
China’s National Supercomputing Center in Shenzhen has unveiled the LineShine system, a CPU‑only AI/HPC machine that reaches 1.54 ExaFLOP/s BF16 training performance with 20,480 custom Armv9 LX2 processors – a total of 2.45 million cores – sidestepping U.S. GPU export bans and reshaping the supply‑chain calculus for large‑scale AI workloads.
China’s LineShine supercomputer breaks the GPU barrier

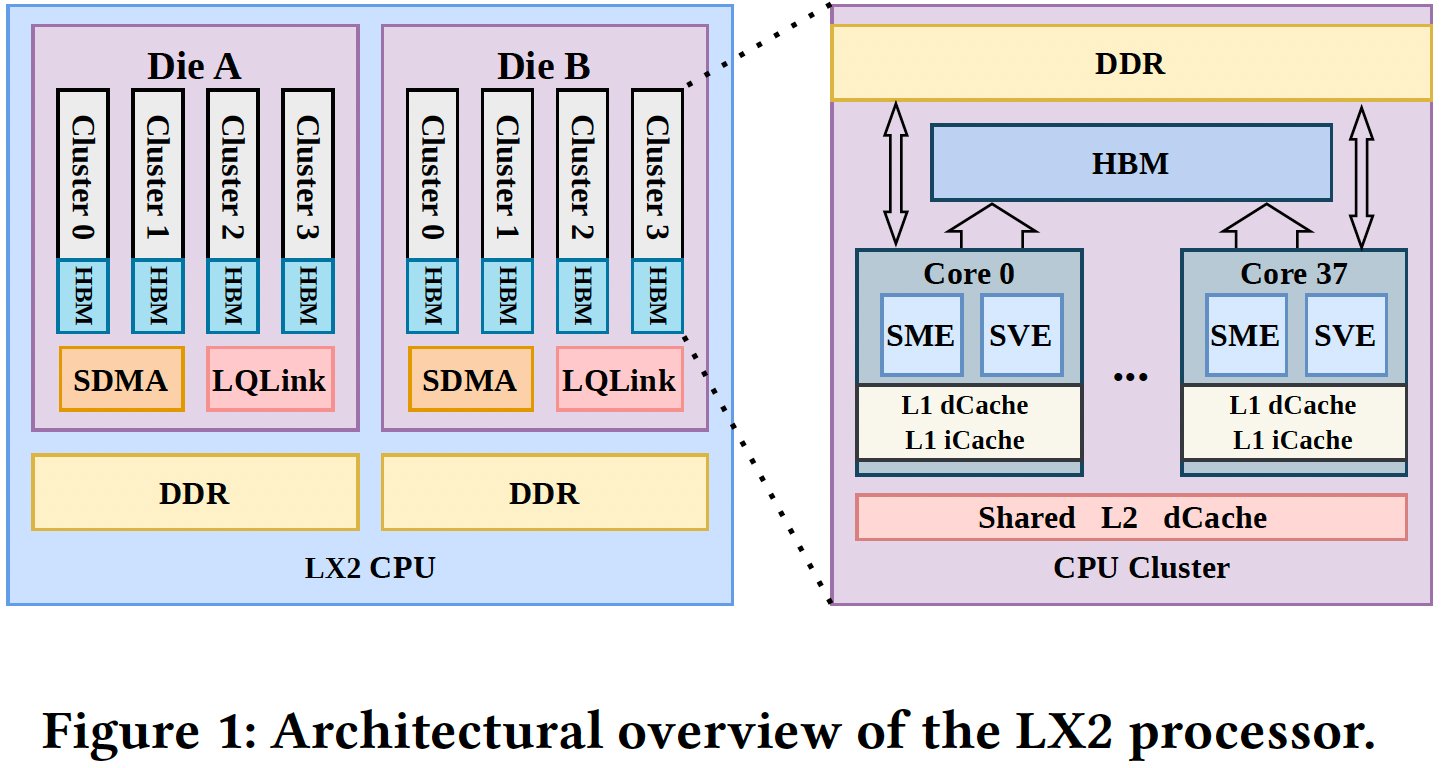
The National Supercomputing Center (NSCC) in Shenzhen announced the LineShine system, a 1.54 ExaFLOP/s AI training machine built entirely from custom Armv9 CPUs. The design relies on 20,480 dual‑socket LX2 nodes, each socket packing 304 cores. In total the rack hosts 2,451,840 cores, the largest Arm‑based core count ever deployed in a single installation.
Technical specifications
LX2 processor architecture
- Core count: 304 per chip, arranged as eight clusters of 38 cores.
- Vector extensions: Full Arm SVE and SME units, supporting FP64, FP32, BF16, FP16 and INT8.
- Cache hierarchy: 32 KB L1‑I + 32 KB L1‑D per core, 28.5 MB shared L2 per cluster.
- Memory subsystem: 32 GB on‑package HBM (up to 4 TB/s bandwidth) + up to 256 GB off‑package DDR5. Each chiplet contains four HBM domains and four DDR domains, yielding 16 NUMA regions per processor.
- Peak throughput per chip: 60.3 TFLOP/s FP64, 240 TFLOP/s BF16/FP16, 960 TOPS INT8.
System‑level design
- Node composition: 2 LX2 sockets per node → 608 cores, 480 GB HBM + 512 GB DDR5.
- Interconnect: Proprietary LingQi (LQLink) fabric, 1.6 Tb/s per node, providing low‑latency, high‑bandwidth links across the 20,480‑node fabric.
- Total compute: 40,960 LX2 processors, 2.45 M cores, 1.54 ExaFLOP/s BF16 training peak, 2.16 ExaFLOP/s when running a 6.3 B‑parameter Earth‑observation generative compression model.
- Power envelope: Roughly 30 MW estimated, noticeably higher than comparable GPU clusters of similar peak performance.
Performance context
| Metric | LineShine | Typical Nvidia‑GPU cluster (e.g., H100‑based) |
|---|---|---|
| BF16 peak | 1.54 ExaFLOP/s | 2.5‑3.0 ExaFLOP/s |
| Utilization (reported) | ~15 % (model‑specific) | 30‑45 % (large‑scale training) |
| FP64 peak | 2.47 ExaFLOP/s | 1.2‑1.5 ExaFLOP/s |
| Power efficiency (BF16) | ~0.5 GFLOP/W | ~0.7‑0.9 GFLOP/W |
The numbers show that while LineShine lags behind the raw density of Nvidia’s H100 GPUs, it compensates with a massive coherent memory pool (HBM + DDR5) and a unified programming model that eliminates CPU‑to‑GPU data movement.
Why a CPU‑only approach matters for China
- Supply‑chain independence – U.S. export controls have limited Chinese access to high‑end GPUs. By scaling a home‑grown Armv9 design, China sidesteps the need for Nvidia or AMD parts and the associated CUDA software stack.
- Memory coherence – The combined HBM/DDR5 hierarchy offers a single address space of several petabytes across the whole machine. Applications that mix large‑scale simulation data with AI models (e.g., climate forecasting, materials discovery) can keep data resident without costly PCIe transfers.
- Software simplification – Developers target a single ISA and runtime (Linux + OpenMP/LLVM). Existing HPC codes need only minor extensions to exploit SME matrix engines, reducing the learning curve compared with CUDA or HIP.
- Strategic flexibility – A homogeneous CPU fleet integrates more easily with traditional supercomputing workloads (CFD, astrophysics) while still delivering competitive AI throughput. This dual capability is attractive for research institutions that must run both simulation and training jobs on the same fabric.
Trade‑offs and market implications
- Power density – The LineShine plant consumes roughly 30 MW, higher than a comparable GPU cluster delivering the same BF16 peak. Data‑center operators will need to invest in advanced cooling and power‑distribution infrastructure.
- AI density – GPUs still hold the advantage for dense matrix multiplication; the LX2’s SME units achieve 960 TOPS INT8 per chip, but a single H100 can exceed 1.5 TOPS. Consequently, workloads that are purely inference‑heavy may see lower cost‑per‑FLOP on LineShine.
- Ecosystem development – The success of LineShine will push the Arm ecosystem to mature SME‑focused compilers, libraries (e.g., oneAPI‑like runtime for Arm), and profiling tools. Expect a surge in open‑source projects targeting the SME ISA over the next 12‑18 months.
- Global supply dynamics – If China can demonstrate reliable, high‑uptime operation at exascale, other nations facing export restrictions (e.g., Russia, certain Southeast Asian economies) may consider similar CPU‑centric paths, potentially diversifying the market away from a single GPU supplier.
- Competitive response – Nvidia is likely to accelerate its own CPU‑GPU integration (Grace Hopper Superchip, Hopper‑based DGX) and to lobby for relaxed export rules. AMD may push its Instinct MI300X line, which already bundles CPU and GPU dies, as a hybrid alternative.
Outlook
LineShine proves that a massive Arm‑based CPU farm can reach exaflop‑class AI performance without any foreign GPU. The design showcases how aggressive on‑package memory, extensive NUMA awareness, and dedicated SME engines can close much of the efficiency gap traditionally enjoyed by GPUs. The trade‑off remains higher power consumption and lower raw AI density, but the strategic benefits—supply‑chain resilience, unified memory, and software simplicity—make the approach compelling for a nation seeking to insulate its AI research from external technology controls.
If the system achieves stable operation and the software stack matures, we may see a new class of "CPU‑centric" exascale machines emerging alongside the more common heterogeneous clusters, reshaping procurement strategies for governments and large‑scale AI labs worldwide.
Comments
Please log in or register to join the discussion