At WWDC26, Apple split its AI into five distinct Foundation Models. Two run locally, three run on servers, and for the first time one of them lives on Nvidia GPUs inside Google Cloud, all while Apple insists its privacy guarantees stay intact.
Apple spent two years trying to make its own AI ambitions work entirely in-house. With the third generation of Apple Foundation Models (AFM) announced at the WWDC26 keynote, the company has accepted a more pragmatic arrangement: five separate models, some running on your iPhone or Mac, some running on Apple silicon servers, and one running on Nvidia GPUs hosted in Google Cloud. It is a meaningful shift in how Apple thinks about on-device versus cloud intelligence, and it tells you a lot about where the limits of local processing currently sit.
How Apple got here
When Apple first introduced its foundation models in 2024, the setup was simpler. There was a roughly 3-billion-parameter language model that ran on the device itself, and a larger server-based model that ran through Private Cloud Compute on Apple silicon servers. Private Cloud Compute was the interesting part. The idea was to extend the privacy expectations of on-device processing into the cloud, so that even when your request left your phone, the handling of that data could be independently verified by outside security researchers. Keeping everything on Apple-controlled hardware was the whole point.
That plan ran into reality. Apple's homegrown AI efforts stumbled, the much-promoted Siri overhaul slipped, and the company eventually partnered with Google to use Gemini as part of the backbone for its next wave of features. The third-generation AFM lineup is the first concrete product of that arrangement.
The five models
The new generation breaks into five distinct models, each tuned for a different job.
On-device:
- AFM 3 Core is the direct successor to the original 3-billion-parameter dense model. Same general size, better quality.
- AFM 3 Core Advanced is the headline local model. It is natively multimodal, which powers things like expressive voices and more accurate dictation. It carries 20 billion parameters but uses a sparse architecture that activates only 1 to 4 billion of them at a time depending on the request. It is gated to Apple's most capable silicon.
Server-based:
- AFM 3 Cloud is the everyday server workhorse, tuned for speed and efficiency.
- ADM 3 Cloud (Image) handles image generation and editing. The D stands for diffusion, the same class of technique behind most modern image generators. It drives the revamped Image Playground and the advanced photo-editing tools.
- AFM 3 Cloud Pro is the most capable server model, built for demanding work like agentic tool use and complex reasoning. This is the one running on Nvidia GPUs inside Google Cloud.
Every model except AFM 3 Cloud Pro runs on Apple silicon. According to Apple, all five shared a common initial foundation before specializing, picking up audio, image understanding, long-context reasoning, and high-quality visual generation along the way.
Why a 20-billion-parameter model can run on your phone
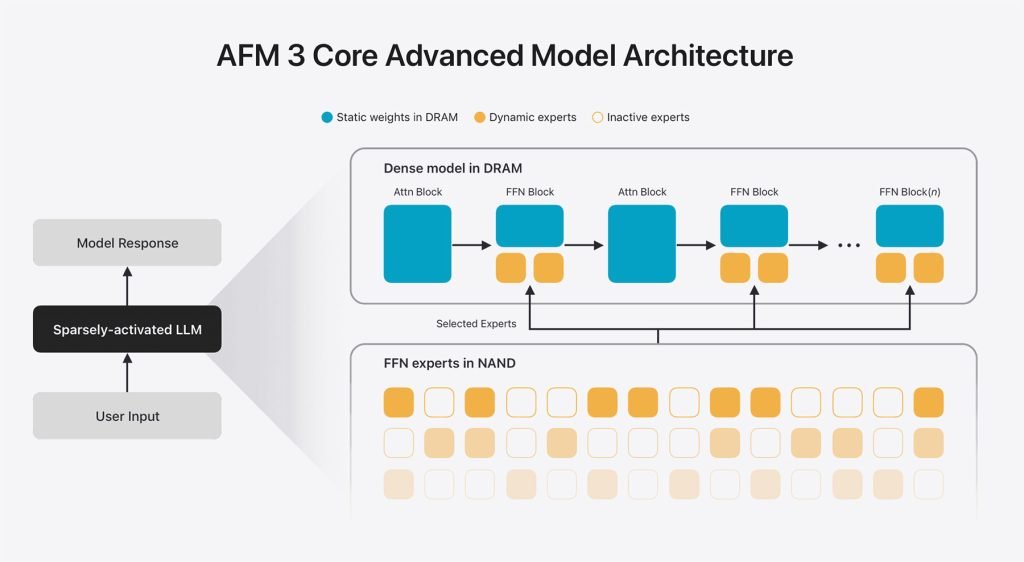
AFM 3 Core Advanced is the most technically interesting piece of the lineup, so it is worth unpacking how a 20-billion-parameter model fits onto a device at all. Most on-device models aimed at consumers stay in the low single-digit billions of parameters, because every active parameter costs memory and battery.
Apple gets around this with a sparse architecture. A dense model has to keep all of its parameters active for every single token it processes. If you have 20 billion parameters in a dense model, you pay for all 20 billion on every request. A sparse model instead routes each request through only a relevant subset of its weights. In Apple's case, that means activating just 1 to 4 billion parameters at a time, even though the full model holds 20 billion.
The concept will sound familiar if you have followed Mixture of Experts (MoE) designs, where a router picks which "expert" subnetworks handle a given input. Apple's approach is related but distinct. It draws on a technique the company calls instruction-following pruning, detailed in its research paper Instruction-Following Pruning for Large Language Models. The practical payoff is a model with the knowledge capacity of something much larger, but the runtime cost of something small enough to live on a high-end Apple device. That tradeoff, big stored capacity against small active compute, is exactly what makes large local models viable on phones and laptops.
Extending Private Cloud Compute to someone else's hardware
The arrangement with Google is the part that raises eyebrows, because Apple has spent years marketing privacy as a reason to trust its servers specifically. Running a model on Nvidia GPUs in Google Cloud means Apple no longer controls the silicon end to end. The company's answer is to extend Private Cloud Compute to third-party infrastructure for the first time, which it says it did "while maintaining Apple's powerful security and privacy protections."
Apple laid out the technical reasoning on its Security Research blog. A few details stand out. Apple says it does not rely on confidential computing alone to defend against attacks that use privileged access outside a confidential VM, including side-channel attacks. It treats every component, from firmware through the host and guest operating systems up to the application code, as part of its trusted computing base, all subject to verifiable transparency and a no-privileged-access guarantee.
To guard against supply chain tampering, Apple keeps a cryptographically verifiable, append-only ledger of every piece of Google Cloud hardware in the PCC fleet. For any component that could be used to exfiltrate user data if compromised, its software attestation is rooted in at least two separate roots of trust from independent vendors. The inference stack borrows the same architectural patterns as PCC on Apple silicon: initial network parsing for each request runs in its own isolated process and namespace, shared inference software is recycled on a short time-to-live, and attested keys live in a separate, dedicated confidential VM kept away from external inputs.
Whether that satisfies the privacy-conscious crowd that bought into Apple silicon servers as the safer option is a fair question. The engineering, at least, is more elaborate than a typical cloud deployment.
How it was trained, and how it performed

Apple says the training data was a mixture of publicly available information, data licensed or purchased from third parties, open-sourced data, data from dedicated studies, and synthetic data. The company is explicit that no user data or user interactions were part of training, and that web publishers can opt out of having their content used for foundation model training.
For evaluation, Apple leaned on human reviewers rather than leaning solely on benchmark numbers. In-house graders compared responses across instruction following, truthfulness, presentation, and image understanding, scoring new models against their predecessors where a comparison made sense.

The text results are presented across four locale groups to show consistency across international variants, using shorthand like "English" for the global English set and groupings such as "PFIGSCJK," "DNNSTV," and "AFIHHMPRTU" for the remaining supported locales. On dictation specifically, Apple says AFM 3 Core Advanced posts a positive win rate in overall quality against its existing production dictation system, with the preference holding across every individual formatting and comprehension dimension it measured.
What it means for the ecosystem
The practical takeaway for anyone living inside Apple's ecosystem is that intelligence is now tiered. Routine work stays on the device through AFM 3 Core and Core Advanced, which keeps data local and works offline. Heavier requests escalate to Apple silicon servers, and the most demanding agentic and reasoning tasks reach all the way out to Google Cloud through AFM 3 Cloud Pro. You will not pick which model answers you; the system routes the request based on what it needs.
The deeper signal is strategic. Apple clearly could not deliver its most capable server model on Apple silicon alone, at least not on the timeline it wanted, so it built a privacy framework that lets it borrow Nvidia hardware without fully abandoning its security pitch. For users, the lock-in calculus does not really change. These models are wired into iOS, macOS, and the rest of Apple's software, and they are not products you can swap out. What changes is the honesty of the picture: Apple's on-device AI story is genuinely strong now, with a 20-billion-parameter local model being a real achievement, but its cloud story increasingly runs on infrastructure it does not own.
For the full technical writeup, Apple's Machine Learning Research blog goes into more detail on the architecture and evaluation methodology behind all five models.
Comments
Please log in or register to join the discussion