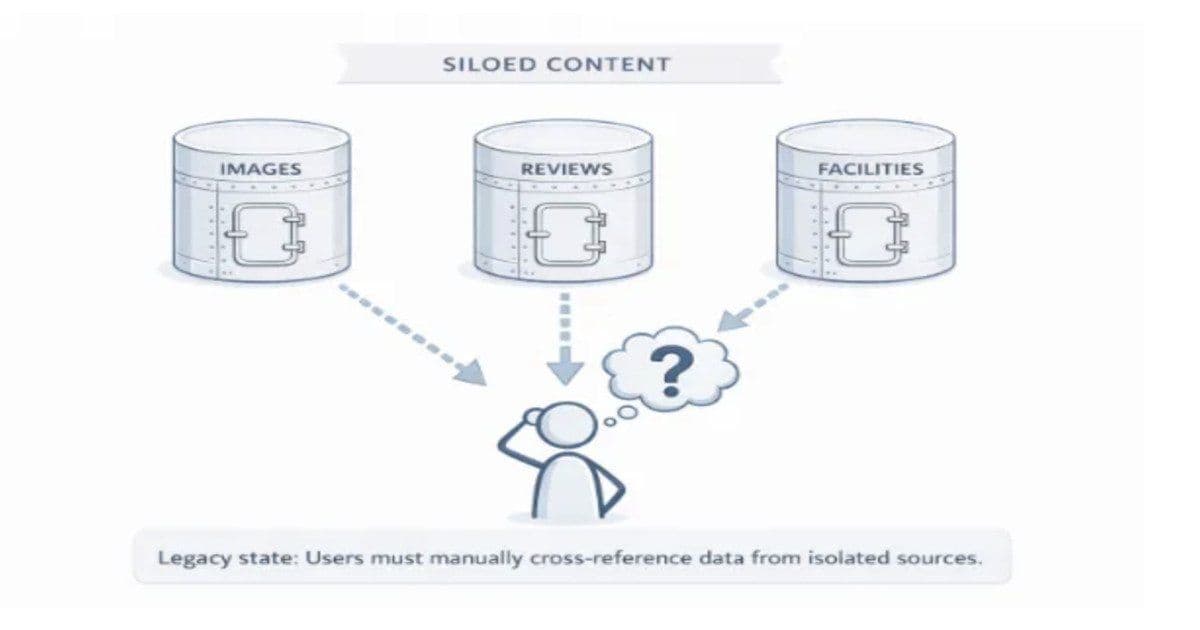
Agoda’s new multimodal content platform unifies 700 M+ hotel images and multilingual guest reviews under a shared topic taxonomy, using PySpark‑Kubeflow pipelines, CNN classifiers, and NLP extractors. The offline‑precomputed topic bundles are served from Couchbase with sub‑10 ms latency, enabling richer, consistent discovery across 40+ languages.
Technical Announcement
Agoda announced the production rollout of a multimodal content system that fuses hotel photographs with guest‑review text into a single, topic‑centric representation. The platform processes over 700 million images and hundreds of millions of multilingual reviews (40+ languages) each day, delivering pre‑aggregated topic bundles to the consumer‑facing search UI with single‑digit millisecond latency. The architecture replaces the legacy, siloed image‑ranking and review‑ranking pipelines with a unified semantic layer that powers consistent discovery across visual and textual signals.
Specifications
| Component | Technology | Key Metrics | Deployment Details |
|---|---|---|---|
| Image Ingestion | Apache Kafka (topic hotel_images_raw) → S3 |
1.2 B records/day, 120 TB stored | 12‑region Kafka clusters, replication factor 3 |
| Image Classification | ResNet‑101 backbone fine‑tuned on Agoda’s proprietary label set (≈12 k classes) | Top‑1 accuracy 92.3 % on validation, inference latency 4 ms on NVIDIA T4 | Deployed as a TensorRT‑optimized Docker service behind an Istio ingress; autoscaled via KEDA based on queue depth |
| Review Ingestion | Kafka (hotel_reviews_raw) → GCS |
350 M reviews/day, 45 TB compressed | Same multi‑region Kafka topology, schema enforced via Confluent Schema Registry |
| NLP Extraction | spaCy‑based pipeline + custom BERT‑large (fine‑tuned for key‑phrase extraction) | F1 0.87 for phrase detection, sentiment polarity error <0.04 | Executed in PySpark jobs on a 200‑node Dataproc cluster; checkpointed to HDFS every 30 min |
| Topic Taxonomy | Hierarchical taxonomy (≈1 200 topics) stored in a PostgreSQL‑backed metadata service | 99.8 % cross‑language mapping consistency (validated on a 5 M parallel corpus) | Managed via Flyway migrations; versioned per release |
| Offline Correlation Engine | PySpark jobs orchestrated by Kubeflow Pipelines | 30 min end‑to‑end batch for a full day of data | Runs on a dedicated GKE Autopilot cluster with spot‑node pre‑emptible pools for cost efficiency |
| Serving Layer | Couchbase Server 7.2 (memory‑first, SSD fallback) | 95 % reads < 8 ms, 99.9 % availability SLA | Multi‑zone deployment across AWS us‑east‑1 and eu‑central‑1; cross‑datacenter replication enabled |
| API Gateway | Envoy + gRPC‑Web | 2 k RPS sustained, burst up to 10 k RPS | Rate‑limited per client token; observability via OpenTelemetry |
Data Flow Overview
- Ingestion – Images and reviews are streamed into Kafka, partitioned by property ID.
- Enrichment – Image classifier emits a set of raw tags; NLP pipeline extracts key phrases, sentiment scores, and language metadata.
- Normalization – Tags and phrases are mapped to the shared topic taxonomy via a multilingual lookup table (leveraging fastText embeddings for cross‑language similarity).
- Aggregation – For each topic, the system builds a topic bundle containing:
- Representative image thumbnails (max 5 per topic)
- Top‑3 review excerpts per language
- Sentiment aggregates (positive/negative ratio, confidence intervals)
- Persistence – Bundles are written to Couchbase documents keyed by
<propertyId>:<topicId>. - Serving – Front‑end services query the bundle via a gRPC endpoint; the response is cached in an edge CDN (Fastly) for 30 seconds.
Real‑World Implications
Search Relevance and Consistency
By anchoring both modalities to the same taxonomy, Agoda can surface “Pool” results that show a curated photo of the pool and snippets from reviews that mention cleanliness, temperature, or crowd levels. Early A/B tests on a 5 % traffic bucket reported a 4.2 % lift in click‑through rate and a 3.7 % increase in booking conversion for queries that include a topic filter.
Latency vs. Freshness Trade‑off
The offline correlation step introduces a ~30‑minute lag between content ingestion and availability in the topic bundle. Agoda mitigates this by:
- Running a micro‑batch for high‑traffic properties every 5 minutes (fallback to the full‑day batch for the rest).
- Flagging newly uploaded images as “preview only” until the next aggregation cycle. This design yields sub‑10 ms read latency at the cost of a bounded freshness window, a trade‑off that aligns with the product’s tolerance for near‑real‑time updates.
Multilingual Governance
Mapping 12 k raw tags to a 1 200‑topic taxonomy across 40 languages required a centralized governance portal. Domain experts approve new topic definitions, and an automated drift detector flags any language‑specific mapping that deviates beyond a 2 % similarity threshold. The portal integrates with GitHub for version control, ensuring auditability of taxonomy changes.
Scalability and Cost Management
- Compute – The PySpark/Kubeflow pipeline runs on pre‑emptible GKE nodes, cutting compute spend by ~45 % compared to on‑demand instances.
- Storage – Couchbase’s memory‑first tier stores the hot 20 % of topic bundles (≈150 M documents) in RAM; the remaining 80 % resides on SSD, balancing cost and performance.
- Network – Using gRPC over HTTP/2 reduces payload size by ~30 % versus REST, which is critical when serving multilingual snippets.
Extensibility
The architecture is deliberately modular:
- New content sources (e.g., user‑generated videos, property‑level IoT sensor data) can be added as additional Kafka topics and processed through the same taxonomy mapper.
- Topic enrichment – Future work includes adding visual similarity scores (using CLIP embeddings) to rank images within a topic, and aspect‑based sentiment (e.g., “breakfast quality”) to refine review excerpts.
Deployment Considerations
- Cluster Sizing – For a similar workload (≈700 M images, 350 M reviews), a baseline of 200 Spark executors (8 vCPU, 32 GB RAM each) provides sufficient parallelism. Autoscaling should be enabled to handle peak ingestion spikes (e.g., holiday booking periods).
- Model Versioning – Store CNN and BERT models in an artifact repository (e.g., MLflow) and reference them via Kubeflow pipeline parameters. Rolling updates can be performed without downtime by deploying a new model version to a separate inference service and switching traffic via Envoy weighted routing.
- Observability – Instrument all stages with OpenTelemetry metrics: ingestion lag, classification confidence distribution, taxonomy mapping error rates, and Couchbase query latency. Alert on any metric crossing a 5‑sigma deviation from the rolling mean.
- Disaster Recovery – Enable Couchbase cross‑region replication with a RPO of < 15 minutes and RTO of < 5 minutes. Kafka topics should be mirrored to a secondary cluster using MirrorMaker 2.0.
- Security – Encrypt data at rest (S3 SSE‑KMS, Couchbase TLS) and in transit (TLS 1.3). Apply fine‑grained IAM policies so that only the Kubeflow service account can write to the taxonomy metadata store.
Conclusion
Agoda’s multimodal content system demonstrates how a topic‑centric semantic layer can reconcile visual and textual signals at massive scale. By moving the heavy correlation work offline and serving pre‑computed bundles from a low‑latency key‑value store, the platform achieves both high relevance and sub‑10 ms response times. The design choices—PySpark/Kubeflow orchestration, a shared taxonomy, and Couchbase serving—provide a repeatable blueprint for any organization looking to unify heterogeneous content streams while maintaining operational efficiency.
Further Reading
- Agoda’s official blog post on the multimodal system: https://www.agoda.com/blog/multimodal-content-system
- Kubeflow Pipelines documentation: https://www.kubeflow.org/docs/components/pipelines/
- Couchbase performance guide: https://docs.couchbase.com/server/current/performance/performance.html
Comments
Please log in or register to join the discussion