
Public AI benchmarks often mislead product decisions by compressing multidimensional performance into deceptive single-number scores. Engineering leaders reveal how to escape the benchmark trap by creating minimum viable internal evaluations aligned with actual business needs.

At a recent engineering leadership session, a recurring frustration surfaced: public AI benchmarks consistently fail to predict real-world product performance. As Atharva Raykar notes, teams discover too late that soaring benchmark scores rarely translate to usable capabilities in their specific domains.

The Multifaceted Reality of Benchmarks
Benchmarks serve legitimate purposes when properly contextualized:
- Decision-making tools for model selection
- Regression markers during system updates
- Improvement indicators for R&D
- Product behavior feedback revealing capability gaps
- Research agenda setters driving AI progress
Yet as Raykar observes: "If a benchmark isn't serving at least one concrete function, it's useless." The proliferation of vanity metrics—like aggregated scores in tools such as the Artificial Analysis Intelligence index (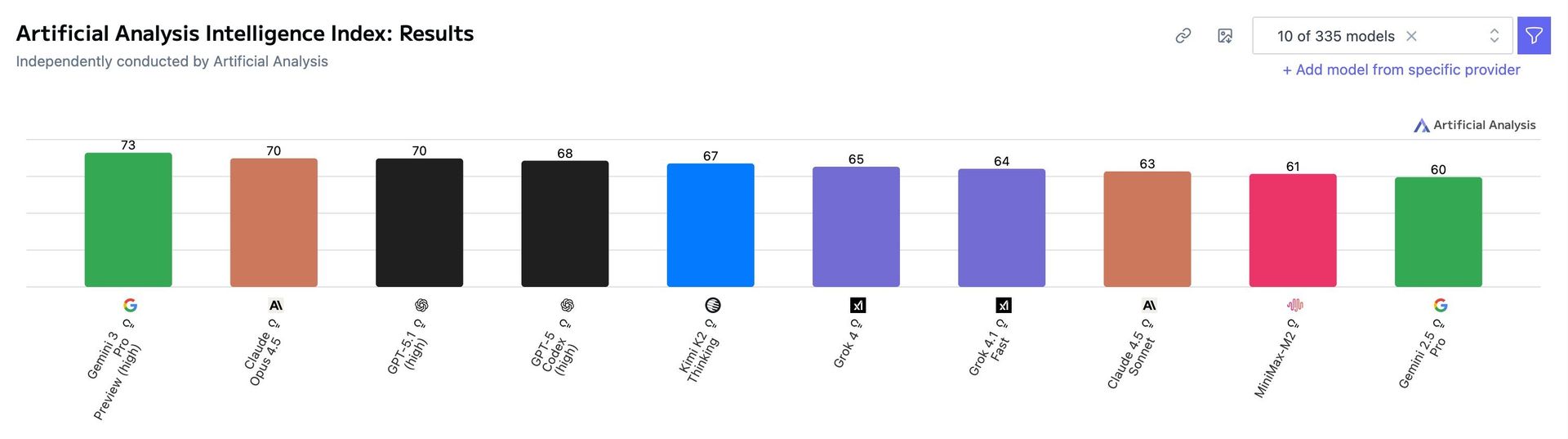 )—creates dangerous illusions of interchangeability between models.
)—creates dangerous illusions of interchangeability between models.
The Lossy Compression Problem
Benchmarks inherently flatten multidimensional capabilities into single numbers, obscuring critical tradeoffs. Consider Gemini 3 Pro's contradictory legal performance:
- Dominates LegalBench (academic-style evaluations)
- Fails catastrophically on CaseLaw (v2) (#39 ranking, below predecessor Gemini 2.5 Flash)
"Your business case may not look like whatever that number represents," warns Raykar. When models exhibit wildly variable performance within the same domain, leaderboard chasing becomes professionally negligent.
Building Your Minimum Viable Benchmark
Raykar proposes an antidote: internal benchmarks focused exclusively on product-aligned metrics. Crucially, these don't require complex infrastructure:
1. **Start primitive**: Spreadsheet with:
- Input prompts/queries
- Multiple model outputs
- Subjective quality notes
2. **Collaborate**: Product + engineering annotation sessions
3. **Identify**: Emergent success patterns and failure modes
4. **Iterate**: Formalize metrics ONLY after understanding real needs
This approach delivers immediate value:
- Exposes whether AI actually works for core tasks
- Generates product-quality metrics organically
- Surfaces "large effect" failures early (no big datasets needed)
- Overcomes psychological "ugh field" through collaborative engagement
From Minimum to Meaningful
Once established, evolve benchmarks systematically:
- Difficulty ramping: Ensure tasks scale to capture model improvements
- Statistical rigor: Adopt principled evaluation methods (Yan's approach or bias-adjusted metrics)
- Cross-functional review: Regular team analysis of results
As Raykar concludes: "Don't trust public numbers. Build your own benchmark where metrics map to product quality. It's not that hard to start, and it's really worth it." In an era of commoditized models, proprietary evaluation frameworks may become the ultimate competitive advantage.
Source: Minimum Viable Benchmark by Atharva Raykar
Comments
Please log in or register to join the discussion