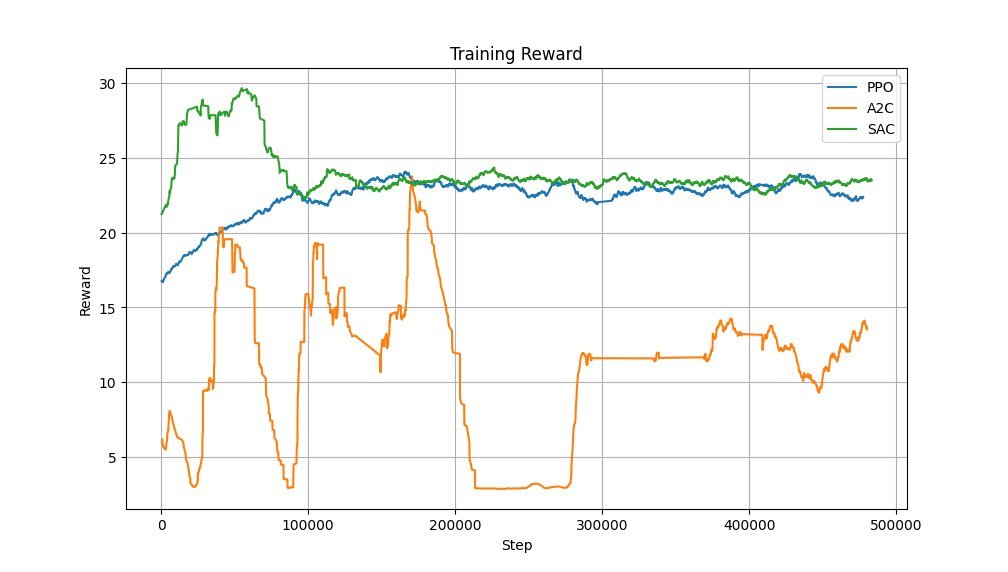 Reward accumulation during training (Source: GitHub/leesweqq)
Reward accumulation during training (Source: GitHub/leesweqq)
Key findings:
- SAC: Achieved consistent navigation success with the highest efficiency, leveraging its entropy-maximizing approach for better exploration.
- PPO: Showed stable learning but required more training steps to approach SAC's performance.
- A2C: Struggled with erratic behavior and low reward accumulation, highlighting sensitivity to hyperparameters in sparse-reward environments.
 Training progression: Car learns navigation (Source: GitHub/leesweqq)
Training progression: Car learns navigation (Source: GitHub/leesweqq)
Why This Matters for Developers
This benchmark offers practical insights for RL practitioners:
- Algorithm Selection: SAC’s superiority in continuous control tasks reinforces its utility in robotics.
- Sim-to-Real Potential: PyBullet’s physics engine provides a cost-effective testing ground for autonomous systems.
- Reward Engineering: The project demonstrates how distance-based rewards with penalties create effective learning signals.
 SAC algorithm successfully navigating to target during testing (Source: GitHub/leesweqq)
SAC algorithm successfully navigating to target during testing (Source: GitHub/leesweqq)
Getting Hands-On
The GitHub repository provides complete implementation:
pip install pybullet stable-baselines3 matplotlib numpy
python main.py
Developers can modify observation parameters, reward functions, or integrate new algorithms—an ideal sandbox for experimenting with RL fundamentals. As simulation-trained models increasingly bridge to physical systems, projects like this sharpen our understanding of what works (and what doesn’t) before deploying algorithms in the real world.
Comments
Please log in or register to join the discussion