Semble emerges as a breakthrough in code search technology, offering AI agents lightning-fast repository exploration with ~98% fewer tokens than traditional grep+read approaches. This deep analysis examines the technology, benchmarks, and implications for developer workflows in the age of AI-assisted coding.
The landscape of AI-assisted development is undergoing a quiet revolution. As coding agents become more sophisticated, their ability to efficiently navigate and understand codebases has become a critical bottleneck. Enter Semble, a new code search library that promises to fundamentally change how AI agents explore code. With claims of ~98% fewer token usage than traditional grep+read approaches and indexing speeds hundreds of times faster than transformer-based solutions, Semble represents a significant shift in the technical approach to code search.
The Problem with Current Code Search Approaches
AI coding assistants face a fundamental challenge when working with unfamiliar codebases. Traditional methods like grep require precise keyword matching, forcing agents to either guess at identifiers or read entire files to understand context. This approach leads to two major problems:
- Token inefficiency: Agents spend most of their context budget on irrelevant code, limiting their ability to process meaningful information
- Latency issues: Reading entire files or waiting for complex transformer models to process queries creates frustrating delays in the development workflow
The alternative—using specialized transformer models for code search—improves semantic understanding but introduces new bottlenecks. These models require significant computational resources, often need GPU acceleration, and can take seconds to index a repository before the first query can even be made.
Semble's Technical Approach: Speed Meets Accuracy
Semble takes a different path, combining multiple retrieval techniques to achieve remarkable performance. The system works by:
- Code-aware chunking: Splitting files into meaningful segments using Chonkie, a code-aware chunking library
- Dual retrieval strategy: Combining static Model2Vec embeddings with BM25 for lexical matching
- Score fusion: Using Reciprocal Rank Fusion (RRF) to blend results from both approaches
- Code-aware reranking: Applying additional signals specific to code structure and semantics
The key innovation lies in using static embeddings—pre-computed once during indexing—rather than running transformer models at query time. This eliminates the need for GPU acceleration and enables sub-millisecond query responses on standard CPU hardware.
Benchmarking Performance: Impressive Claims
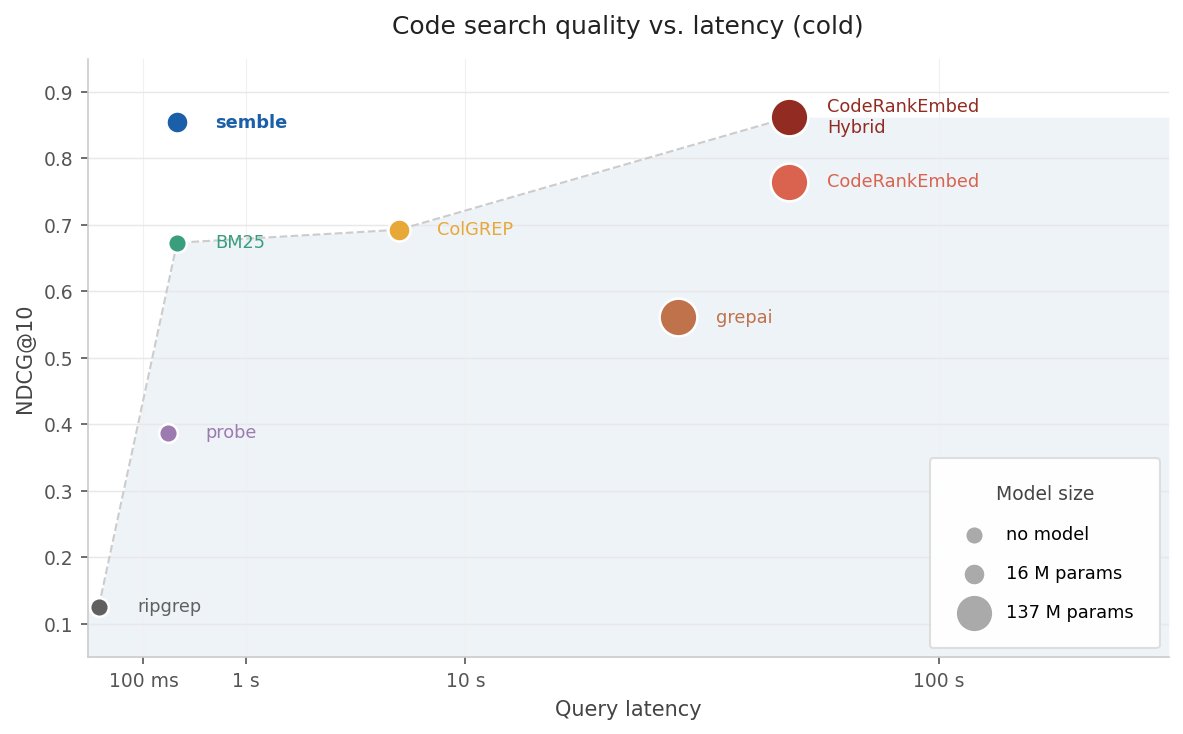
The project's benchmarks are striking, comparing Semble against various code search approaches across 1,250 queries across 63 repositories in 19 languages. The results show:
- Indexing speed: ~200x faster than code-specialized transformers (263ms vs 57 seconds)
- Query speed: ~10x faster than transformer models (1.5ms vs 16ms)
- Retrieval quality: 99% of the performance of a 137M-parameter transformer model (NDCG@10 of 0.854 vs 0.862)
- Token efficiency: 98% fewer tokens than grep+read approaches
The token efficiency chart reveals a particularly compelling advantage. While grep+read requires nearly 100k tokens to achieve 85% recall, Semble reaches 94% recall with just 2k tokens—an order of magnitude improvement that directly translates to more efficient AI agent behavior.
Integration Options: Meeting Developers Where They Are
Semble's adoption strategy focuses on frictionless integration with existing development workflows. The library offers multiple integration paths:
- MCP Server: A drop-in solution for AI coding assistants like Claude Code, Cursor, Codex, and OpenCode
- Bash Integration: Command-line access via
semble searchandsemble find-relatedcommands - Python API: Programmatic access for custom tooling and integrations
- AGENTS.md Integration: Simple configuration for various AI coding frameworks
This multi-pronged approach ensures developers can adopt Semble regardless of their preferred tools and workflows, significantly lowering the barrier to entry.
Community Sentiment and Early Adoption
The project has already gained traction in developer communities, particularly among those working with AI coding assistants. Early adopters report significant improvements in agent responsiveness and context management. The ability to query codebases in natural language (e.g., "How is authentication handled?") rather than constructing complex grep patterns represents a paradigm shift in how agents interact with unfamiliar code.
The token efficiency claims have resonated strongly with developers who have experienced the frustration of context window limitations when working with large codebases. One user noted: "Being able to get precise code snippets without blowing my context budget has transformed how Claude Code works with our monorepo."
Counter-Perspectives and Potential Limitations
Despite the impressive benchmarks, several questions and concerns have emerged from the developer community:
Semantic understanding depth: While the benchmarks show strong retrieval quality, some developers question whether the static embeddings can capture the nuanced semantic relationships that transformer models might understand better
Code language support: The benchmarks cover 19 languages, but the effectiveness may vary across less common or highly specialized languages not represented in the test set
Maintenance overhead: While indexing is fast, maintaining indexes across rapidly changing codebases requires careful handling of file modifications and repository updates
Integration complexity: Although designed to be simple, adding yet another tool to the development stack introduces configuration complexity that some teams may wish to avoid
Thomas van Dongen, one of the creators, addresses these concerns: "Our benchmarks include real-world repositories with active development, showing that Semble handles code changes effectively. The static embeddings are specifically trained on code, giving them a unique advantage for code-specific semantic understanding that general-purpose transformers lack."
The Bigger Picture: Implications for AI-Assisted Development
Semble represents more than just a faster code search tool—it points to a broader shift in how we think about AI and code interaction. By dramatically reducing the cost of code exploration, Semble enables more sophisticated agent behaviors that were previously impractical due to context limitations.
The approach also challenges the assumption that bigger, more complex models are always better for code understanding. Semble's success with carefully crafted static embeddings suggests that domain-specific, efficient approaches may outperform general-purpose models for certain tasks.
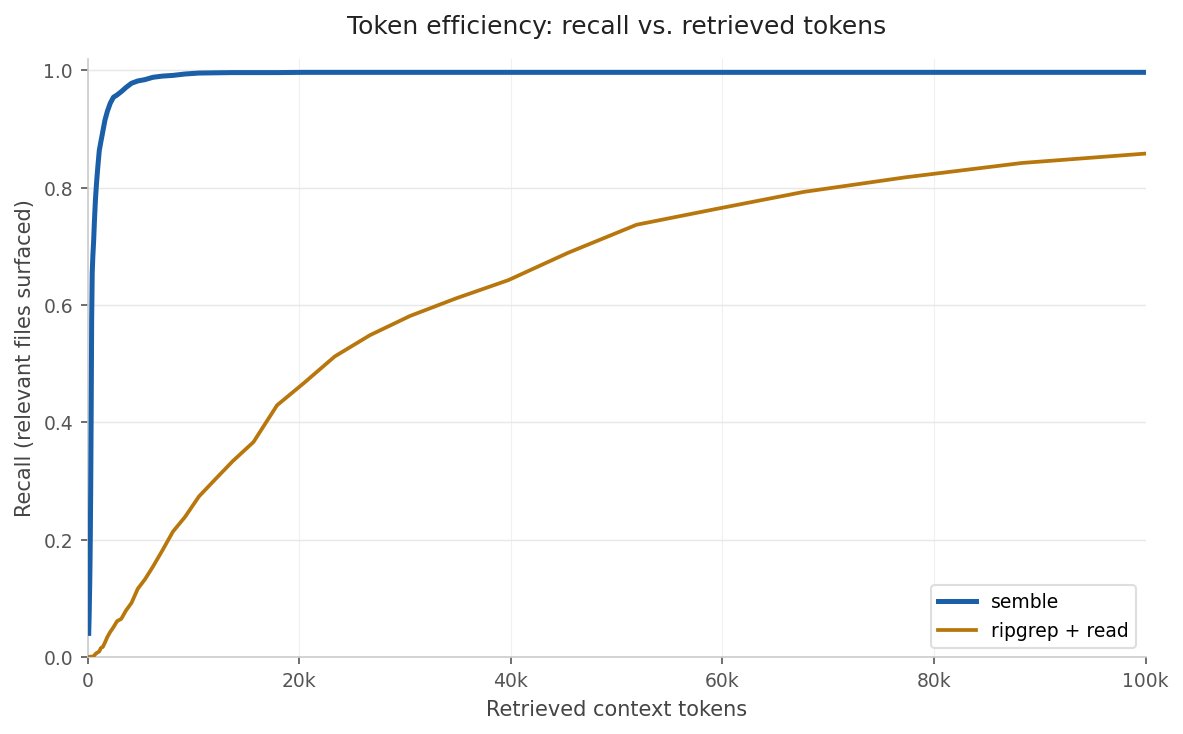
The token efficiency chart demonstrates how Semble achieves high recall with minimal token usage, a critical advantage for AI agents operating with context window constraints.
Looking Forward: The Road Ahead
The project is still early in its development cycle, with the authors actively soliciting feedback and planning enhancements. Potential future directions include:
- Expanded language support and specialized models for particular programming paradigms
- Integration with more development tools and IDEs
- Advanced features like dependency-aware search and impact analysis
- Performance optimizations for even larger codebases
As AI coding agents become more prevalent, tools like Semble will play an increasingly critical role in determining their effectiveness and usability. The balance between computational efficiency and semantic understanding remains a key challenge in this space, and Semble offers an intriguing approach that prioritizes speed without sacrificing accuracy.
For developers and teams working with AI coding assistants, Semble presents an opportunity to significantly improve the agent's ability to understand and navigate codebases. The combination of speed, efficiency, and ease of integration makes it a compelling addition to the growing ecosystem of AI development tools.
As we continue to explore the boundaries of AI-assisted development, innovations like Semble remind us that sometimes the most revolutionary advances come not from making models bigger, but from making them smarter—more focused, more efficient, and more deeply aligned with the specific needs of the task at hand.
Comments
Please log in or register to join the discussion