A deep dive into the complementary AI paradigms transforming how language models interact with data: Retrieval-Augmented Generation for document memory and Model Context Protocol for real-time system integration. Discover why engineers are combining these approaches to build AI copilots that both remember and act.
A quiet revolution is unfolding in AI architecture as engineers confront a critical divide: Should language models recall information from documents or act on live systems? The emerging consensus points to two complementary paradigms—Retrieval-Augmented Generation (RAG) and Model Context Protocol (MCP)—as the foundational duo for next-generation AI systems. While RAG acts as a model's long-term memory, MCP functions as its sensory-motor system, and together they enable LLMs to transcend passive text prediction.
The Memory Layer: RAG's Document Recall
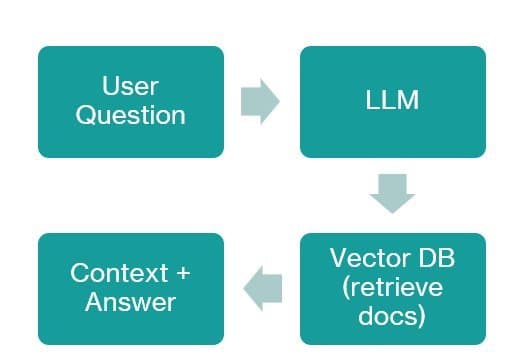
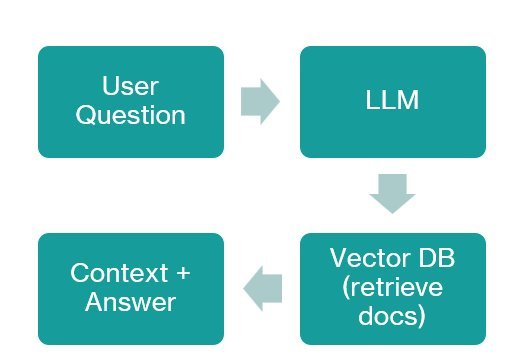
Retrieval-Augmented Generation gives LLMs access to external knowledge through semantic search. By querying a vector database of document embeddings, RAG allows models to pull relevant information into their context window before generating responses. This technique effectively gives AI systems a "memory" of documents, manuals, and unstructured data—proven invaluable for knowledge-heavy domains like technical support or research.
"RAG anchors LLMs in verifiable facts rather than parametric knowledge alone," explains an AI architect at a Fortune 500 tech firm. "It's the antidote to hallucination in enterprise deployments."
The Action Layer: MCP's Real-Time Integration
Model Context Protocol takes a fundamentally different approach. This emerging standard provides structured, real-time access to tools and data systems through JSON-RPC interfaces. Instead of parsing ambiguous natural language commands, MCP exposes discoverable functions (e.g., sql.query or profile.table) with strict schemas—effectively giving LLMs "eyes and hands" to interact with databases, APIs, and operational systems.
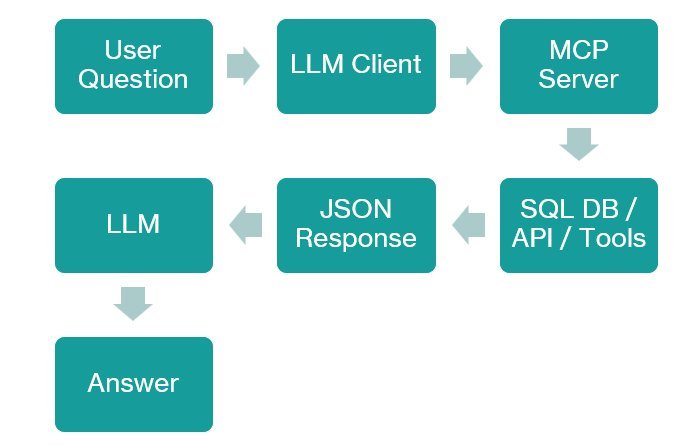
Key technical differentiators:
- Structured Access: MCP servers act as adapter layers with schema-defined tools
- Safety First: Models call pre-vetted functions instead of generating arbitrary code
- Real-Time Operation: Direct connectivity to live data streams and transactional systems
Synergy in Practice: Memory Meets Muscle
The true power emerges when combining both paradigms. Consider a supply chain analyst asking: "What caused the Shanghai shipment delay last week?"
- RAG recalls: Searches incident reports/emails about the shipment
- MCP acts: Queries real-time logistics DB for container status
- LLM synthesizes: Combines both streams into actionable insights
This hybrid approach shines in concrete scenarios:
// MCP server exposing warehouse DB + RAG document recall
const tools = {
inventory: {
query: (sql) => db.run(sql),
docs: (question) => ragSearch(question)
}
};
Engineering Implications
For data teams, MCP delivers unprecedented access:
- Safe Tool Exposure: Wrap Snowflake, BigQuery, or internal APIs with permissioned schemas
- Live Analytics: Enable LLMs to run profiling, data quality checks, or lineage tracing
- Hybrid Workflows: Combine SQL queries with semantic document search in single interactions
Meanwhile, RAG remains indispensable for compliance-heavy domains requiring document provenance. The combination transforms LLMs from conversational novelties into:
"Active copilots capable of both recalling institutional knowledge and executing precise data operations—without exposing dangerous system access."
The Path Forward
As these patterns mature, expect tighter integration between retrieval and action layers. Early adopters report 40% reductions in analytics query times by offloading data navigation to MCP-wrapped LLMs, while RAG continues to evolve with multi-modal retrieval. The divide between memory and muscle isn't a battle—it's the blueprint for AI systems that truly understand enterprise environments.
Source: InfoCaptor
Comments
Please log in or register to join the discussion