
A sharp‑tongued rant about the rise of fabricated statistics and AI‑generated images in tech writing, illustrated by a busted crow‑cleaner story and a misquoted code‑review study. The piece argues that unchecked AI output erodes credibility and urges writers to verify every claim.
Check Your Sources, People!
By Pawel Brodzinski – May 15 2026
The headline that sparked the rant
I saw a LinkedIn post that claimed Sweden built smart machines where crows trade trash for food, turning clever birds into city cleaners. The accompanying image showed a three‑legged crow – a clear sign of AI generation. A quick search revealed the story was about a tiny Swedish startup that ran a one‑off pilot, not a nationwide crow‑cleaning program. The pilot never scaled and was abandoned.
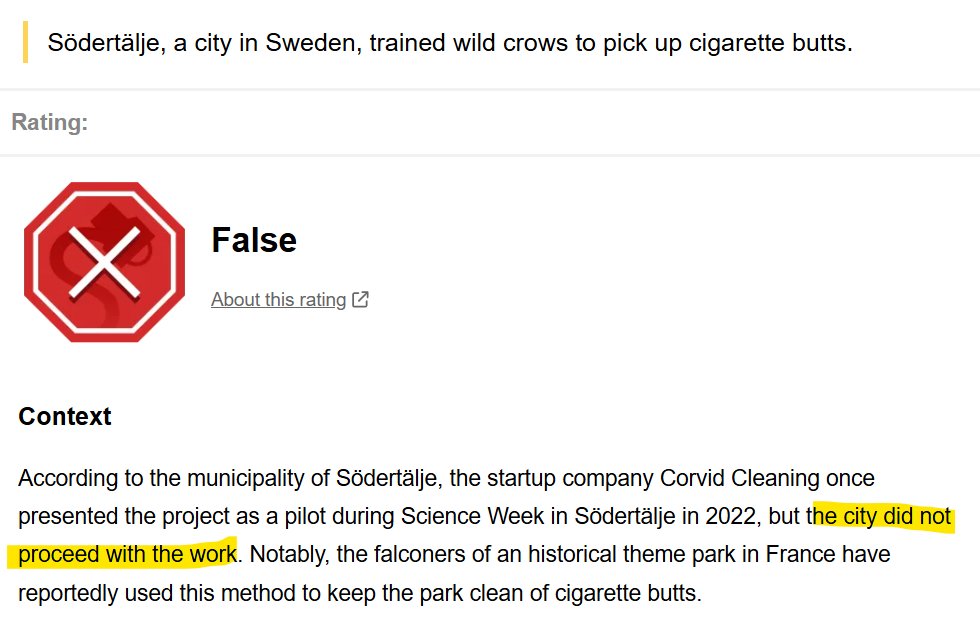
The post was eye‑catching, but the facts were nonexistent. It demonstrates how a flashy graphic can mask a hollow claim, especially when the source link leads nowhere useful.
When data gets twisted: the SmartBear/Cisco study
A more subtle example appeared in an article about AI‑assisted coding. It quoted a “SmartBear/Cisco study” that supposedly found defect detection dropping from 87 % for pull requests under 100 lines to 28 % for PRs over 1,000 lines. Intrigued, I followed the chain of links:
- The article linked to another tech blog.
- That blog linked to a third site.
- The third site referenced the study but provided no numbers.
A direct search for the study led to the original paper. The paper never mentions those percentages. In fact, it contains very few pull requests larger than 1,000 lines, and it measures defect density rather than a binary detection rate. The only concrete finding is that reviewers who examine fewer than 300 LOC per hour achieve the best defect detection, while speeds over 500 LOC per hour see a noticeable dip.
The original claim was therefore a hallucination – a plausible‑sounding statistic invented by an LLM that could not locate a precise answer.
Why AI hallucinates at the fringes
Large language models excel when the answer lies in well‑documented, high‑traffic sources. When the query reaches the “fringe” – niche studies, small data sets, or ambiguous phrasing – the model often fills gaps with fabricated details. The result looks credible: specific numbers, proper citations, even a polished narrative. Yet the underlying evidence is missing.
The danger is two‑fold:
- Self‑reinforcing noise – Once a fabricated claim appears online, other AI systems may cite it as fact, creating a feedback loop.
- Erosion of trust – Readers who discover the falsehood lose confidence in the author, the platform, and eventually the whole ecosystem of AI‑generated content.
Practical steps for writers and readers
- Follow the link chain – Verify that each hyperlink leads to the original source, not just a summary.
- Read the primary material – Skim the abstract, methodology, and conclusions of any study you cite.
- Cross‑check numbers – If a statistic appears unusually precise, search for it independently before publishing.
- Flag AI‑generated graphics – Look for visual anomalies (odd anatomy, inconsistent lighting) that suggest synthetic creation.
- Document your verification – Keep a short note of where you found the data; it helps future editors and readers.
The broader implication for the tech community
As AI tools become more capable, the temptation to let them draft entire articles will grow. They can produce readable prose in minutes, but the cost is often a hidden layer of misinformation. The responsibility now lies with the human gatekeeper: the writer who must treat every AI‑generated claim as a hypothesis, not a conclusion.
In short, check your sources before you let a piece go live. The credibility of our industry depends on it.
If you enjoyed this perspective, consider subscribing to my newsletter for deeper dives into early‑stage product development and AI ethics.
Comments
Please log in or register to join the discussion