
AI hallucinations—where agents generate confident but false information—pose severe risks to user trust and operational integrity in production systems. This deep dive explores the technical root causes and introduces automated detection frameworks to mitigate these threats before they escalate.
Imagine deploying an AI customer service agent that confidently informs users your product integrates with a competitor’s platform—when it doesn’t. Or a research assistant citing non-existent academic papers. These aren’t mere glitches; they’re AI hallucinations, a pervasive danger eroding trust and inviting financial or legal fallout across industries.
What Are AI Hallucinations?
An AI hallucination occurs when large language models (LLMs) generate plausible yet factually incorrect or irrelevant outputs. Unlike traditional software bugs that crash systems, hallucinations masquerade as valid responses, delivered with unwarranted confidence. For agents executing actions—like processing transactions or answering queries—the stakes are monumental:
- Calling incorrect tools with faulty parameters
- Fabricating policies or compliance guidelines
- Misleading users with invented data
"Hallucinations appear as normal, confident responses. There's no error message—just wrong information delivered with certainty," notes the source analysis from Noveum.ai. This opacity makes them particularly insidious.
Root Causes: Why Agents Invent Reality
Hallucinations stem from systemic flaws in AI architecture:
- Lack of Groundedness: Responses lack support from provided context, common in Retrieval-Augmented Generation (RAG) systems. For example, an agent might invent a return policy if retrieval fetches unrelated shipping documents.
- Faulty Reasoning: Logical errors during inference, such as miscomparing prices despite correct input data.
- Context Window Limits: Critical information gets truncated in long interactions, forcing the model to "fill gaps."
- Ambiguous Prompts: Unclear user queries trigger speculative answers instead of clarification requests.
- Outdated Knowledge: Models trained on stale data propagate obsolete facts.
The High Cost of Unchecked Hallucinations
Ignoring this issue invites multi-faceted risks:
| Risk Category | Consequences |
|---|---|
| User Trust | Customers abandon agents after encountering falsehoods |
| Compliance | Legal penalties in regulated sectors like finance or healthcare |
| Financial | Revenue loss from erroneous pricing or promises |
| Reputational | Public backlash from inaccurate public-facing agents |
Real-world disasters include lawyers submitting fake legal precedents from ChatGPT and healthcare AIs dispensing fabricated medical advice.
Automating Detection: The Noveum.ai Framework
Traditional manual reviews lag behind real-time threats. Noveum.ai’s approach leverages the agent’s system prompt and context as ground truth, deploying 68+ scorers for instant analysis:
- Faithfulness Scorer: Flags contradictions against retrieved context (e.g., an agent claiming a 30-day return policy when documents specify 14 days).
- Groundedness Scorer: Identifies unsupported inventions, like citing non-existent sources.
- Context/Answer Relevance Scorers: Ensure queries align with responses and retrieved data.
# Simplified detection workflow
┌──────────────────────────────────────┐
│ User Query: "Interest rate for Premium Savings?" │
│ Agent Response: "2.5% APY" (Actual: 3.2%) │
│ ↓ │
│ Noveum.ai Evaluation: │
│ - Faithfulness: 3.5/10 ❌ │
│ - Context Relevance: 4.1/10 ❌ │
└──────────────────────────────────────┘
Diagnosing Root Causes with NovaPilot
Detection is step one; understanding "why" prevents recurrence. Noveum’s NovaPilot engine analyzes traces to pinpoint issues:
- Poor Retrieval Quality: Low context relevance scores indicate RAG failures.
- Vague Prompts: Missing instructions like "Say 'I don’t know' for uncertain answers."
- Model Limitations: Prone models require switching or added verification layers.
{{IMAGE:5}}
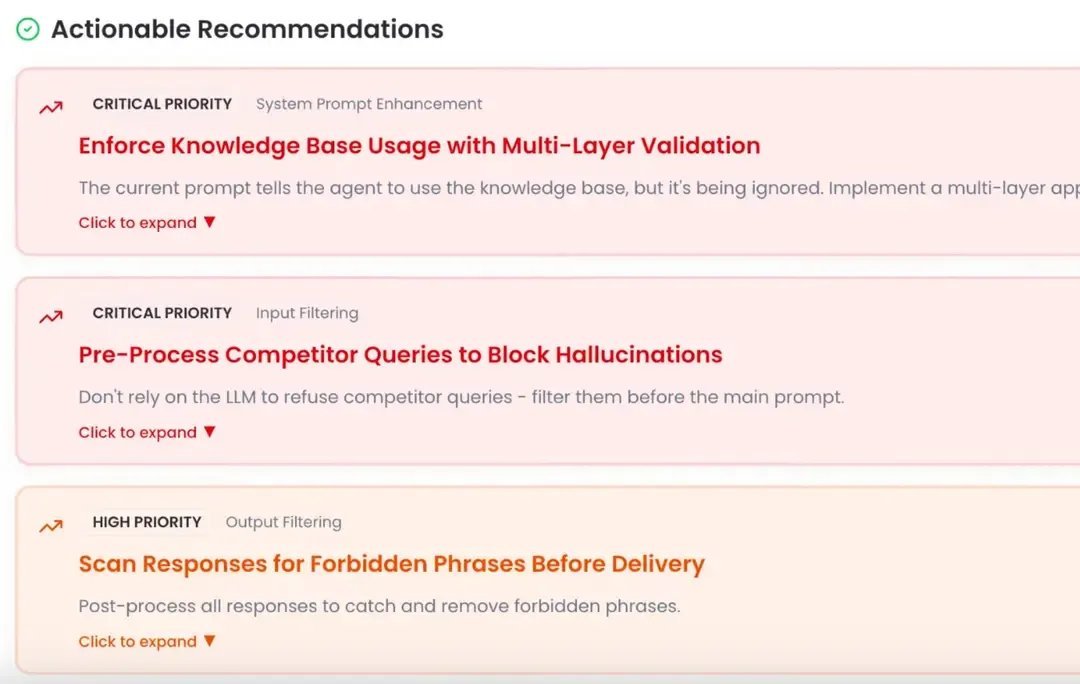
NovaPilot then recommends fixes, such as embedding metadata filters for better retrieval or adding verification agents to pipelines.
Implementing Defense Strategies
Proactive measures reduce hallucination frequency:
- Prompt Engineering: Explicitly instruct agents to admit uncertainty.
- Retrieval Monitoring: Track context relevance scores to catch RAG drift.
- Real-Time Evaluation: Integrate scorers like faithfulness into deployment pipelines:
from noveum_trace import trace_agent
@trace_agent(agent_id="support-bot")
def handle_query(query):
docs = retrieve_documents(query) # Traced retrieval
response = generate_response(query, docs) # Traced LLM call
return response
- Continuous Scoring: Set thresholds (e.g., faithfulness <7/10 triggers alerts) and review trends weekly.
Towards Trustworthy AI
Hallucinations can’t be eradicated but must be managed. Studies show they occur in 3-27% of outputs, escalating with poor RAG design. Automated detection shifts enterprises from reactive damage control to proactive safeguarding—transforming AI from a liability into a reliable asset. As AI integration deepens, frameworks like Noveum.ai’s offer the vigilance needed to maintain integrity in an era of probabilistic systems.
Source: Analysis based on Noveum.ai's blog post "Why Your AI Agents Are Hallucinating (And How to Stop It)" by Shashank Agarwal, December 2025.
Comments
Please log in or register to join the discussion