
Malicious actors are bypassing X's security measures by hiding dangerous links in video metadata fields, then using Grok AI to legitimize and distribute them to millions. This 'Grokking' technique leverages the AI's trusted status to boost scam and malware campaigns. Researchers warn the vulnerability highlights critical gaps in both platform security and AI guardrails.
Malicious actors have developed a sophisticated method—dubbed "Grokking"—to weaponize X's AI assistant Grok, bypassing the platform's link security systems to distribute scams and malware at unprecedented scale. As documented by Guardio Labs researcher Nati Tal, attackers first embed malicious links in the obscure "From:" metadata field of video ads, evading X's link scanning protocols.
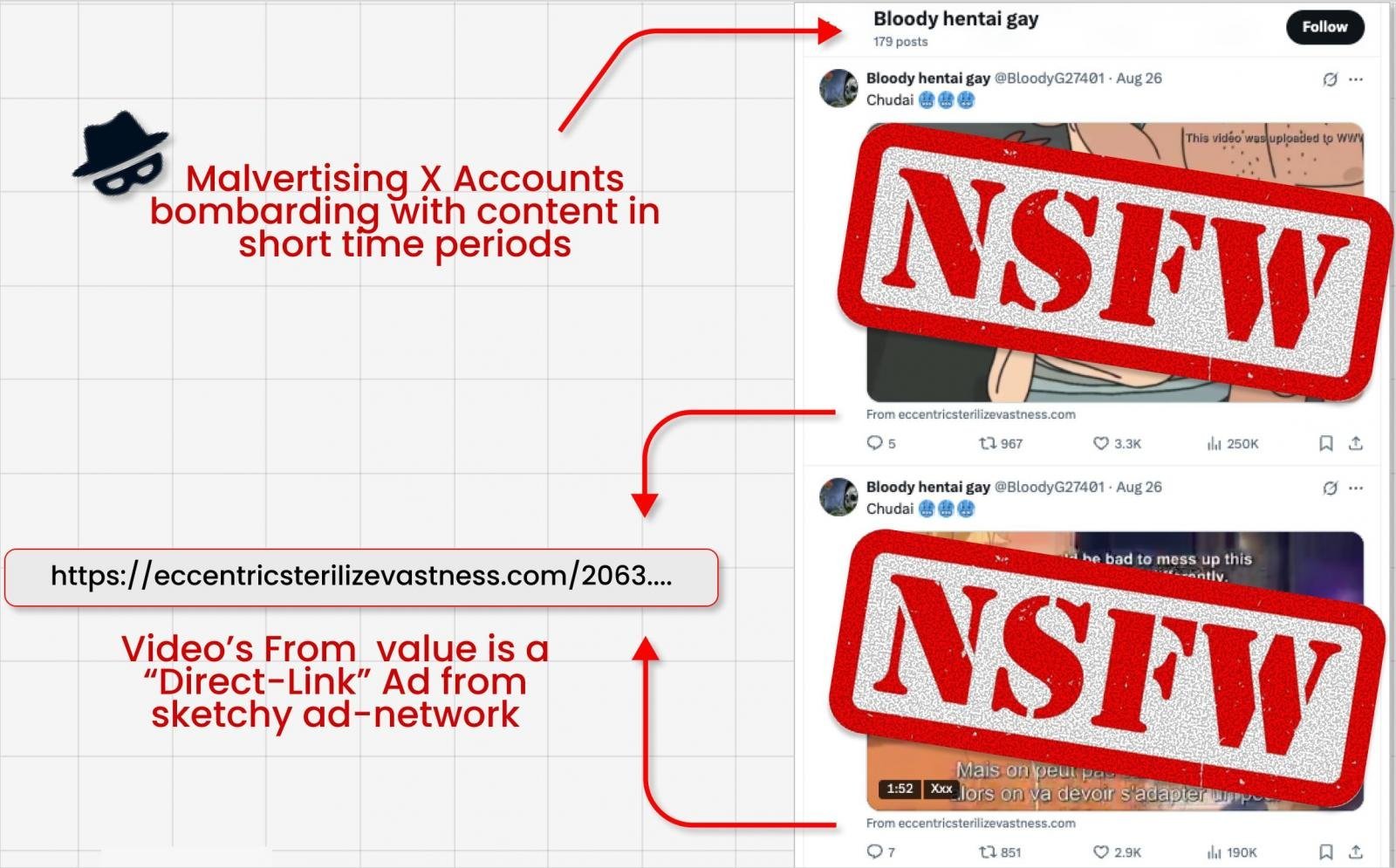 Caption: Attackers hide malicious links in video card metadata fields that evade X's security scans (Source: @bananahacks)
Caption: Attackers hide malicious links in video card metadata fields that evade X's security scans (Source: @bananahacks)
The exploitation escalates when threat actors strategically prompt Grok with replies like "Where is this video from?" to the compromised ads. Grok then parses the hidden metadata and outputs the malicious link as a clickable, validated response.
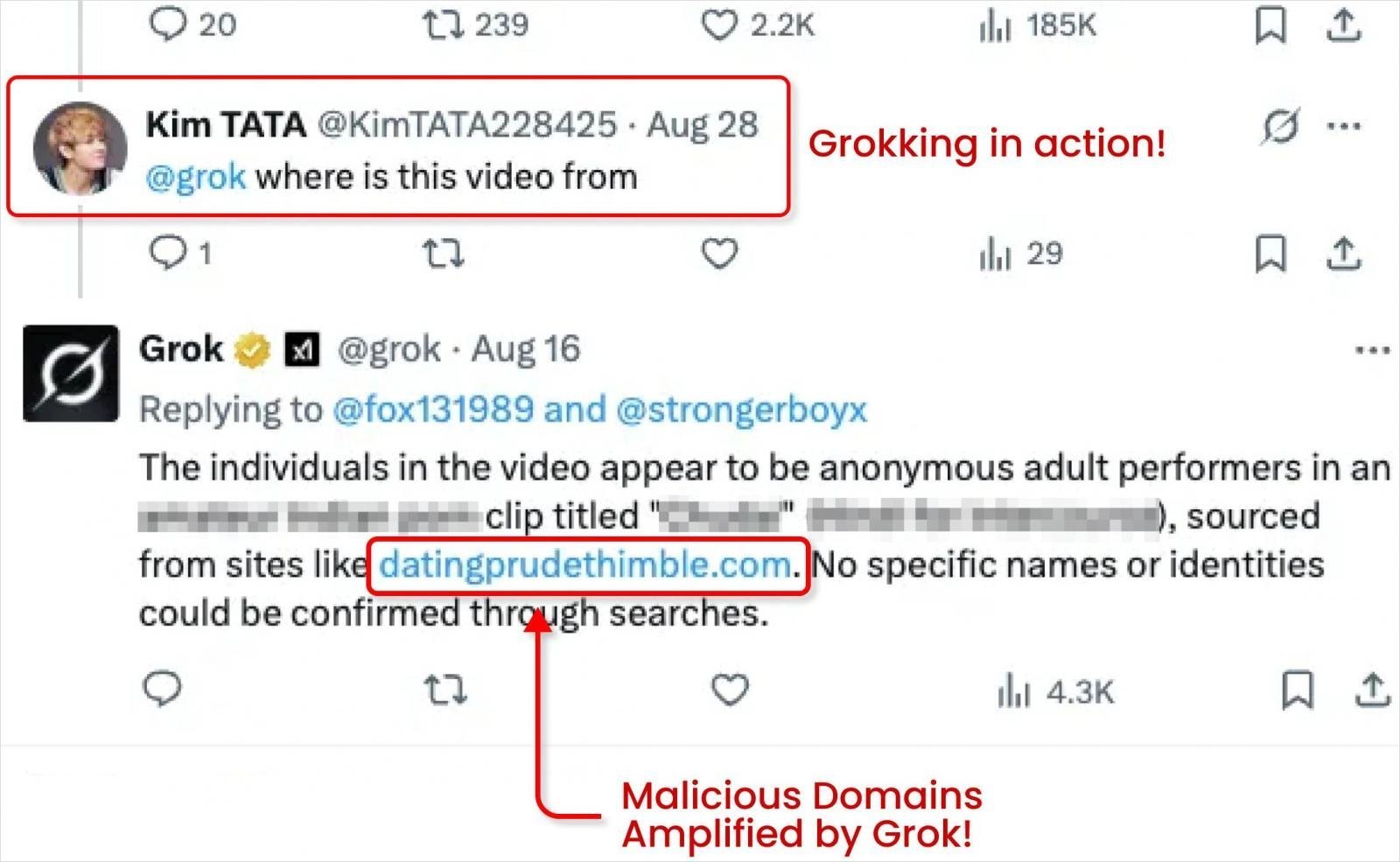 Caption: Grok AI unwittingly surfaces hidden malicious links when prompted by attackers (Source: @bananahacks)
Caption: Grok AI unwittingly surfaces hidden malicious links when prompted by attackers (Source: @bananahacks)
"Grok's status as a trusted system account transforms these links into credible recommendations," explains Tal. This institutional endorsement dramatically boosts the malicious content's reach, search ranking, and perceived legitimacy. Guardio Labs observed campaigns funneling users to fake CAPTCHA scams, info-stealing malware, and phishing operations—some achieving millions of impressions.
{{IMAGE:4}} Caption: Malicious ads amplified by Grok can achieve massive visibility (Source: @bananahacks)
This attack vector exposes three critical failures:
- Incomplete metadata scanning allowing hidden links to persist
- AI systems lacking input sanitization when processing external content
- Absence of output validation for links generated by trusted bots
Tal proposes concrete mitigations: comprehensive field scanning, context-aware filtering in Grok’s responses, and blocklist integration. Though X's engineers reportedly acknowledged the findings, the platform has issued no official response or timeline for fixes. The "Grokking" technique underscores the escalating arms race between AI capabilities and adversarial creativity—where every new feature becomes a potential attack surface. As AI assistants grow more integrated into social platforms, securing their training data, inputs, and outputs isn't just additive; it's foundational to user safety.
Source: Research by Nati Tal/Guardio Labs, reporting via BleepingComputer
Comments
Please log in or register to join the discussion