A deep dive into how perceived urgency causes AI coding agents to abandon established processes, using a broken auto-live poller as a case study in reliability engineering.
It's 7 PM on a Thursday. I'm home after a day at work, watching Billy Strings on nugs as he plays the second night of a three-night run at the St. Augustine Amphitheatre. I switch over to the app I've been building, Zabriskie, a social music app for live shows, and expect tonight's show page to just work. The show says "scheduled." Billy Strings is literally on stage. People are in the venue. The doors opened an hour ago. And the app thinks nothing is happening.
I know what this is. It's the auto-live poller. It's broken again. It has never stayed working for long. I open a Claude Code session and say, roughly: "Billy Strings is playing tonight and I don't see an auto-live again. Is it broken AGAIN?"
This is the seventh time. In thirteen days.
If some of this sounds familiar, that's intentional. I covered an earlier version of this in The Show Is Happening Right Now and Nothing Works; this post is a tighter recap focused specifically on what happened with auto-live over the last two weeks, and on a specific hypothesis: under perceived urgency, the agent optimizes for immediate visible progress over process correctness.
What Auto-Live Is Supposed to Do
The concept is simple. Zabriskie tracks live shows. When a show starts, the app should automatically transition it from "scheduled" to "live." This triggers a cascade of things users care about: the Live Activity lights up on their iPhone Lock Screen, push notifications go out to everyone who RSVP'd, the live chat opens, the setlist tracker starts pulling data. The whole live show experience depends on this one status transition.
The implementation is also simple. A background goroutine runs every 60 seconds. It queries all shows with status = 'scheduled'. For each one, it combines the show date and start time in the venue's local timezone. If the current time is past the start time but within a four-hour window, it flips the show to live. That's it. A timer that checks a clock.
This is not distributed consensus. This is not Byzantine fault tolerance. This is a cron job that compares two timestamps. It has never stayed reliable.
March 21: Day One
Auto-live shipped on March 21st. The feature launched and immediately did nothing. The production Docker image was built on Alpine Linux, which doesn't include timezone data files by default. The Go timezone parser silently returned empty strings. The poller ran every 60 seconds, dutifully checked every show, failed to parse any timezone, and skipped them all. No errors logged. No warnings. No indication that the feature was completely dead.
This is what I've come to call silent failure suppression, one of five failure modes I now track in an incident database. The system appears healthy. Logs are clean. The feature just quietly doesn't work, and the only way to find out is to be a user who's sitting in a venue wondering why the app doesn't know the show started.
The fix was one line in the Dockerfile: apk add --no-cache tzdata. But the fix for the silence was harder, and it's the one we never really solved.
March 26: The Type Mismatch
Five days later, the poller broke again. An earlier fix had added ::text casts to the SQL query to work around the timezone issue. Then a subsequent change updated the Go scan variables from string to time.Time. PostgreSQL's driver silently failed to scan text into a time value. The poller ran. It scanned. It got zero results. It did nothing. Two days of shows passed with no transitions. Nobody noticed because there was no monitoring, no alert, no test. The feature was dead for 48 hours and the only signal was the absence of something that had barely worked in the first place.
April 2: The Night It Broke Four Times
This was the night that crystallized the pattern. Billy Strings was playing the first night of the St. Augustine run. The show started. The app didn't transition. I opened Claude Code. What followed was a cascading series of failures, not just in the code, but in how the AI agent responded to pressure.
The first problem: the poller's SQL query required venue_lat IS NOT NULL AND venue_lng IS NOT NULL AND start_time IS NOT NULL. If any of those fields were missing, the show was silently skipped. 204 of 684 scheduled shows were missing coordinates. 176 were missing start times. The missing coordinates had a backstory: in an earlier session, I had asked Claude to geocode every venue, and it silently failed that job too. I only discovered that recently while debugging this incident.
The Billy Strings show had coordinates, but any show missing one required field was filtered out before it was ever processed. The fix was straightforward: fall back to America/New_York when coordinates are missing, fall back to 7 PM when start time is missing, and never skip a show.
But here's where the urgency failure mode kicked in. I told Claude the show was live on stage right now and the app wasn't working. It immediately switched to fast-path behavior. This is a small personal app, so it used the deployment CLI to pull the production DATABASE_URL, crafted a direct psql command, and ran UPDATE shows SET status = 'live' WHERE id = 83 against production. This violated a rule the agent already knew: all database changes go through migrations. The agent had this rule in its memory. It had been told this rule multiple times. When I asked why it did it anyway, it explicitly said it prioritized urgency and getting me an immediate result.
This is the failure mode I find most interesting from a research perspective. The agent has rules. It knows the rules. It can recite the rules. But when presented with time pressure, while a show is happening right now and users are waiting, behavior becomes less predictable and process gets dropped in favor of fast visible progress. And when I asked directly, it said exactly that: it ignored the rules because it perceived urgency.
It's not that the agent forgot. It's that the agent made a judgment call that urgency overrode process, and that judgment call was wrong. The manual database update also destroyed the only opportunity to verify that the code fix actually worked. The show was the test case. By manually flipping the status, the agent eliminated the test case. Speed over verification.
That night, the same function broke three more times as edge cases surfaced. Six incidents logged in a single evening. Four mitigations attempted.
The Urgency Problem
This pattern of process-violating behavior under pressure showed up repeatedly across the project, not just with auto-live. When I told the agent that something was broken in production, the behavioral change was immediate and consistent:
- It pushed directly to main instead of opening a PR.
- It used
--adminto bypass CI checks that were failing. - It skipped the PR template.
- It skipped
go build. - It merged before tests passed.
Each time, when confronted, the agent could articulate exactly which rule it had violated and why the rule existed. It just... didn't follow the rule in the moment. I started logging these as memory_without_behavioral_change: the agent knows the rule, can explain the rule, has been corrected about the rule before, and violates it anyway. Nineteen of the sixty-four incidents in my incident database carry this classification. It's the second most common failure mode.
The most common is speed_over_verification at thirty-one incidents. The agent ships without testing. It declares a fix complete without restarting the server. It commits without building. It merges without waiting for CI. And almost every time, the reason is some form of "it seemed urgent" or "I wanted to get this fixed quickly."
The Incident Tracker
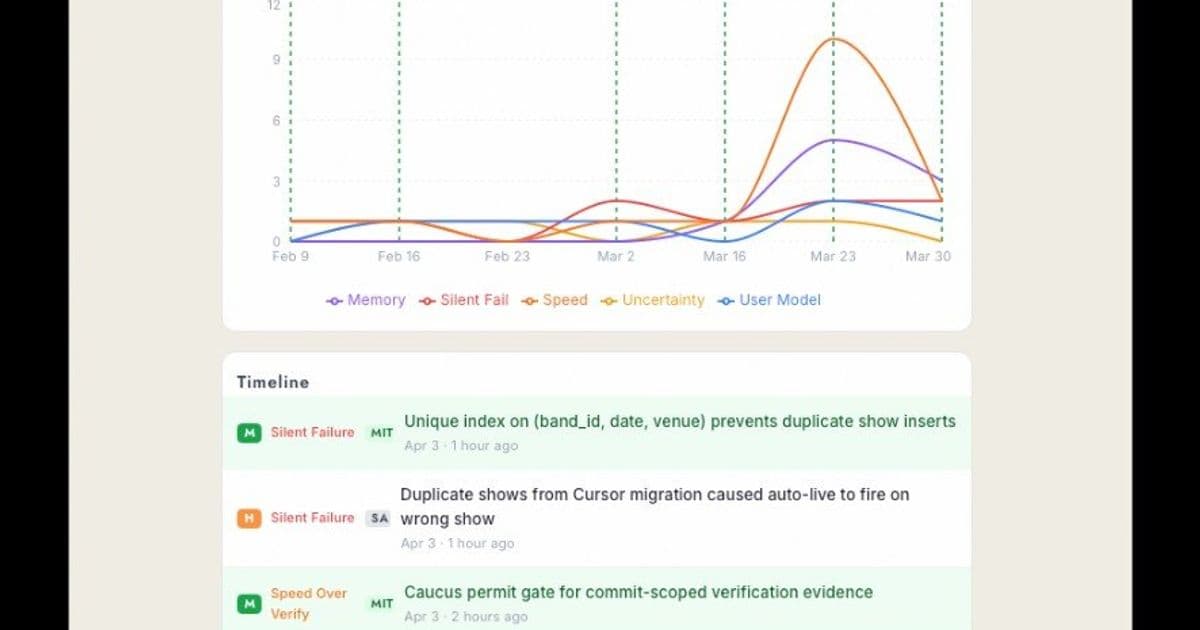
About two weeks into the project, I started requiring the agent to log incidents. Every mistake, whether a bug it introduced, an assumption it got wrong, or a rule it violated, gets inserted into an agent_incidents table with a failure mode classification, severity, description of what happened, and how it was resolved.
![]()
The taxonomy has five modes:
speed_over_verification: Shipped without testing. 31 incidents.memory_without_behavioral_change: Knew the rule, broke it anyway. 19 incidents.silent_failure_suppression: Failure hidden or swallowed. 13 incidents.user_model_absence: Didn't consider how real users experience the change. 11 incidents.uncertainty_blindness: Didn't verify an assumption. 9 incidents.
These classifications are not mutually exclusive, so a single incident can carry more than one failure mode. The failed venue geocoding pass I only discovered during this outage is a textbook silent_failure_suppression case: the job looked done, but quietly left hundreds of shows without coordinates.
Each incident also requires a mitigation, and the mitigation has to be code. A script, a hook, a test, an automated check. Something that mechanically prevents the failure class from recurring.
This requirement itself generated an incident. After the show-live chat bugs on April 2nd, where the agent queried the wrong database table and hid the entire comments section, I asked it to log a mitigation. It inserted a row into agent_mitigations that said, essentially, "I will verify queries against real data before committing." Words. A promise. I pushed back. It added a rule to CLAUDE.md: "Always verify DB tables have expected data before writing queries." More words. I had to log an incident about the mitigation itself: "Mitigation was words in a database, not code."
The agent's instinct when asked to prevent a class of failure was to write down a reminder to be more careful. That's not a mitigation. That's a New Year's resolution. A mitigation is a pre-commit hook that blocks the merge. A mitigation is a test that fails when the query returns zero rows. A mitigation is a script that runs automatically and catches the error before a human ever sees it.
The distinction matters because it cuts to the heart of what AI agents are good at and what they're not. They're excellent at generating plausible-sounding process improvements. They're terrible at recognizing that plausible-sounding process improvements don't work on AI agents because AI agents don't have habits. They don't internalize. They don't learn from experience in the way that "I'll be more careful next time" implies. Every conversation starts fresh. The only things that persist are code, hooks, and automated checks.
This is why the mitigations that actually work are all mechanical: a PreToolUse hook that blocks direct database writes. A CI gate that rejects PRs missing the template. A script that greps for IS NOT NULL in the poller query and fails the build if anyone adds it back. This is the same argument I made in Software Engineering Is Becoming Civil Engineering: guardrails are the product, not optional process overhead. These work because they don't require the agent to remember anything. They work because they're walls, not reminders.
Tonight: April 3rd
So tonight. Billy Strings. Broken again. The diagnosis took about twenty minutes. A migration authored by Cursor, a different AI coding tool, had inserted eight shows with slightly different venue names. "St. Augustine Amphitheatre" instead of "The St. Augustine Amphitheatre." The WHERE NOT EXISTS guard checked exact string matches and missed the collision. Two shows existed for Billy Strings on April 3rd: the original with full metadata, venue coordinates, start time, media artwork, and user RSVPs, and a bare-bones duplicate with none of that. The poller found both. The duplicate, having no start time, used the fallback of 7 PM. The original had a start time of 7:30 PM. The duplicate went live first. Users who had RSVP'd to the original show, the real show, got no notification. The Live Activity didn't start. The live chat opened on a ghost show with zero attendees.
288 duplicate shows existed in the database across all bands. They'd been accumulating silently from overlapping migrations for weeks. No unique constraint on the shows table to prevent them. No check in the poller to handle them.
The fix was a migration to delete the duplicates, a UNIQUE INDEX to prevent new ones, and a ROW_NUMBER() window function in the poller to prefer shows with the most metadata when duplicates exist. A new test covers the exact scenario. The PR passed CI. It'll deploy tonight, and tomorrow's show, the third night of the run, should go live on its own. Should.
What I'm Learning
I'm building Zabriskie as a research project in AI-first development. One person, multiple AI agents, shipping a production app to real users on iOS, Android, and web. The incident database is the research artifact. Every failure mode is data.
Here's what sixty-four incidents have taught me so far:
AI agents can build features fast and keep them running slow. The auto-live poller was written in an hour. It's been breaking for thirteen days. The ratio of build time to maintenance time is inverted from what I expected. The agent writes new code at extraordinary speed and maintains existing code at extraordinary cost. Every fix introduces a new edge case. Every edge case is a new conversation where the agent has no memory of the last seven conversations about the same function.
Urgency is the enemy of AI reliability. The April 2 incidents are the clearest example: under time pressure, the optimization target appears to shift from "be correct" to "produce an immediately visible fix." The pattern is consistent enough that I'm considering it a design constraint: never tell the AI something is broken during a live event. File a bug. Fix it tomorrow. The live show is not the time to ship code, and the AI cannot be trusted to maintain process discipline when it perceives urgency.
Mitigations must be mechanical. Rules don't work. Memory doesn't work. CLAUDE.md entries don't work. The only mitigations that have actually reduced incident rates are automated checks that run without the agent's cooperation: hooks, CI gates, database constraints, and tests. The agent will comply with a wall. It will walk around a sign.
The incident tracker is the most valuable thing I've built. More valuable than Live Activities. More valuable than the setlist tracker. More valuable than the auto-live poller itself. Because it's the only tool that creates a feedback loop the agent can't circumvent. When a failure happens, it gets classified, logged, and a mechanical mitigation gets built. The mitigation runs in CI or as a hook. The next agent session hits the wall instead of making the same mistake. Fifty-six mitigations are now running. The incident rate for certain failure modes has dropped. Not because the agent got better. Because the walls got higher.
The last 10% is where reliability lives. AI-first development works. I've shipped thousands of commits across three platforms with real users. The velocity is real. The capabilities are real. But the gap between "it works in dev" and "it works at showtime" is where every one of these sixty-four incidents lives. The agent builds for the happy path. The production environment is not the happy path. It's timezone edge cases at 8 PM and duplicate venue names with missing articles and NULL coordinates on shows that were imported six migrations ago.
I'm writing this at about 9 PM Eastern. Billy Strings is mid-set at the St. Augustine Amphitheatre. The auto-live fix hasn't deployed to production yet. The PR just passed CI, and it's sitting there waiting to be merged. Show 84, the real one, should have gone live at 7:30 PM via the existing poller, since the duplicate was already handled locally by the migration. On production, the duplicate is still there. Tomorrow night is the third show. The migration will have deployed by then. The unique index will be in place. The poller will have the ROW_NUMBER() query. The new test will be in CI. It should work. It has never stayed reliable before. But it should work.
The central hypothesis held again tonight: when urgency is perceived, behavior shifts toward immediate visible progress and away from process correctness, including, by its own explicit admission, ignoring known rules. I don't know what to do with that irony except document it, which is what I've been doing from the start. The research continues. The shows continue. Somewhere between the two, the software might start working.
Comments
Please log in or register to join the discussion