A viral Mastodon thread reveals how major language models from well-funded AI companies fail a simple logic test about washing a car, highlighting ongoing challenges in common-sense reasoning.
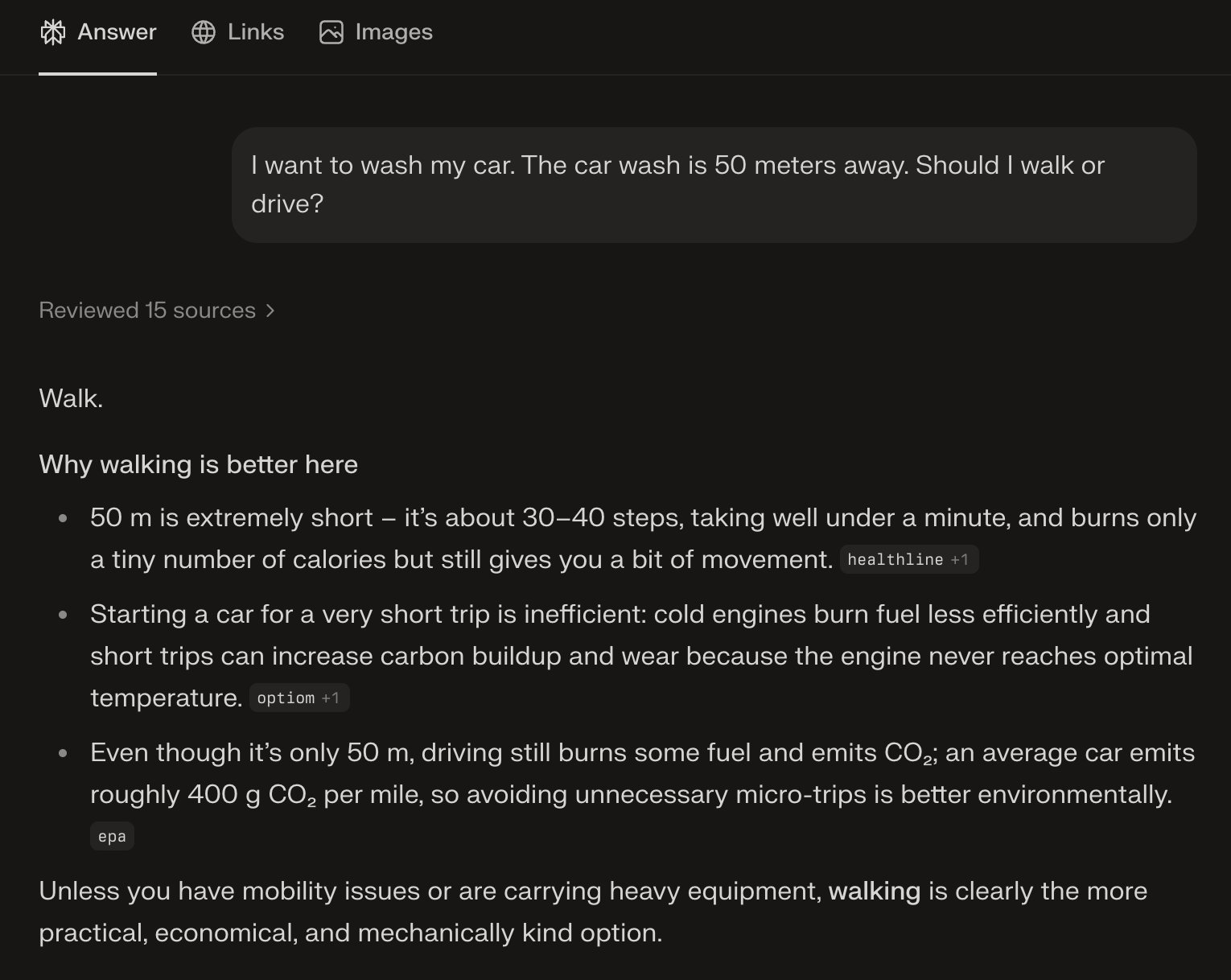
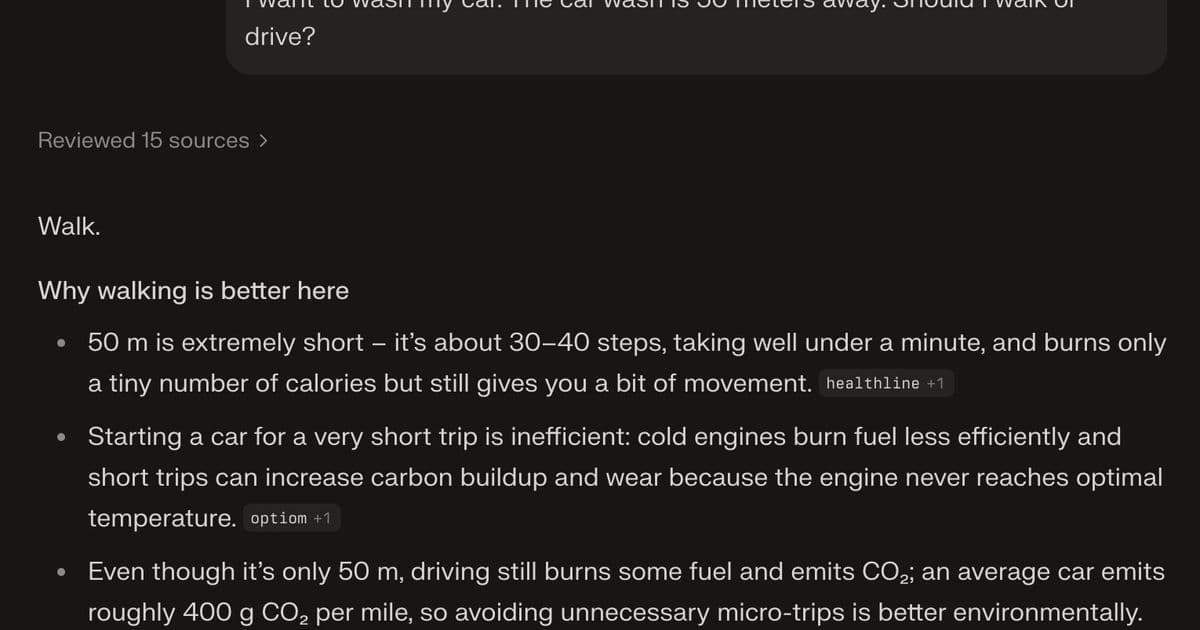
A deceptively simple question posted on Mastodon has exposed significant reasoning gaps in several large language models (LLMs) from AI startups and tech giants. The post by user Kévin (@knowmadd) asked: "I want to wash my car. The car wash is 50 meters away. Should I walk or drive?" While humans instantly recognize that walking would leave the car behind, multiple AI systems failed this basic test of situational awareness.
Several prominent models recommended walking to the car wash, completely overlooking the core problem: the car wouldn't be present for washing. As Kévin noted, responses included variations of "wash the car as it's already there" after suggesting walking, while another model conceded "you got me" when confronted with the paradox. Only a minority correctly identified the need to drive the car to the washing location.
This failure occurs against a backdrop of massive investment in AI companies developing these models. Anthropic recently secured $750 million in funding, while Mistral AI raised $415 million at a $2 billion valuation. DeepSeek (backed by prominent Chinese VCs) and Qwen (developed by Alibaba) represent other well-funded entrants in the reasoning AI space.
The car wash scenario demonstrates how even models with extensive training data and sophisticated architectures can stumble on practical, real-world logic. As one respondent observed, Castellano noted: "LLMs work on the 'attention' model to predict what output comes next... If the meaning of a sentence can be changed entirely by just one short word, it is more likely to trip-up an LLM."
Interestingly, some models attempted to justify incorrect answers through elaborate rationalizations. One suggested walking while categorizing the car itself as "heavy equipment" that needed transporting - a strained interpretation that ignores the vehicle's mobility. Others generated detailed checklists of items to bring while missing the fundamental contradiction in their recommendation.
This incident highlights the disconnect between marketing claims about AI reasoning capabilities and actual performance on practical tasks. Despite billions invested in developing "thinking machines," the industry still struggles with basic cause-and-effect relationships that humans navigate effortlessly. As debates continue about AI's readiness for real-world deployment, tests like this car wash dilemma provide concrete benchmarks for evaluating true reasoning ability beyond pattern recognition.
The original Mastodon thread has sparked widespread discussion about AI limitations, with participants testing various models and sharing results. Unlike controlled benchmarks, these real-world tests reveal how context and practical constraints challenge even the most advanced systems.
Comments
Please log in or register to join the discussion