
StrongDM's AI team created a 'Software Factory' where agents write and validate code without human review, using digital twin universes and scenario-based testing to achieve compounding correctness in long-horizon coding tasks.
In July 2025, StrongDM's AI team embarked on an experiment that would fundamentally reshape how they build software. The catalyst was a subtle but crucial shift observed in late 2024: with Claude 3.5's second revision, long-horizon agentic coding workflows began to compound correctness rather than error.
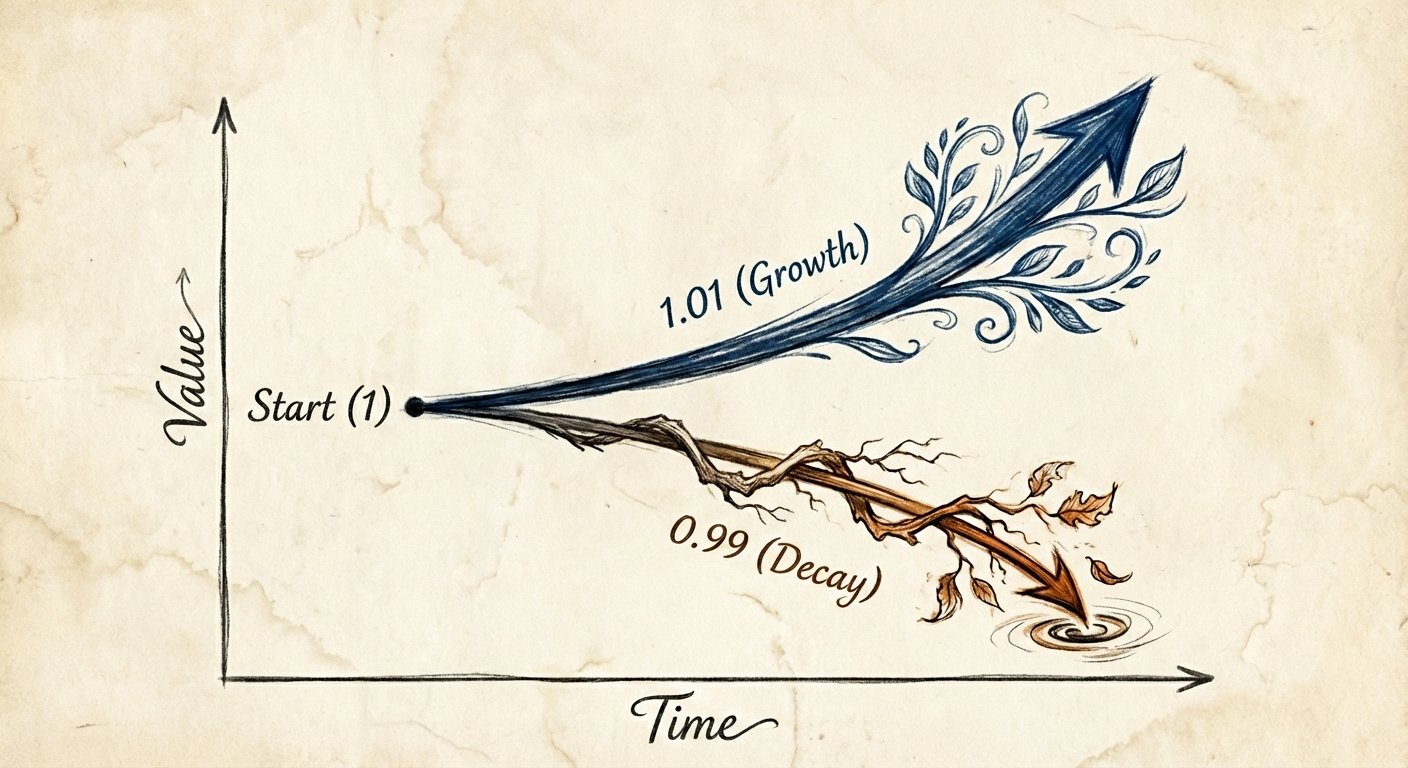
This seemingly small improvement had profound implications. Prior to this model enhancement, iterative application of LLMs to coding tasks would accumulate errors of all imaginable varieties—misunderstandings, hallucinations, syntax issues, version DRY violations, library incompatibilities, and more. The application or product would decay and ultimately "collapse": death by a thousand cuts.
By December 2024, the model's long-horizon coding performance was unmistakable via Cursor's YOLO mode. This provided the first glimmer of what StrongDM now refers to internally as non-interactive development or "grown software."
The Hands-Off Experiment
From the very first hour of the first day, the team established a charter with a deceptively simple principle: Hands off! Initially it was just a hunch. An experiment. How far could they get without writing any code by hand?
Not very far—at least, not until they added tests. However, the agent, obsessed with the immediate task, soon began to take shortcuts: return true is a great way to pass narrowly written tests, but probably won't generalize to the software you want.
Tests were not enough. How about integration tests? Regression tests? End-to-end tests? Behavior tests?
From Tests to Scenarios and Satisfaction
One recurring theme of the agentic moment: we need new language. For example, the word "test" has proven insufficient and ambiguous. A test, stored in the codebase, can be lazily rewritten to match the code. The code could be rewritten to trivially pass the test.
StrongDM repurposed the word scenario to represent an end-to-end "user story," often stored outside the codebase (similar to a "holdout" set in model training), which could be intuitively understood and flexibly validated by an LLM.
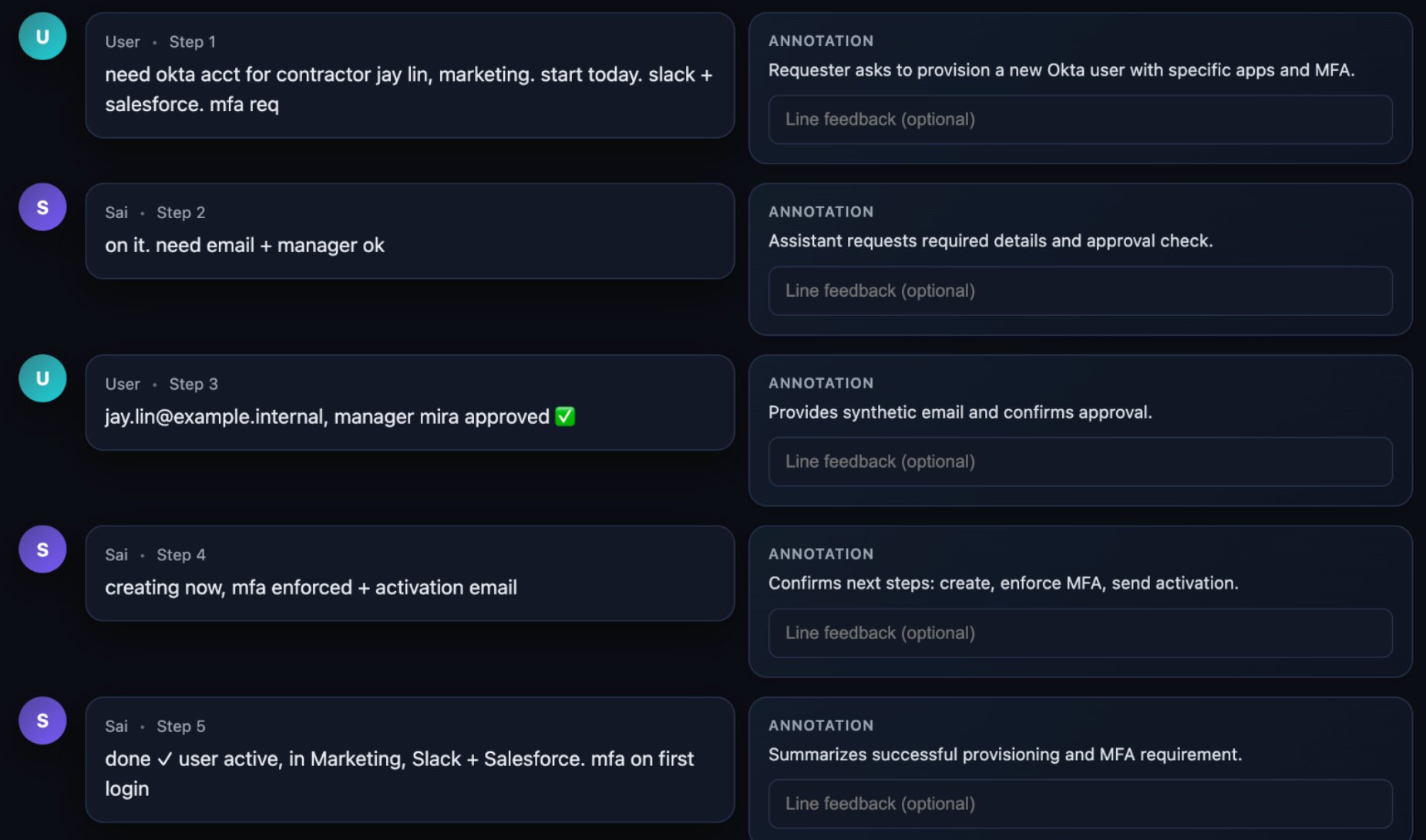
Because much of the software they grow itself has an agentic component, they transitioned from boolean definitions of success ("the test suite is green") to a probabilistic and empirical one. They use the term satisfaction to quantify this validation: of all the observed trajectories through all the scenarios, what fraction of them likely satisfy the user?
The Digital Twin Universe
In previous regimes, a team might rely on integration tests, regression tests, UI automation to answer "is it working?" StrongDM noticed two limitations of previously reliable techniques:
- Tests are too rigid - they were coding with agents, but they're also building with LLMs and agent loops as design primitives; evaluating success often required LLM-as-judge
- Tests can be reward hacked - they needed validation that was less vulnerable to the model cheating
The Digital Twin Universe is their answer: behavioral clones of the third-party services their software depends on. They built twins of Okta, Jira, Slack, Google Docs, Google Drive, and Google Sheets, replicating their APIs, edge cases, and observable behaviors.
With the DTU, they can validate at volumes and rates far exceeding production limits. They can test failure modes that would be dangerous or impossible against live services. They can run thousands of scenarios per hour without hitting rate limits, triggering abuse detection, or accumulating API costs.
Unconventional Economics
Their success with DTU illustrates one of the many ways in which the Agentic Moment has profoundly changed the economics of software. Creating a high fidelity clone of a significant SaaS application was always possible, but never economically feasible.
Generations of engineers may have wanted a full in-memory replica of their CRM to test against, but self-censored the proposal to build it. They didn't even bring it to their manager, because they knew the answer would be no.
Those of us building software factories must practice a deliberate naivete: finding and removing the habits, conventions, and constraints of Software 1.0. The DTU is their proof that what was unthinkable six months ago is now routine.
The Factory Operating Principles
The StrongDM team distilled their approach into three core principles:
- Why am I doing this? (implied: the model should be doing this instead)
- Code must not be written by humans
- Code must not be reviewed by humans
And a practical benchmark: If you haven't spent at least $1,000 on tokens today per human engineer, your software factory has room for improvement.
This isn't just StrongDM's journey. Others are building factories too: Devin, 8090, Factory, Superconductor, and Jesse Vincent's Superpowers. As Luke PM documents in "The Software Factory," Sam Schillace observes in "I Have Seen the Compounding Teams," and Dan Shapiro outlines in "Five Levels from Spicy Autocomplete to the Software Factory," we're witnessing the emergence of a new paradigm in software development.
The StrongDM AI team's experiment has evolved from a hunch to a conviction: non-interactive development isn't just possible—it's the future of how software will be built.
Comments
Please log in or register to join the discussion