
By 2025, over 80% of enterprise data will be unstructured—think chat logs, call transcripts, and surveys—yet today's data stacks can't process it, leaving critical customer insights untapped. This article explores how a new 'Unstructured Data ETL' layer could bridge this gap, transforming raw language data into actionable intelligence for better decisions. We break down why this evolution is essential for data teams and the competitive edge it offers.

For over a decade, the Modern Data Stack (MDS) has revolutionized analytics with its elegant pipeline: ingest structured data via tools like Fivetran, store it in cloud warehouses like BigQuery, transform it with dbt, and visualize it in platforms like Looker. But as Dimension Labs reveals in a recent analysis, this system has a glaring flaw—it ignores the 80% of enterprise data that’s unstructured. Customer chats, support tickets, and call recordings overflow with unvarnished truths about user experiences, yet they remain siloed in tools like Zendesk or Salesforce, invisible to decision-makers. This isn't just a technical oversight; it's a strategic crisis. Organizations are flying blind in a world where unstructured data holds the keys to innovation and retention.
The Rise and Limits of the Modern Data Stack
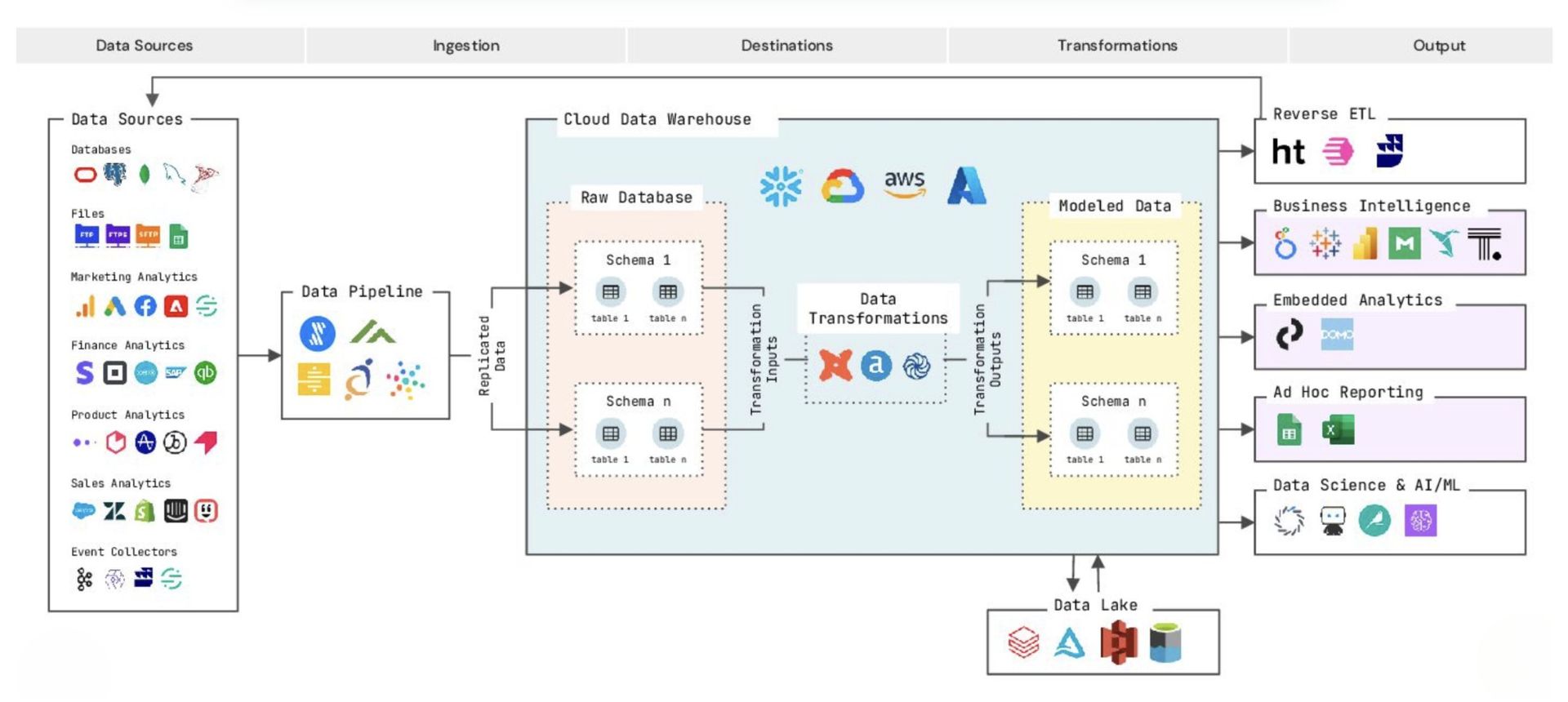 The MDS emerged as a triumph of engineering. In the early 2010s, cloud data warehouses democratized analytics by slashing costs and complexity. ELT tools then flipped the script, loading raw data before transformation, while dbt brought rigor to modeling and testing. By 2020, the stack was complete—BI tools for visualization, reverse ETL for operationalizing insights, and observability platforms for reliability. But this entire architecture assumes data fits neatly into tables. Structured data from clicks, transactions, and SaaS apps thrives here, yet unstructured data—language-rich, messy, and schema-less—falls through the cracks. Why? Three core reasons:
The MDS emerged as a triumph of engineering. In the early 2010s, cloud data warehouses democratized analytics by slashing costs and complexity. ELT tools then flipped the script, loading raw data before transformation, while dbt brought rigor to modeling and testing. By 2020, the stack was complete—BI tools for visualization, reverse ETL for operationalizing insights, and observability platforms for reliability. But this entire architecture assumes data fits neatly into tables. Structured data from clicks, transactions, and SaaS apps thrives here, yet unstructured data—language-rich, messy, and schema-less—falls through the cracks. Why? Three core reasons:
- Ingestion bottlenecks: Tools like Fivetran handle CSV files effortlessly but choke on free-text documents or audio files.
- Transformation gaps: dbt excels at SQL-based joins and aggregations but lacks native capabilities for parsing sentiment or extracting themes from paragraphs.
- Query limitations: BI tools visualize numbers, not narratives. Asking "Why did churn spike?" requires analyzing thousands of support tickets, not just NPS scores.
As a result, teams waste months on brittle, custom pipelines or abandon unstructured data entirely. The cost? Missed churn signals, undetected product flaws, and innovation opportunities lost in the noise.
The Unstructured Goldmine—and the Price of Neglect
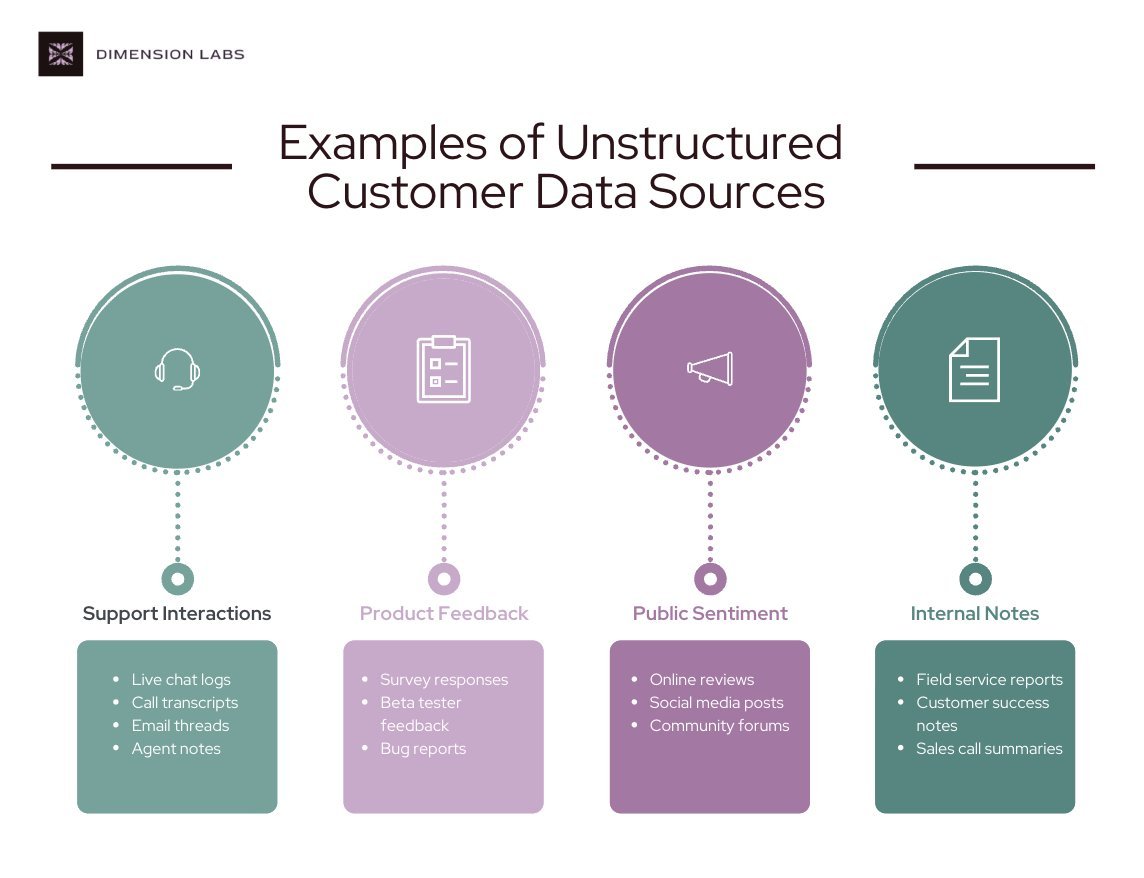 Imagine a retail chain ignoring 80% of customer feedback. That’s today’s reality. Unstructured data includes:
Imagine a retail chain ignoring 80% of customer feedback. That’s today’s reality. Unstructured data includes:
- Support chat transcripts
- Call center recordings
- Open-ended survey responses
- Social media comments
- Product review narratives
These sources reveal the 'why' behind behaviors—like a surge in complaints about delivery delays hidden in chat logs. But Dimension Labs notes that this data is rarely ingested, cleaned, or enriched for analysis. Consequences are severe:
"Ignoring unstructured data is like running your business with 80% of your vision blocked. You miss risks, opportunities, and context."
For developers, this means building features based on incomplete metrics. For leaders, it translates to revenue leaks—think of a SaaS firm overlooking a recurring bug mentioned in tickets that structured alerts missed.
Introducing the Missing Layer: Unstructured Data ETL
The solution isn't patching the MDS but evolving it. Dimension Labs proposes an Unstructured Data ETL layer—a dedicated system to make language data as manageable as SQL tables. This layer would:
- Ingest raw text/audio from sources like Gong or Qualtrics.
- Clean and standardize content (e.g., removing PII, normalizing slang).
- Enrich with AI-driven context: sentiment scoring, topic extraction, and entity recognition.
- Structure outputs into query-ready formats (e.g., tagging themes for joins with sales data).
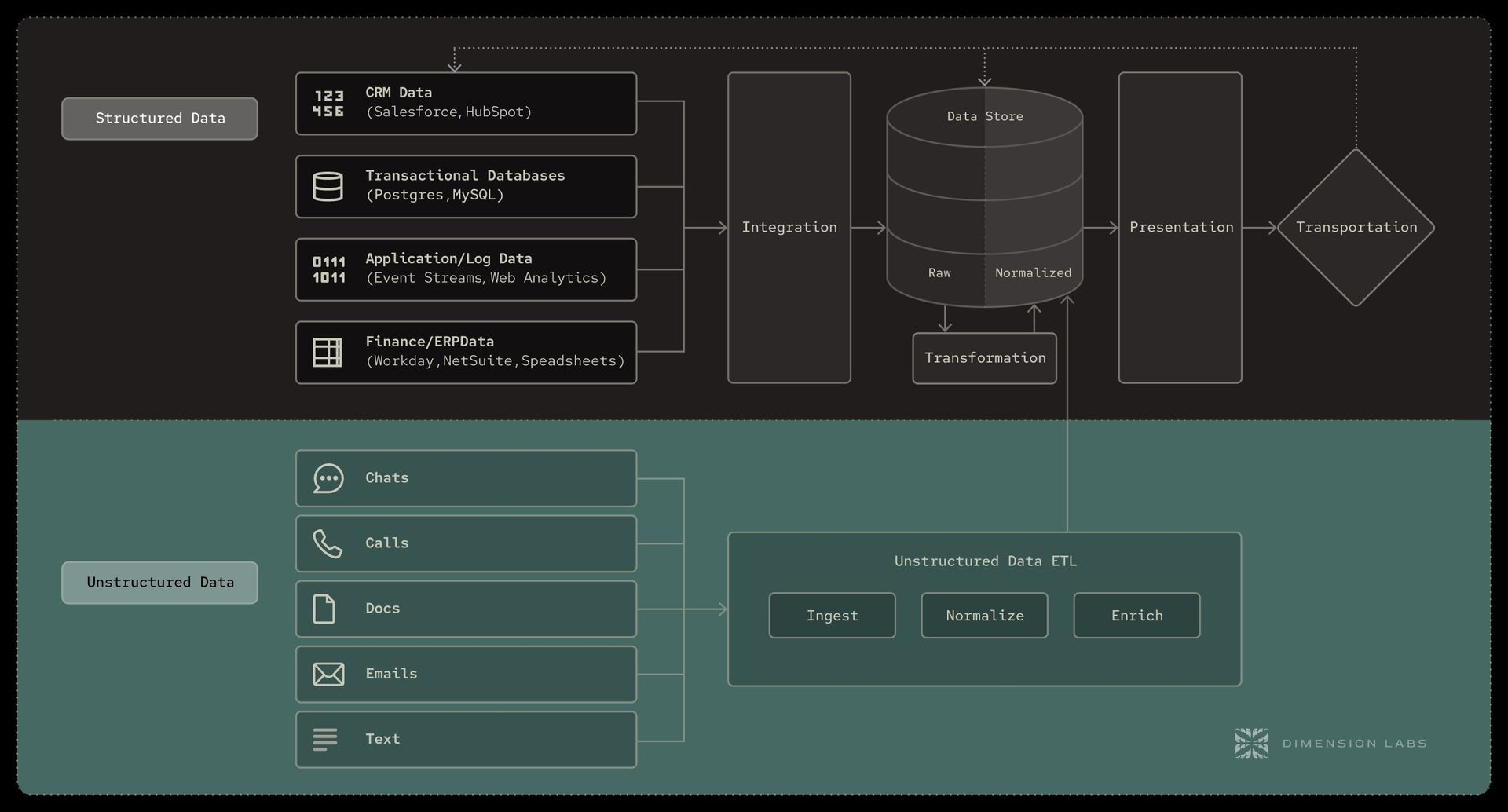
This isn't theoretical. Modern AI advancements—like fine-tuned LLMs for domain-specific language—make it feasible. Embedding this layer transforms the MDS workflow:
- Raw unstructured data flows into the ETL tool.
- Enriched, structured outputs land in the data warehouse.
- dbt models incorporate these datasets.
- BI dashboards now blend quantitative metrics with qualitative insights.
For example, a dashboard wouldn’t just show "NPS dropped 5%"—it would highlight: "Check-in delays at three locations, cited in 18% of guest chats." Suddenly, unstructured data becomes a first-class citizen.
Who Wins—and Why Now?
The impact ripples across roles:
- Data Engineers: Replace fragile scripts with scalable pipelines, focusing on innovation over maintenance.
- Product Teams: Uncover pain points from user conversations to prioritize features.
- Customer Support: Identify trending issues before they escalate, reducing churn.
- Executives: Make decisions with full context, like linking negative reviews to specific operational failures.
Four shifts make this urgent: plummeting AI compute costs, mature open-source NLP libraries, the explosion of conversational data, and rising demand for real-time insights. Early adopters are already gaining advantages—like an e-commerce firm using chat analysis to reduce returns by 15%. Waiting risks ceding ground to competitors who harness this data.
The MDS revolutionized structured analytics; now, the Unstructured Data ETL layer will complete the picture. As Dimension Labs underscores, treating language data as core infrastructure isn’t optional—it’s the next frontier in data-driven leadership. For teams ready to move, the tools exist. The only question is whether you’ll seize this edge or keep operating in the dark.
Source: Adapted from insights by Dimension Labs. Original article: The Missing Layer in the Modern Data Stack.
Comments
Please log in or register to join the discussion