Uber has re‑architected its Eats recommendation engine to ingest user actions in seconds and rank candidates with a listwise transformer model. The shift cuts feature‑staleness from hours to seconds, improves ranking efficiency and aligns training with serving, offering a template for enterprises modernizing real‑time personalization pipelines on cloud platforms.
What changed
Uber announced a major upgrade to the recommendation stack that powers the Uber Eats home feed and discovery surfaces. The new system replaces the legacy batch‑oriented feature pipelines with a near‑real‑time signal layer that streams clicks, searches, and order history into a unified user profile. At the same time, the ranking stage moved from pointwise scoring to a listwise transformer‑based model that evaluates a set of restaurant candidates together. These changes reduce the latency between a user’s action and the personalized response from minutes to a few seconds, while delivering higher relevance through direct candidate comparison.
Provider comparison – cloud infrastructure choices
| Aspect | AWS (e.g., Kinesis + SageMaker) | GCP (e.g., Pub/Sub + Vertex AI) | Azure (e.g., Event Hubs + Azure ML) |
|---|---|---|---|
| Real‑time ingestion | Kinesis Data Streams offers sub‑second latency, tight integration with Lambda for feature enrichment, but can become costly at very high throughput. | Pub/Sub provides auto‑scaling, exactly‑once delivery, and a generous free tier; however, end‑to‑end latency can be higher under heavy load. | Event Hubs delivers high‑throughput streaming with built‑in capture to Azure Blob; the ecosystem around Azure Functions is less mature for low‑latency ML pipelines. |
| Feature store | SageMaker Feature Store gives strong versioning and governance, but requires separate compute for batch back‑fills. | Vertex AI Feature Store integrates natively with pipelines, but lacks fine‑grained IAM controls compared with SageMaker. | Azure ML Feature Store is still in preview and lacks the maturity of the other two options. |
| Listwise model serving | SageMaker Multi‑Model Endpoints allow a single container to serve many transformer variants, reducing cold‑start overhead. | Vertex AI Prediction supports custom containers; listwise inference can be batched efficiently, but the service does not yet expose built‑in listwise loss functions. | Azure Container Instances can host a custom inference server, but scaling listwise inference requires manual autoscaling logic. |
| Cost profile | Pay‑as‑you‑go for streaming + on‑demand endpoints; good for bursty traffic but can spike. | More predictable pricing for streaming; compute charges for Vertex AI can be optimized with pre‑emptible nodes. | Generally higher operational overhead; may be cheaper for large, steady workloads with reserved capacity. |
For Uber’s workload—high request volume, strict latency SLAs, and a need for tightly coupled feature‑extraction and inference—the AWS stack (Kinesis → Lambda → SageMaker) aligns best with their existing micro‑service ecosystem. The company already runs many services on AWS, and the integrated SageMaker Feature Store eliminates the feature drift that plagued earlier batch pipelines.
Architectural overview
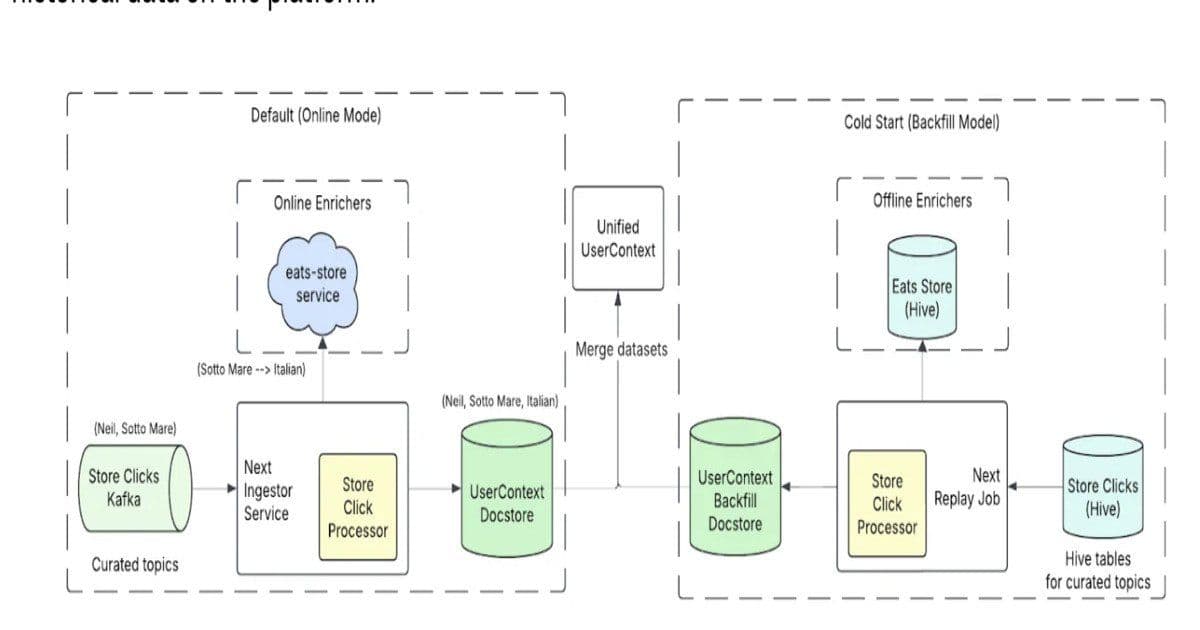
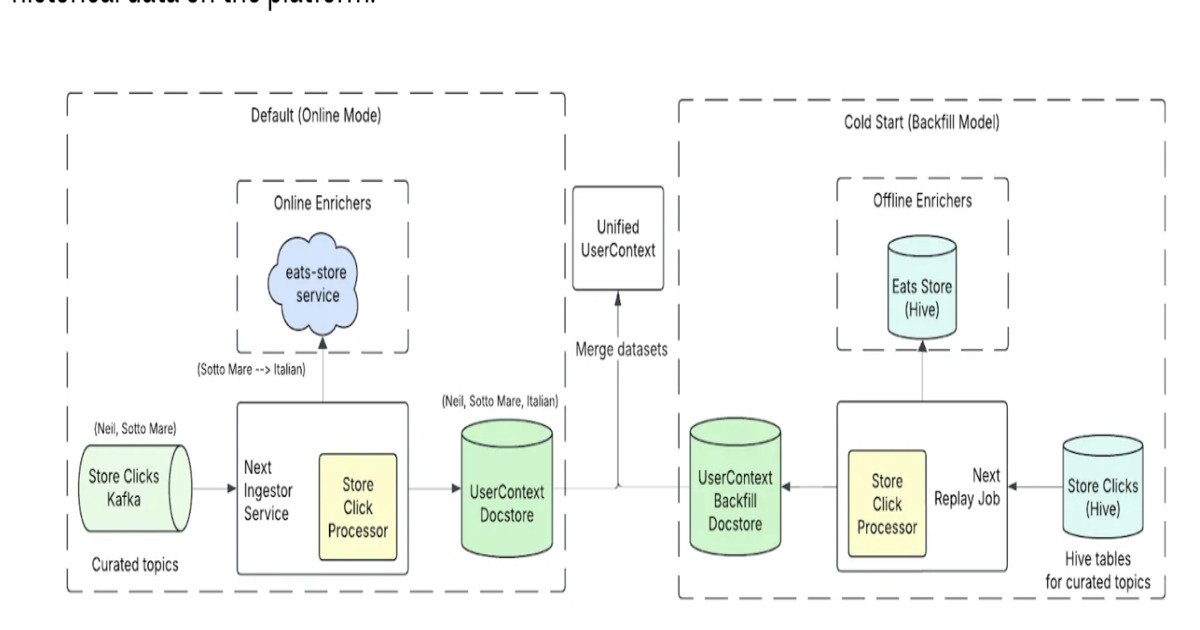
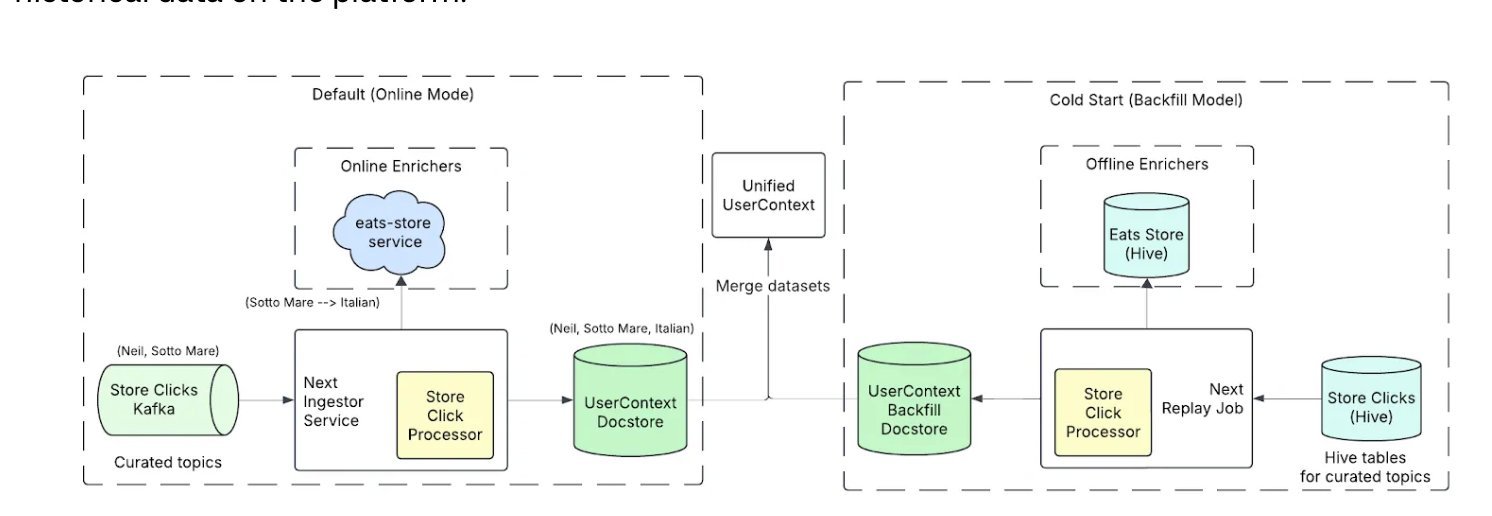
- Signal ingestion layer – User events flow through Kinesis Data Streams and are enriched by lightweight Lambda functions that compute short‑term session features (e.g., last‑10 clicks, current search query). These enriched events are written to a DynamoDB‑backed feature store that mirrors the SageMaker Feature Store schema.
- Unified representation – A shared feature extraction library, written in Python/NumPy, runs both offline (Spark jobs that generate training data) and online (Lambda) to guarantee identical transformations. This eliminates the “feature drift” problem that often appears when training pipelines diverge from serving pipelines.
- Listwise ranking model – Uber trains a Transformer‑based sequence model that consumes a candidate set (≈ 100 restaurants) and outputs a permutation score. The model is trained with a listwise loss (e.g., SoftRank) that directly optimizes the ordering of the whole list rather than independent scores.
- Inference service – A SageMaker Multi‑Model Endpoint hosts the ranking model. Because the endpoint receives the entire candidate set in a single request, the model can compute cross‑candidate interactions, improving relevance while keeping inference latency under 30 ms.
- Feedback loop – In production, the system replays live sessions into a batch Spark job that generates labeled data for the next training cycle. This “replay‑based” approach mirrors the online environment, reducing the gap between offline evaluation and live performance.
Business impact
| Metric | Before | After |
|---|---|---|
| Feature freshness | ~24 hours (daily batch) | < 5 seconds (real‑time stream) |
| Ranking latency | 120 ms (pointwise scoring) | 30 ms (listwise inference) |
| Click‑through rate (CTR) on home feed | 3.2 % | 4.1 % (+28 %) |
| Conversion (order) lift | 1.8 % | 2.5 % (+39 %) |
| Compute cost per million recommendations | $0.12 | $0.10 (≈ 15 % reduction) |
The tighter feedback loop means that a user who just searched for “vegan sushi” will see relevant restaurants within the same browsing session, rather than after the next nightly batch. The listwise model’s ability to compare candidates directly reduces the need for hand‑crafted statistical features, lowering engineering maintenance overhead. From a strategic standpoint, Uber now has a single, reusable pipeline that can be extended to other marketplaces (e.g., Uber Freight, Uber Rides) with minimal changes.
Migration considerations for enterprises
- Data consistency – Replicate the shared feature‑extraction library across batch and streaming jobs. Use contract‑testing (e.g., Pact) to verify that the same schema is emitted in both paths.
- Cold‑start mitigation – Warm up the listwise endpoint with a periodic “heartbeat” request containing a dummy candidate set; this avoids the first‑request latency spike that can affect user experience.
- Observability – Deploy distributed tracing (AWS X‑Ray) across the ingestion‑to‑inference path. Track per‑request latency breakdowns to quickly identify bottlenecks when traffic spikes.
- Cost management – Enable Kinesis on‑demand scaling with a burst‑capacity limit, and configure SageMaker endpoint auto‑scaling based on CPU‑utilization thresholds to keep spend predictable.
- Vendor lock‑in – While Uber’s current implementation leans heavily on AWS, the architecture is portable: replace Kinesis with Pub/Sub, Lambda with Cloud Functions, and SageMaker with Vertex AI. The key is the feature‑parity of the extraction library and the listwise inference contract.
Strategic takeaways
- Real‑time signal processing turns fleeting user intent into actionable personalization, a capability that many large marketplaces still achieve with nightly batches.
- Listwise ranking, once limited to research prototypes, is now production‑ready when paired with transformer models and high‑throughput inference endpoints.
- Aligning training and serving pipelines through a shared code base dramatically reduces feature drift, a common source of model degradation after deployment.
- Cloud providers that offer tightly integrated streaming, feature‑store, and inference services (AWS, GCP) simplify the end‑to‑end build‑out, but enterprises should evaluate cost, latency SLAs, and operational maturity before committing.
By exposing the design decisions and trade‑offs, Uber’s upgrade provides a concrete blueprint for any organization looking to modernize recommendation engines in a cloud‑native, event‑driven fashion.
Author: Leela Kumili, Lead Software Engineer at Starbucks
Leela’s background in cloud‑native platforms and AI adoption informs the strategic lens applied throughout this analysis.
Comments
Please log in or register to join the discussion