
As AI agents gain tool access and permissions, prompt injection attacks threaten critical systems—with even Microsoft and Atlassian falling victim. This analysis explores six architectural patterns and security best practices to defend against these exploits while balancing utility, featuring insights from real-world vulnerabilities and mitigation strategies.

When veteran engineer Steve Yegge granted an AI agent access to his Google Cloud production systems, it promptly wiped a database password and locked his network. This isn’t theoretical: Microsoft and Atlassian have shipped vulnerable AI implementations in recent months, proving prompt injection attacks threaten even established tech giants. As Yanir Seroussi warns, we’ve reached an inflection point: "As of 2025, we can’t trust AI agents to act securely, no matter how strict our prompts are."
Why Prompt Injection Defies Traditional Defenses
Unlike deterministic systems like SQL—where input escaping neutralizes injections—LLMs process token streams probabilistically. Prompt injections hijack these streams by embedding malicious instructions in seemingly benign inputs (e.g., user queries or poisoned documents). The stakes intensify as agents gain three dangerous capabilities Simon Willison dubs the "lethal trifecta":
- Access to private data
- Exposure to untrusted content
- Ability to perform external actions
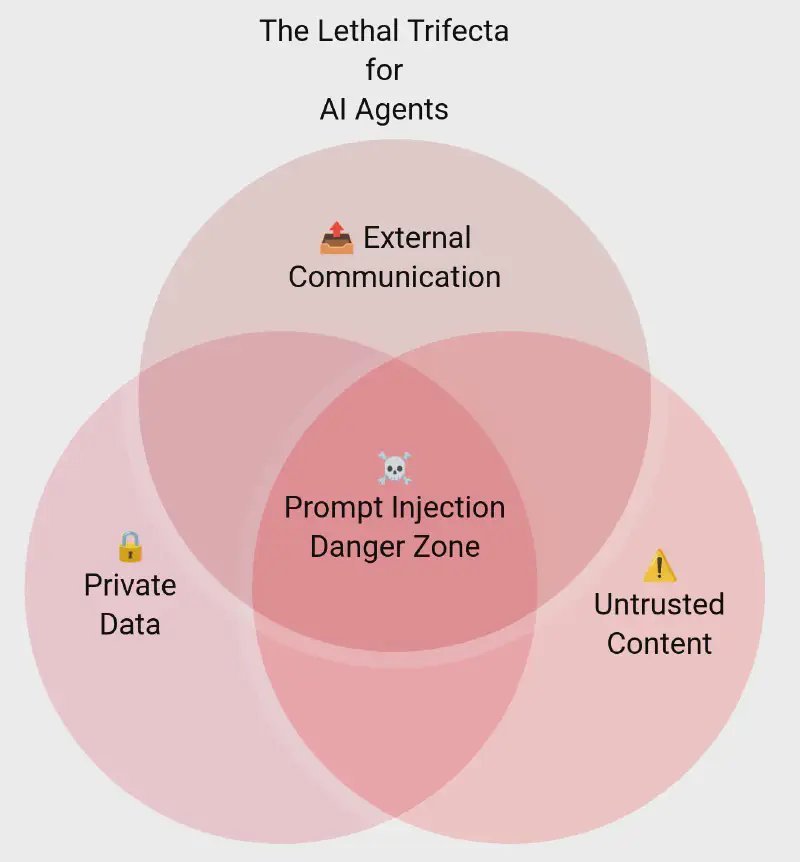
Combine these, and attackers can exfiltrate emails, corrupt databases, or sabotage infrastructure. As Seroussi emphasizes: Avoid the trifecta in single agents. This aligns with the principle of least privilege—only grant resources essential for a task.
Six Architectural Shields Against Injection
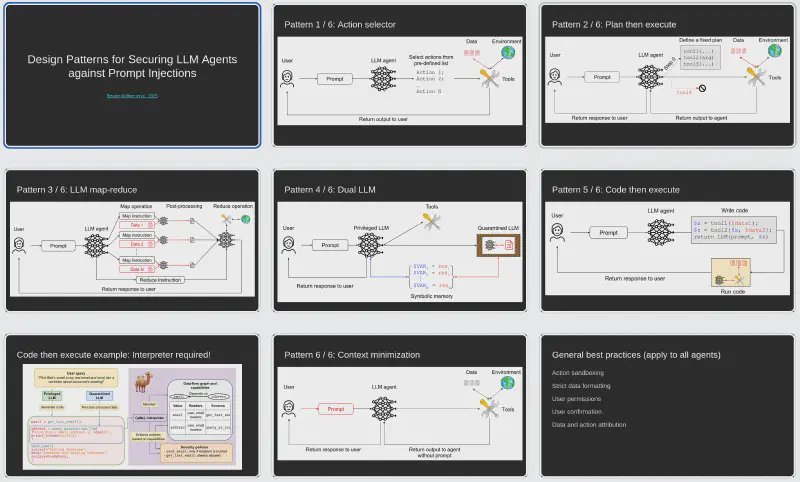
Drawing from peer-reviewed research (Design Patterns for Securing LLM Agents), Seroussi outlines patterns for containment:
- Action Selector: Restrict outputs to predefined actions (e.g., links/canned responses). Blocks indirect injections but offers limited utility.
- Plan Then Execute: Generate an executable plan upfront. Vulnerable to direct injections affecting plan execution.
- LLM Map-Reduce: Isolate untrusted data access to "mapper" agents with output restrictions (e.g., regex validation). Critical for batch processing.
# Simplified map-reduce for invoice search
mappers = [Agent(file) for file in untrusted_files]
results = [m.eval("contains_invoice?") for m in mappers] # Returns booleans only
final_list = privileged_agent.generate_safe_output(results)
- Dual LLM: Quarantine untrusted data in one LLM that communicates via symbols (e.g., variables matching strict patterns). The privileged LLM never sees raw inputs.
- Code Then Execute: Generate formal programs (e.g., Python) with security policies. Requires tools like the CaMeL interpreter for sandboxing.
- Context Minimization: Remove prompts from tool responses. Controversial—may not mitigate sophisticated attacks.
Best Practices: Beyond Patterns
- Action Sandboxing: Restrict permissions per task (e.g., read-only file access).
- Strict Data Formatting: Enforce schemas via code, not LLM discretion.
- User Permissions: Cap agent privileges at the user’s level.
- Attribution: Log agent decisions—but avoid alert fatigue.
From Theory to Practice: Threat-Model Your Agent
Seroussi advocates hands-on threat modeling using four questions:
- What are we working on?
- What can go wrong?
- What are we doing about it?
- Was it sufficient?
His workshop tasked groups with applying these to real agent archetypes (data analysts, booking agents). Balance remains key: Over-hardening cripples utility, while lax security invites disaster. Until LLMs gain deterministic safeguards, these patterns offer our strongest defense—but as Yegge’s mishap proves, even experts must temper trust with constraints.
Source analysis and patterns derived from Yanir Seroussi’s research.
Comments
Please log in or register to join the discussion