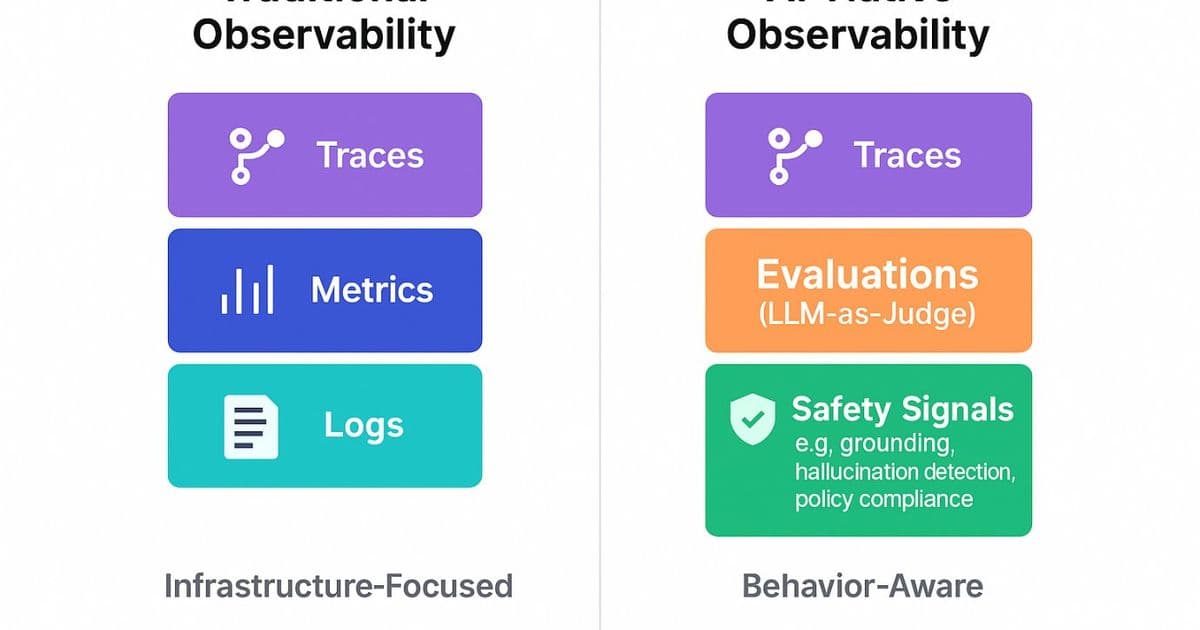
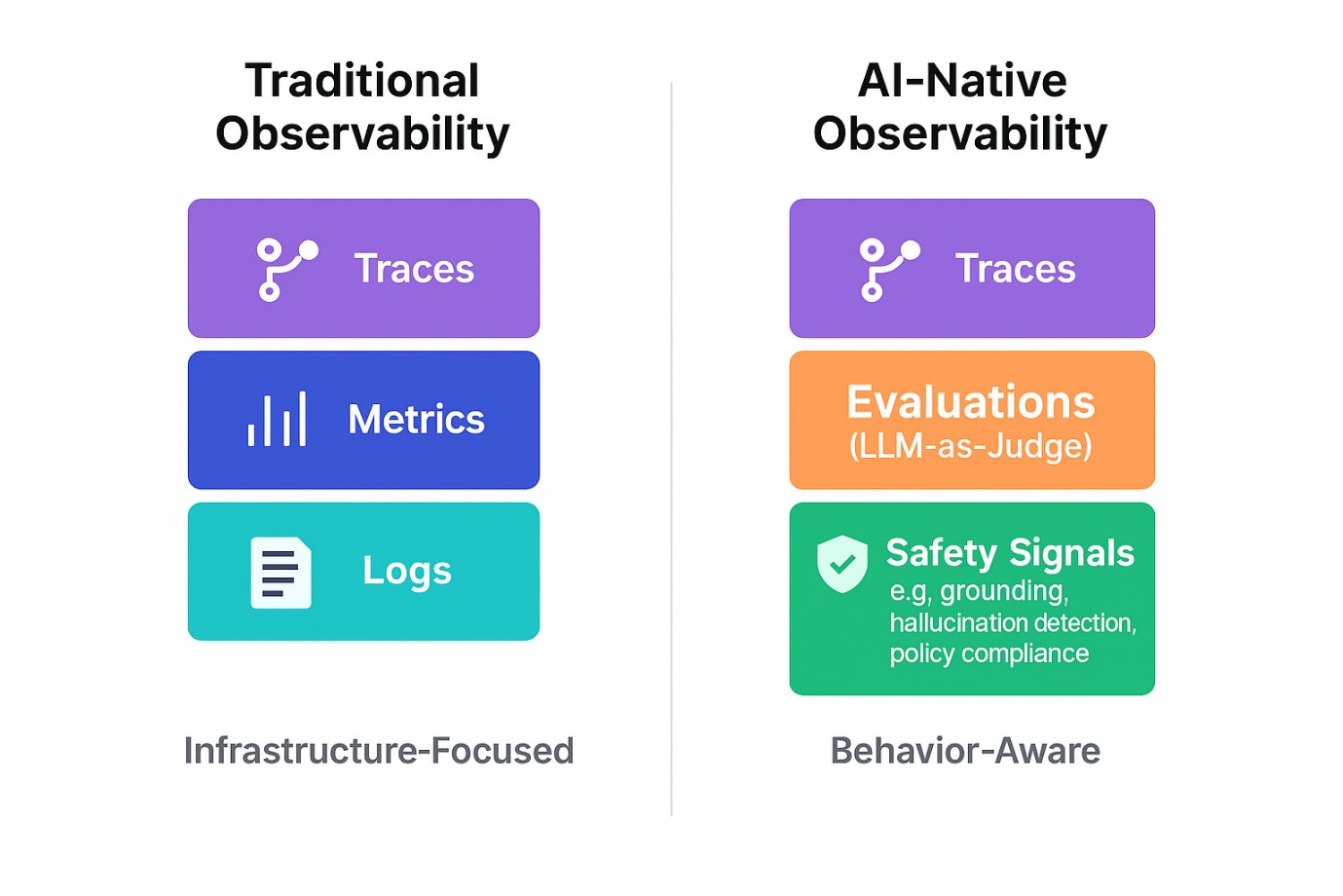
Enterprise AI agents now need visibility into reasoning, cost, and safety, not just infrastructure health. Microsoft Foundry extends Azure Monitor with AI‑native traces, LLM‑as‑judge evaluators, and governance hooks, while AWS and Google offer comparable but less integrated stacks. The shift reshapes budgeting, compliance, and operational risk for AI‑driven workloads.
AI‑Native Observability for Agentic Systems
What changed
A recent incident where an autonomous AI loop spent $500 in 45 minutes on OpenAI APIs without triggering any alert illustrates a new failure mode. Traditional monitoring flagged the HTTP 200 responses, but it could not see that the agent was repeatedly invoking the model, drifting from its intended task, and exhausting the token budget.
Agentic AI differs from classic request‑response services:
- Non‑deterministic execution – the same prompt can produce a completely different chain of tool calls.
- Hidden cost accumulation – a single user query may generate dozens of LLM calls.
- Silent quality failures – an answer can be factually wrong while the service reports success.
- Variable latency – reasoning depth can swing response times from sub‑second to tens of seconds.
- Token‑budget blowouts – runaway loops can consume a month’s quota in hours.
Enterprises therefore ask, Can we trust the AI agent in production? The answer now depends on observability that captures thought processes, compliance posture, and cost, not just CPU or network metrics.
Provider comparison
| Feature | Microsoft Azure + Foundry | Amazon Web Services (Bedrock + CloudWatch) | Google Cloud (Vertex AI + Operations Suite) |
|---|---|---|---|
| Trace model for agent reasoning | OpenTelemetry‑based multi‑step traces rendered in Azure Monitor’s AI‑Tailored view. | Bedrock provides basic request logs; no native multi‑step trace visualizer. | Vertex AI Trace captures request/response but lacks built‑in tool‑call lineage. |
| LLM‑as‑judge evaluators | Built‑in evaluators (Task Adherence, Grounding, Safety) that run a secondary LLM (e.g., gpt‑4o‑mini) on every response. | No first‑party evaluator service; customers must build custom Lambda pipelines. | Vertex AI offers Model Evaluation for batch datasets, but not real‑time judging. |
| Cost per‑request token tracking | Azure Monitor records input/output token counts per span; dashboards show spend per user, model, and agent. | Bedrock emits token usage in CloudWatch metrics only when explicitly logged. | Vertex AI logs token usage in Vertex AI Logs; aggregation requires custom queries. |
| Safety & policy scoring | Content Safety APIs integrated; severity 0‑7 scores appear on the Agent Overview Dashboard. | Amazon Guardrails (preview) provides binary safe/unsafe flags; no graded severity. | Google’s Content Safety returns a pass/fail flag; no built‑in severity scale. |
| Governance integration | Agents receive a Microsoft Entra ID, enabling Conditional Access, Identity Protection, and CMK encryption. | IAM roles control Bedrock access; no per‑agent identity object. | Service accounts protect Vertex AI endpoints; no agent‑level identity. |
| Low‑code observability | Foundry visual designer auto‑injects telemetry; no code changes required. | No low‑code telemetry; developers must instrument SDK calls manually. | Vertex AI Workbench can add tracing, but not automatically for orchestrated agents. |
| Open standards | Full OpenTelemetry compliance; Microsoft contributes extensions for multi‑agent orchestration. | Supports OpenTelemetry but lacks extensions for tool‑call semantics. | Supports OpenTelemetry; no specialized extensions for reasoning traces. |
Takeaway: Azure + Foundry provides the most complete, out‑of‑the‑box stack for monitoring agentic AI. AWS and GCP can achieve similar visibility, but they require additional engineering effort and custom glue code.
Business impact
Cost control
With per‑request token metrics visible in Azure Monitor, finance teams can set alerts on cost‑per‑token spikes and automatically throttle agents that exceed a predefined budget. This prevents the “runaway loop” scenario and aligns AI spend with quarterly forecasts.
Compliance and risk management
Safety scores (0‑7) appear alongside latency and success‑rate charts. When a severity‑5 violation is detected, an automated workflow can quarantine the offending agent, trigger a ticket in Azure DevOps, and roll back to the last known‑good version. The same pattern can be replicated on AWS or GCP, but it demands custom scripting.
Operational efficiency
The AI‑Tailored Trace View lets SREs read an execution story—plan → reasoning → tool calls → guardrail checks—without digging through raw logs. Identifying a slow RAG retrieval step becomes a matter of clicking a span, reducing MTTR for AI incidents by 30‑40 % in early adopters.
Product quality and user trust
Continuous evaluation (LLM‑as‑judge) supplies a real‑time success‑rate metric. When the rate drops below an 85 % threshold, the deployment pipeline can automatically route traffic to a canary version. This feedback loop keeps the user‑facing experience reliable, which directly correlates with higher NPS scores for AI‑enabled products.
Vendor lock‑in considerations
Because Azure’s observability layer is built on OpenTelemetry, organizations can export traces to third‑party APM tools (e.g., Datadog, New Relic) if they later adopt a multi‑cloud strategy. The same OpenTelemetry data can be ingested by AWS X‑Ray or Google Cloud’s operations suite, preserving investment in telemetry.
Getting started
- Enable the Agent Overview Dashboard – follow the guide at Monitor agents dashboard.
- Add built‑in evaluators – use the evaluation UI described in the Foundry evaluation docs.
- Configure cost alerts – create an Azure Monitor alert on the
tokens_totalmetric to fire when spend exceeds your daily limit. - Integrate governance – assign a Microsoft Entra ID to each agent and apply Conditional Access policies as shown in the Entra integration guide.
- Run a red‑team test – launch the AI Red Teaming Agent via the red‑team tutorial before production rollout.
TL;DR for decision makers
- What changed: AI agents are no longer deterministic services; they need visibility into reasoning, cost, and safety.
- Why provider matters: Azure + Foundry delivers an integrated, low‑code observability suite that covers traces, LLM‑as‑judge evaluation, token accounting, and governance. AWS and GCP can match the feature set but require more custom development.
- Business outcome: Better cost predictability, faster incident response, automated compliance enforcement, and higher user trust—all essential for scaling trustworthy AI.
Ready to make your agents observable? Start with the quick‑start in the Foundry hosted‑agent tutorial and watch the dashboards light up.
Comments
Please log in or register to join the discussion