
Voyage AI introduces token-count-based batching to optimize embedding model inference for short queries, leveraging padding removal techniques and Redis-based queueing. This approach reduces GPU latency by half while cutting resource usage, addressing inefficiencies in search and recommendation systems.
Embedding model inference for short, frequent queries—common in search engines and recommendation systems—often suffers from high latency and low efficiency. These queries, typically under 300 milliseconds, are memory-bound due to their skewed token-length distribution and spiky traffic patterns. Traditional sequential processing wastes resources on padding tokens, where GPU compute scales with padded sequence lengths rather than actual content. Voyage AI by MongoDB tackled this by implementing token-count-based batching, a method that groups queries by total token count to minimize overhead and maximize throughput.

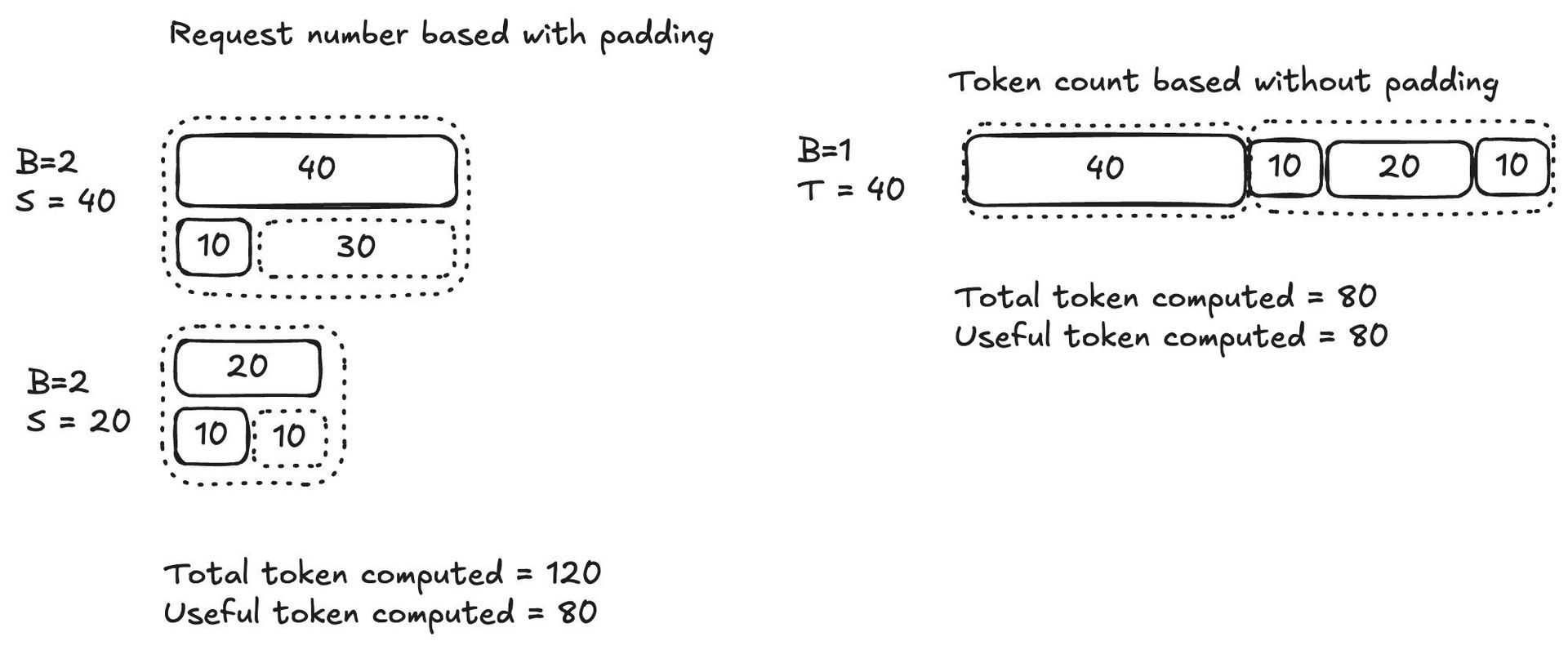
Padding removal, supported by inference engines like vLLM and SGLang, is foundational to this approach. Instead of padding sequences to a fixed length, engines concatenate tokens into a single "super sequence," using attention masks to isolate individual queries. This shifts computation to scale with the total token count (T), not batch size multiplied by padded length (B × S), reducing wasted cycles. As Voyage AI engineers noted: "Inference time now tracks T rather than B × S, aligning GPU work with what matters."
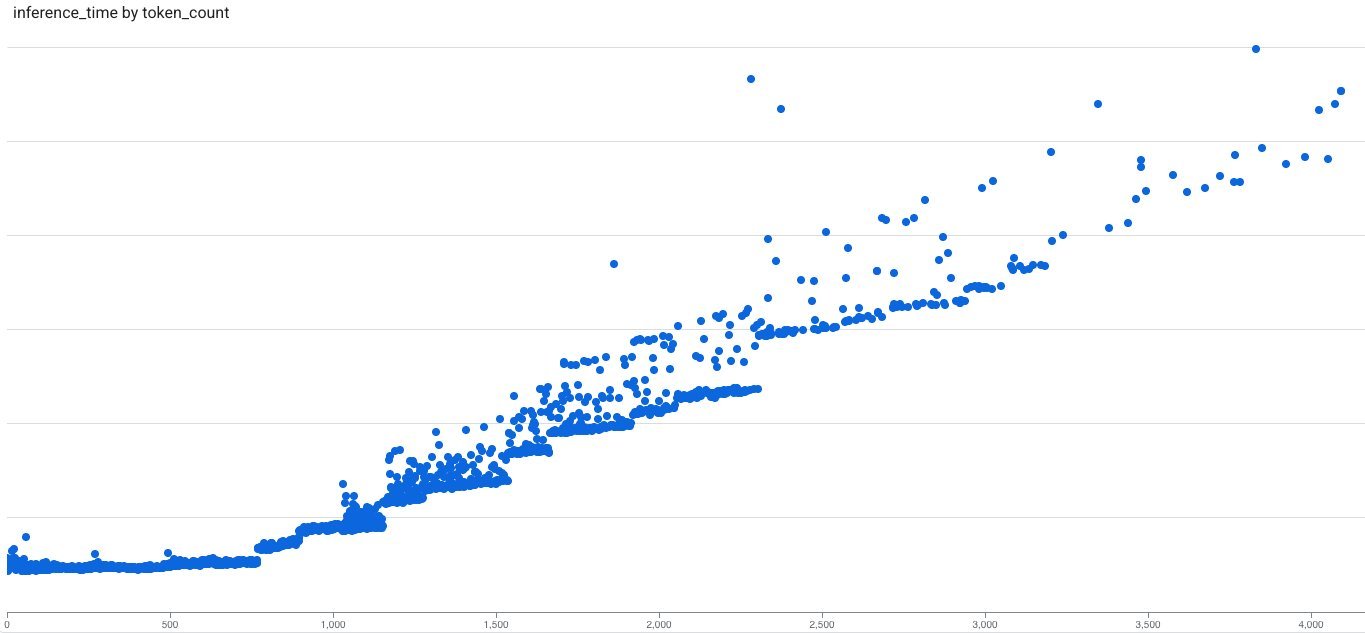
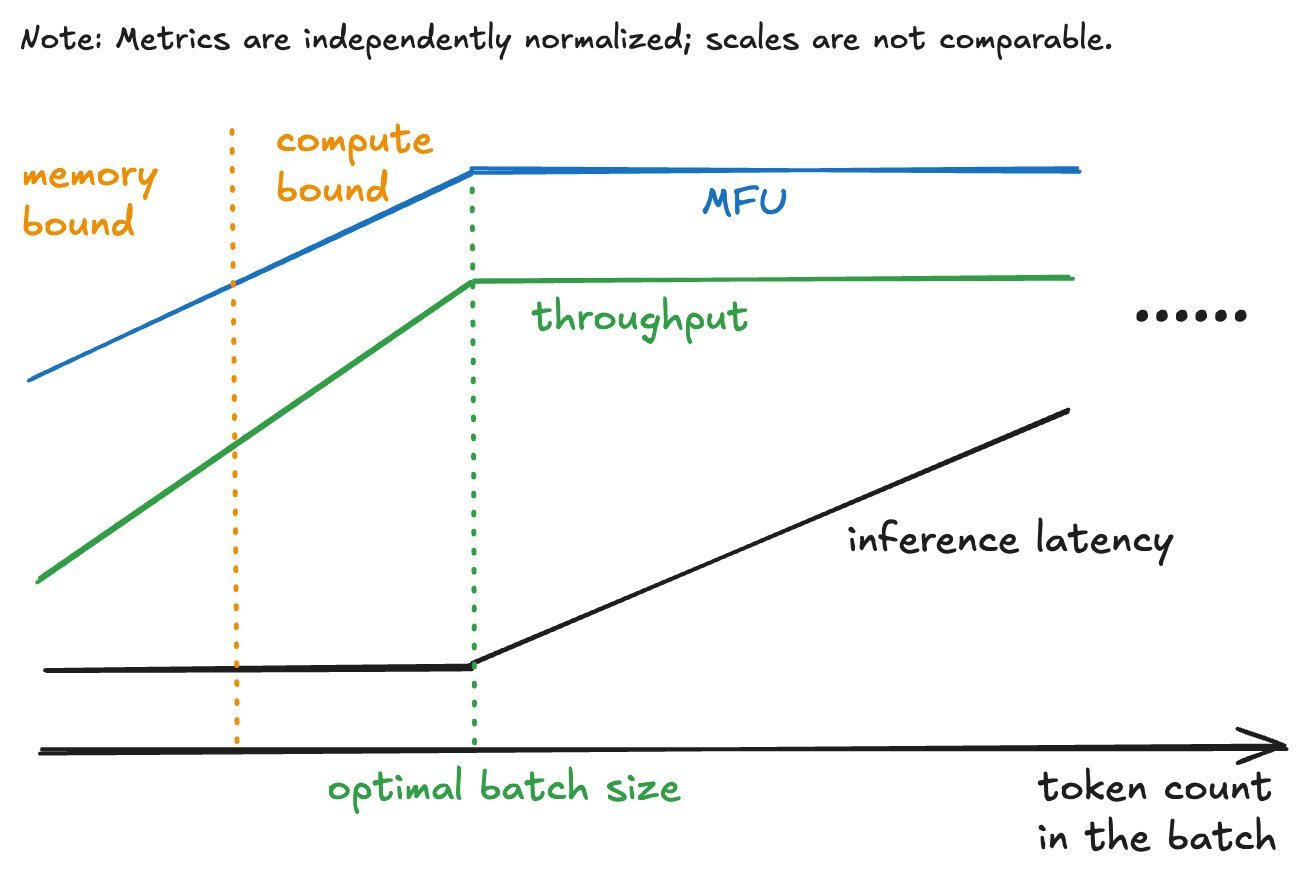
Token-count-based batching improves upon time-window or request-count methods, which often create under-filled or over-sized batches. By targeting an optimal batch size—determined by profiling latency saturation points—Voyage AI batches queries until the cumulative token count hits a threshold (e.g., 600 tokens for their voyage-3 model on A100 GPUs). Below this point, latency remains flat as fixed overheads dominate; beyond it, latency scales linearly. This moves inference from memory-bound to compute-bound regimes, boosting Model FLOPs Utilization (MFU) and throughput.
Implementing this required a queue system that peeks and batches requests atomically by token count. General brokers like Kafka lacked token-aware batching, so Voyage AI used Redis with Lua scripts to enqueue requests as token_count::timestamp::query and fetch batches up to the optimal size. This design ensures stability during traffic spikes and minimizes queuing delays. As illustrated in the system diagram, model servers atomically claim batches, reducing partial fills and handling failures gracefully.
Production results were striking: Compared to a non-batched Hugging Face pipeline, Voyage AI's solution cut GPU inference latency by 50% while using three times fewer GPUs. Throughput surged up to 8×, with P90 latency dropping by over 60 milliseconds under load. The efficiency gains stem from reduced padding, better overhead amortization, and higher MFU. For developers, this translates to lower operational costs and more responsive AI applications, reinforcing how targeted batching strategies can transform embedding inference.
Source: Voyage AI Engineering Blog
Comments
Please log in or register to join the discussion