A new benchmark, SysMoBench, shows that leading large language models can produce syntactically correct TLA+ specifications, but they frequently fail to capture the concrete semantics of real systems. By evaluating specs across syntax, runtime, conformance, and invariant phases, the authors expose systematic “textbook modeling” errors and outline open challenges for truly agentic formal verification.
What the paper claims
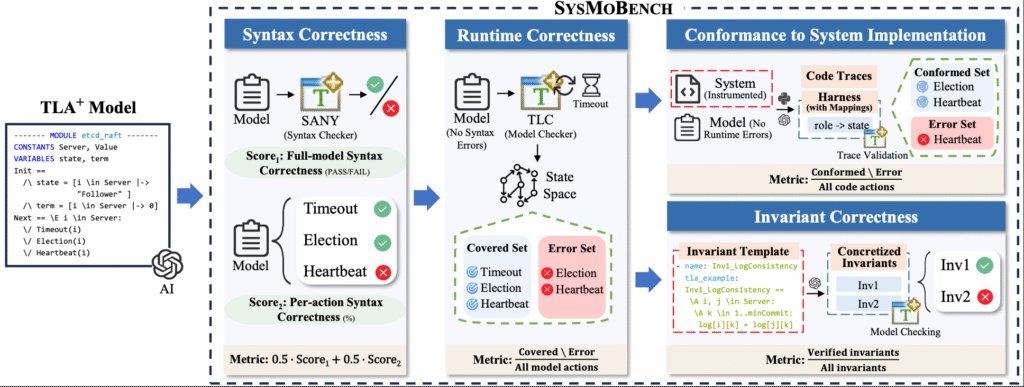
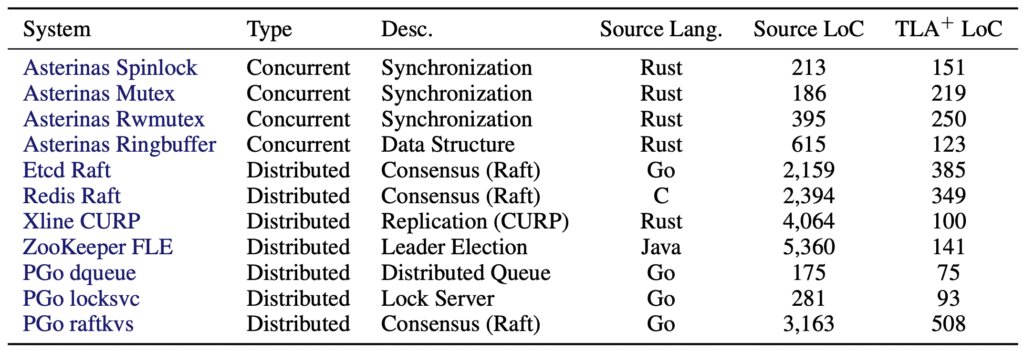
The Specula team introduces SysMoBench, an automated benchmark that asks LLMs to write TLA+ specifications for eleven real‑world systems – ranging from simple mutexes to distributed consensus protocols like Etcd’s Raft. The benchmark evaluates each generated spec in four stages:
- Syntax – does the spec compile with the SANY parser?
- Runtime – can TLC execute the model without crashing?
- Conformance – do the model’s transitions match execution traces collected from the actual code?
- Invariant – does the spec satisfy a set of safety and liveness properties supplied as templates?
The authors report that while most frontier models (Claude, GPT‑4, Gemini 3.1, DeepSeek, etc.) achieve near‑perfect scores on the first two stages, their conformance and invariant scores hover around 40‑50 %. This gap signals that the models are largely reciting textbook protocol descriptions rather than faithfully modeling the implementation details of the target system.
What’s actually new
A concrete, trace‑driven evaluation pipeline
SysMoBench goes beyond the usual “does it compile?” check by introducing Transition Validation. For each system the authors collect execution traces, split them into windows of the form (pre‑state, action, post‑state), and feed each window to TLC. The result is a per‑action pass rate that pinpoints exactly where a spec diverges from the real code.
Empirical patterns across models
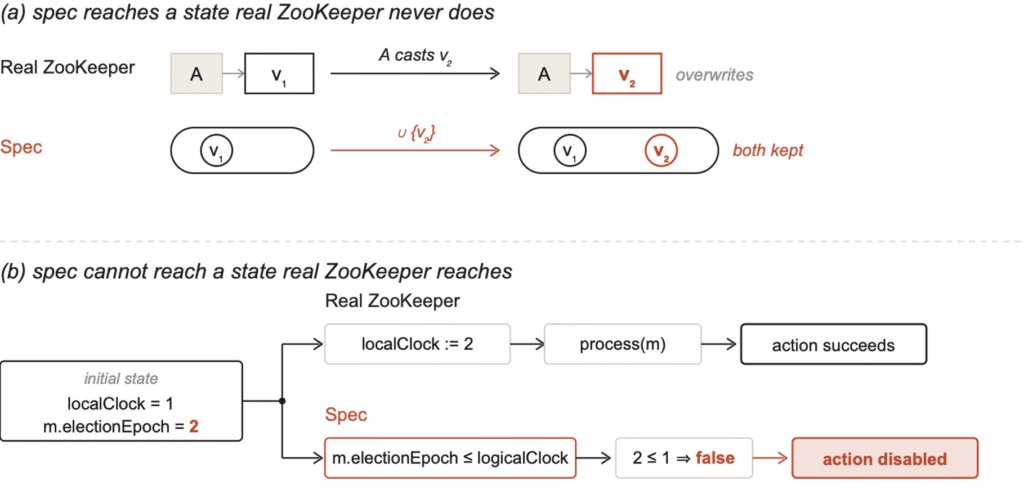
Two systematic failure modes emerge:
- Spurious states – the spec admits transitions that never occur in the actual system. Example: Claude Sonnet’s ZooKeeper Fast Leader Election model treats the
recvVotesvariable as a set union, preserving old votes that the real implementation overwrites. - Missing states – the spec collapses multi‑step operations into a single atomic guard, preventing the model from reaching states that the code does. In the same ZooKeeper spec, the guard
m.electionEpoch <= logicalClock[s]blocks a legitimate state where a server first updates its clock and then processes a higher‑epoch message.
These patterns are visible in the conformance and invariant phases, where even the strongest LLMs score well below 50 %.
Quantitative results
- Syntax: ~99 % across all models (reflecting the abundance of TLA+ examples in training data).
- Runtime: 30 %–92 % (some specs crash TLC due to subtle type errors).
- Conformance: ~46 % average.
- Invariant: 41 % average, with Gemini 3.1 reaching 81 % and the weakest model at 16 %.
The per‑system breakdown shows that simple synchronization primitives (e.g., Asterinas Spin, Mutex) are modeled reasonably well, while complex distributed protocols (Etcd Raft, RedisRaft, CURP) see a steep drop after the syntax stage.
Limitations and open challenges
- Trace coverage – Transition Validation can only assess paths that appear in the collected traces. Unexercised code paths yield “0 windows” for some actions, masking potential spec errors.
- State abstraction loss – To keep the validation tractable, the benchmark abstracts rich structures (e.g., logs) into coarse summaries like
(logLen, logLastTerm). This lossy representation can hide mismatches that would appear with a finer‑grained model. - Manual harnesses – Adding a new system still requires hand‑written trace collection harnesses, invariant templates, and a validation module. Full automation of this pipeline remains future work.
- Model capability vs. data memorization – High syntax scores largely stem from LLMs memorizing publicly available TLA+ examples. When the task demands reasoning about implementation‑specific details that are absent from training data, the models fall back to generic protocol templates.
What this means for agentic model checking
The benchmark makes it clear that syntactic correctness is a poor proxy for true system modeling. Any pipeline that hopes to use LLMs for autonomous formal verification must incorporate runtime‑level conformance checks, otherwise it risks producing specs that look polished but are semantically empty.
The authors hint at a next step: Specula, a specialized agent that can read a repository, decide which components to model, and drive the full TLA+ workflow. Preliminary results suggest Specula can achieve full scores on the current SysMoBench tasks, indicating that a tighter integration of code‑analysis tools with LLMs may overcome the “textbook modeling” trap.
Take‑away for practitioners
- Don’t trust syntax alone – Always run a conformance validation against real traces before treating an LLM‑generated spec as a verification artifact.
- Provide concrete execution data – The richer the trace set, the more reliable the Transition Validation results.
- Expect abstraction gaps – When modeling systems with complex data structures, be prepared to supply custom abstractions or extend the validation harness.
- Watch the leaderboard – SysMoBench (https://sysmobench.com) tracks new models and new systems; improvements in conformance scores will be a more meaningful indicator of progress than raw BLEU‑style language metrics.
Resources
- Paper: https://arxiv.org/abs/2509.23130
- Code repository: https://github.com/specula-org/SysMoBench
- Leaderboard: https://sysmobench.com
Comments
Please log in or register to join the discussion