
Google Cloud unveils the Spanner columnar engine, integrating analytical capabilities directly into its transactional database to eliminate data silos and ETL pipelines. By combining columnar storage and vectorized execution, it accelerates queries up to 200X on live operational data without compromising Spanner's global consistency. This breakthrough empowers developers to derive instant insights from high-velocity transactions, transforming how businesses handle fraud detection, personalizatio

For decades, the chasm between online transaction processing (OLTP) and analytical workloads has plagued data architecture. OLTP systems like Google's Spanner excel at high-throughput, low-latency transactions using row-oriented storage—ideal for operations like payment processing. But analytical queries, which demand rapid scans and aggregations, traditionally require separate data warehouses with columnar storage, forcing complex ETL pipelines, data duplication, and stale insights. Today, that divide collapses. Google Cloud's Spanner columnar engine unifies transactional and analytical processing, enabling real-time intelligence directly on operational data while preserving Spanner's hallmark consistency, availability, and transactional integrity.
The Architecture Revolution: Columnar Storage Meets Vectorized Execution
At its core, the Spanner columnar engine introduces a hybrid storage model that coexists with Spanner's existing row-oriented format. 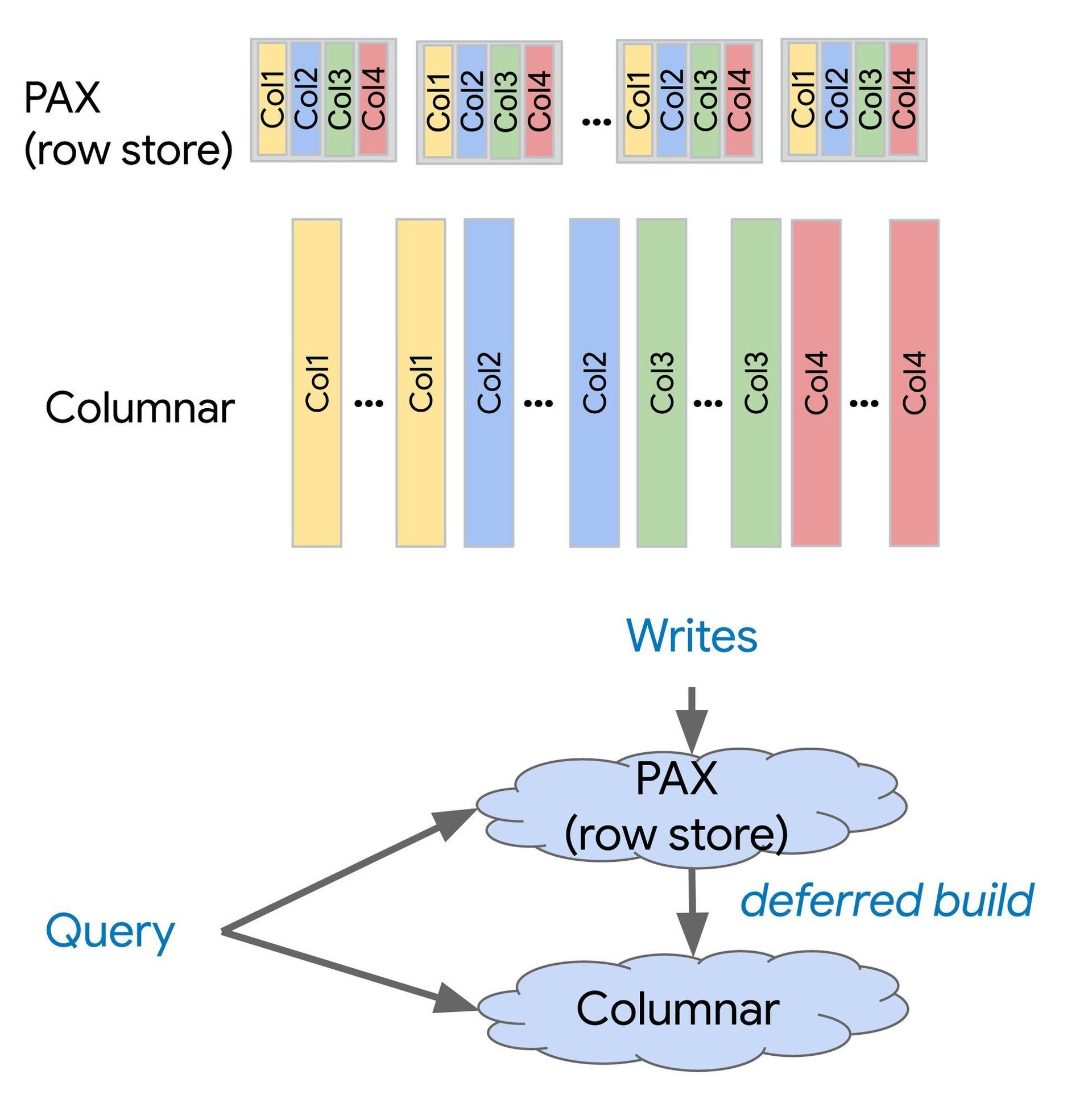 visually illustrates this innovation: data is stored column-by-column rather than row-by-row. This design delivers three critical advantages for analytics:
visually illustrates this innovation: data is stored column-by-column rather than row-by-row. This design delivers three critical advantages for analytics:
- Reduced I/O: Analytical queries often access only a subset of columns (e.g., aggregating sales figures without needing customer addresses). Columnar storage fetches only relevant columns, slashing disk reads.
- Enhanced Compression: Homogeneous data types within columns (like timestamps or prices) compress more efficiently, allowing more data in memory and faster processing.
- Optimized Scans: Consecutive column values are processed in contiguous blocks, accelerating large-scale data scans.
Complementing this, vectorized execution turbocharges query performance. Instead of processing data row-by-row, it handles batches of rows (vectors) simultaneously. This minimizes function call overhead and leverages CPU cache efficiency, turning previously sluggish analytical queries into blazing-fast operations. In internal benchmarks, this combination has accelerated analytics up to 200X on live Spanner datasets—without impacting OLTP workloads. As Raine Scott and Niel Ketkar, founders of fraud-detection platform Verisoul.ai, attest: "Spanner’s columnar engine allows high-velocity transactional writes and rich analytics in one place, eliminating data copies and replication lag so customers get instant answers."
Supercharging BigQuery Integration and Real-World Workloads
The engine’s impact extends beyond Spanner through deeper integration with Google’s Data Cloud. When BigQuery issues federated queries to Spanner, Data Boost—Spanner’s managed compute service for analytics—automatically leverages the columnar engine. This means:
- Near-real-time insights: Complex joins and aggregations on operational data execute faster in BigQuery, syncing live transactions with broader analytics.
- Zero OLTP disruption: Analytical loads are offloaded from primary Spanner instances, maintaining transaction performance.
- Simplified pipelines: Organizations bypass ETL entirely, unifying transactional and analytical ecosystems.
Developers can expect dramatic speedups in diverse scenarios, from graph traversals to vector similarity searches. Consider these TPC-H-inspired examples, where the columnar engine targets only essential columns and applies vectorized filters:
-- Query 1: Revenue from discounted shipments (accelerated via l_shipdate, l_discount scans)
@{scan_method=columnar}
SELECT sum(l.l_extendedprice * l.l_discount) AS revenue
FROM lineitem l
WHERE l.l_shipdate >= date "1994-01-01"
AND l.l_discount BETWEEN 0.07 AND 0.09
AND l.l_quantity < 25;
-- Query 5: Vector similarity search (optimized for contiguous embedding scans)
@{scan_method=columnar}
SELECT e.Id, COSINE_DISTANCE(@vector_param, e.Embedding) AS distance
FROM Embeddings e
ORDER BY distance LIMIT 10;
The Future of Operational Intelligence
By erasing the boundary between transactions and analytics, Spanner’s columnar engine doesn’t just optimize queries—it redefines data-driven agility. Fraud detection, supply chain monitoring, and AI-powered recommendations can now operate on fresh data without latency or integrity trade-offs. For developers, this means fewer pipelines to maintain and more time to build; for data teams, it unlocks unprecedented real-time exploration. As businesses increasingly demand instant insights, this innovation signals a shift toward truly unified databases, where the friction of data movement becomes a relic of the past. The Spanner columnar engine is now in preview—request access to pioneer this next frontier.
Source: Google Cloud Blog
Comments
Please log in or register to join the discussion