
The Ultra Ethernet Consortium's 1.0.1 specification rearchitects data-center networking for million-node AI/HPC clusters, eliminating packet-ordering constraints while maintaining Ethernet/IP compatibility to address 30% performance losses in current systems.

Traditional Ethernet's architecture is hitting fundamental scalability limits in hyperscale AI and high-performance computing clusters. As cluster sizes balloon toward 100,000+ nodes—with projections exceeding one million—TCP's ordered-delivery requirement and reactive congestion control create crippling bottlenecks. Packet collisions, flow-tracking overhead, and false congestion alerts degrade performance by up to 30% in GPU-dense environments according to consortium data. This inefficiency costs operators millions in underutilized hardware.
Enter Ultra Ethernet (UE), architected by the Ultra Ethernet Consortium (UEC) founded by Meta, Microsoft, Oracle, and now backed by over 100 companies including AMD, Intel, and Broadcom. Released in mid-2025, the UE 1.0.1 specification redefines data-center networking by decoupling packet delivery from semantic ordering—all while maintaining compatibility with existing IEEE 802.3 Ethernet physical layers and IP infrastructure.

Architectural Overhaul: Breaking the Order Barrier
Legacy RDMA solutions like RoCE v2 forced packets along rigid single paths, causing congestion in burst-heavy AI workloads. UE eliminates this constraint through a layered approach:
Physical Layer: Uses standard Ethernet cabling (DAC, AOC, fiber) but enhances it with:
- 15% lower-latency link initialization
- Enhanced Forward Error Correction (FEC) reducing retries by 40%
- Nanosecond-precision timing for distributed synchronization
Link Layer: Introduces three optional hardware-accelerated features:
- Credit-Based Flow Control (CBFC): Prevents switch buffer overflows
- Link Layer Retry (LLR): Sub-microsecond local error correction
- Packet Trimming: Drops tail packets during congestion, preserving throughput
Transport Layer: The revolutionary Ultra Ethernet Transport (UET) protocol enables out-of-order delivery via:
- Semantic Sub-layer: Tags packets with application context
- Packet Delivery Sub-layer: Handles acknowledgments/retransmissions
- Congestion Management: Multi-path spraying across 8-32 routes
- Transport Security: Integrated MACsec encryption at line rate
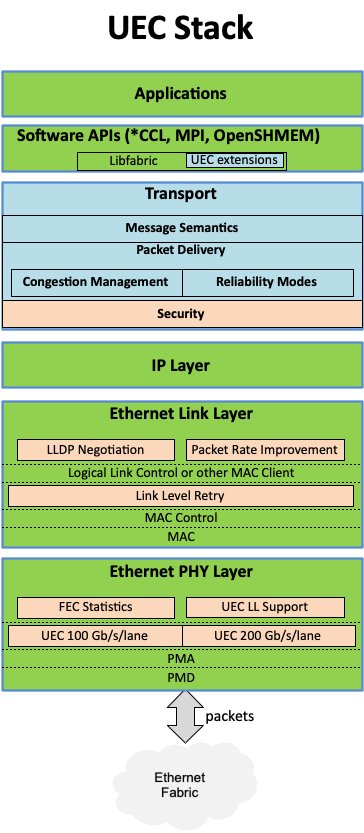
This separation allows packets to traverse diverse paths while ensuring end-to-end integrity. Benchmarks show UE achieving 95% wire utilization at 400Gb/s versus 60-70% for RoCEv2 in 10,000-node simulations.
Software and Storage Integration
The Storage Layer optimizes NVMe-oF and RDMA protocols by integrating directly with UET's congestion control, reducing storage I/O latency by 50% in clustered configurations. Meanwhile, the Software Stack incorporates:
- Libfabric API: Enables zero-copy transfers bypassing CPU
- OpenConfig/YANG: Standardizes telemetry across multi-vendor fleets
- Fabric Manager: Auto-discovers topology and orchestrates 100,000+ nodes

Deployment Timeline and Hardware Readiness
While UE 1.0.1 is ratified, full compliance remains emergent. AMD's Pensando Pollara 400 AI NIC exemplifies current "UE-ready" hardware—supporting multipath spraying and out-of-order handling but omitting optional features like packet trimming. UEC's Compliance Working Group is finalizing validation suites for 2026 certification.

Three critical gaps remain in active development:
- Congestion Control: Deadline-aware algorithms for time-sensitive AI workloads
- LLR/CBFC Interoperability: Ensuring consistent behavior across vendor silicon
- Management Scalability: Real-time telemetry aggregation at million-node scale
The consortium projects initial commercial deployments in 2027, targeting 800Gb/s links. With AI cluster sizes doubling every 12-18 months, UE's architecture offers a scalable alternative to proprietary interconnects—potentially saving $2B annually in hyperscale OPEX through reduced overhead and improved GPU utilization. As one UEC architect stated: "This isn't an Ethernet tweak. It's a reinvention for the age of exascale AI."
Comments
Please log in or register to join the discussion