Cloudflare's recent global outage wasn't just a physical failure—it was a logical design flaw. The company's proposed solutions miss the critical point that preventing such failures requires rigorous database design and formal verification, not just more robust infrastructure.
On November 18, 2025, Cloudflare experienced another global outage that took down large swaths of the internet. This deja vu-inducing incident follows similar high-profile outages from major cloud providers and security firms, prompting a critical question: why do these keep happening?
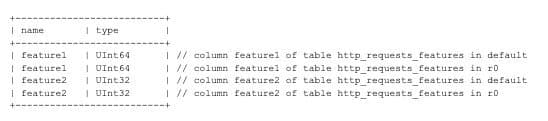
In their root cause analysis (RCA), Cloudflare engineers detailed how a seemingly innocuous database query change triggered a cascade failure across their core systems. The query in question was used by the Bot Management feature to generate configuration files:
SELECT
name,
type
FROM system.columns
WHERE
table = 'http_requests_features'
ORDER BY name;

The problem? This query lacked proper constraints, specifically not filtering by database name. As Cloudflare rolled out new permissions to their ClickHouse cluster, the query began returning columns from multiple databases (including the 'r0' database), effectively doubling the number of rows in the response. This unexpected volume caused the application to crash, triggering a failure loop that propagated across Cloudflare's infrastructure.
"A central database query didn't have the right constraints to express business rules," explains Eduardo Bellani in his analysis. "Not only it missed the database name, but it clearly needs a distinct and a limit, since these seem to be crucial business rules."
This scenario represents a classic database/application mismatch—a pattern familiar to any senior engineer. The application code didn't anticipate the query returning more data than expected, and when it did, the system failed catastrophically.
Cloudflare's proposed solutions to prevent recurrence include:
- Hardening ingestion of configuration files
- Enabling more global kill switches
- Preventing error reports from overwhelming resources
- Reviewing failure modes across core proxy modules
While these are reasonable steps, Bellani argues they miss the fundamental issue: "They already do most of this—and the outage happened anyway."
The core problem, according to Bellani, is Cloudflare's confusion between physical replication and logical design. "One can have a logical single point of failure without having any physical one, which was the case in this situation."
This confusion stems from Cloudflare's architectural choices, particularly their migration from PostgreSQL to ClickHouse for high-performance analytics. While Bellani acknowledges this was likely necessary for processing millions of requests per second, he notes the migration documentation focused entirely on performance without addressing logical consistency.
"They are treating a logical problem as if it was a physical problem," Bellani states.
The author's prescription is clear and radical: "You prevent it by construction—through analytical design."
His recommendations include:
- No nullable fields in database schemas
- Full normalization of databases (following established database design principles)
- Formally verified application code
These approaches, Bellani argues, would make failures "impossible by design, rather than just less likely."
The historical reference to the Cluny library's destruction during the French Revolution serves as a metaphor for how critical systems can collapse when their foundational principles are overlooked. Just as the library's destruction wasn't inevitable but resulted from neglect of its structural integrity, Cloudflare's outage wasn't inevitable but resulted from neglecting logical design principles.
For FAANG-style companies, wholesale adoption of formal methods may seem impractical. However, Bellani argues that for their most critical systems, this rigor is essential. The internet's stability depends on it.
As the industry continues to prioritize speed and scale, Bellani's analysis serves as a crucial reminder: true resilience comes not just from redundant infrastructure, but from rigorous design that anticipates and prevents failure at the logical level.
Comments
Please log in or register to join the discussion