As businesses increasingly rely on AI models, the shift from relying on published benchmarks to empirical testing is reshaping cloud strategies. This article explores how tools like Microsoft Foundry Local enable precise performance measurement, compares offerings across cloud providers, and analyzes the business impact of data-driven model selection.
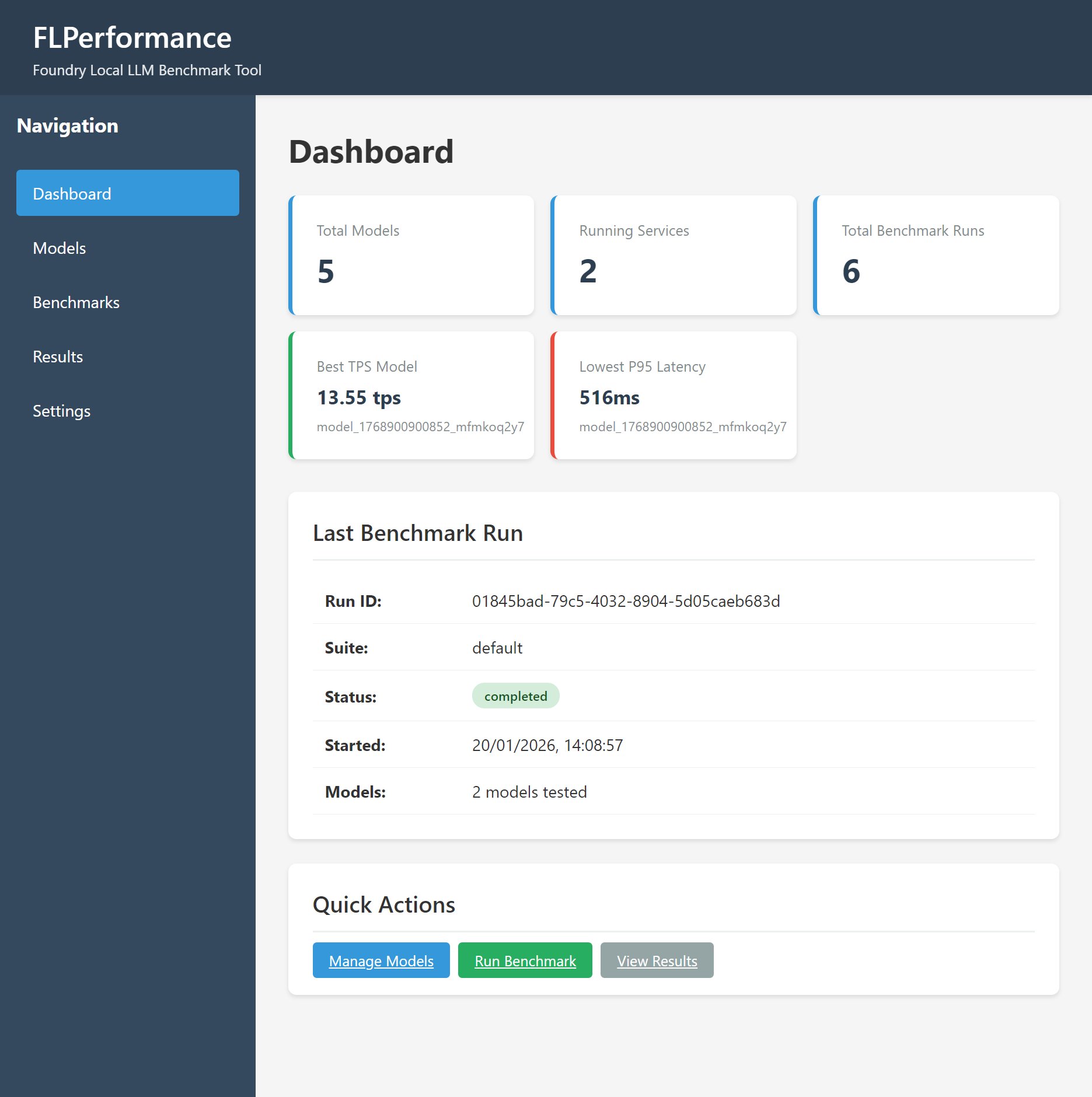
The New Imperative: Hardware-Specific Model Testing
Traditional AI model selection often relied on academic benchmarks measuring question answering or reasoning capabilities. However, these metrics fail to capture critical operational factors:
- Latency requirements (e.g., 100ms response time for real-time apps)
- Hardware constraints (memory limits on edge devices)
- Concurrency needs (handling multiple simultaneous requests)
Microsoft's Foundry Local addresses this gap by enabling:
- Precision benchmarking on actual deployment hardware
- Multi-dimensional metrics (TTFT, TPOT, throughput, error rates)
- Statistical rigor with percentile measurements (p50/p95/p99)
Cloud Provider Benchmarking Capabilities Compared
| Provider | Tool | Hardware Flexibility | Metrics Captured | Open Source Option |
|---|---|---|---|---|
| Microsoft | Foundry Local | Any x86/ARM device | TTFT, TPOT, tokens/sec | FLPerformance |
| AWS | SageMaker Model Metrics | EC2 instances only | Latency, throughput | No |
| Vertex AI Evaluation | TPU/GPU cloud only | Quality scores | No | |
| Hugging Face | Inference Endpoints | Cloud-only | Basic latency | Partial |
Key differentiators:
- Azure's edge advantage: Foundry Local works offline on laptops/Kubernetes clusters
- Cost transparency: Local testing avoids cloud egress fees during evaluation
- Migration readiness: Compare models before committing to cloud deployment
Business Impact Analysis
1. Cost Optimization
- Identify minimum viable model size (e.g., Phi-3.5 Mini vs. larger models)
- Reduce overprovisioning costs by matching models to hardware capabilities
2. Performance Assurance
- Meet SLAs with p99 latency measurements
- Avoid quality degradation during traffic spikes via concurrency testing
3. Migration Planning
- Quantify performance differences between cloud and edge deployments
- Calculate true TCO including cloud instance costs vs local hardware
4. Vendor Strategy
- Standardize evaluations across Azure/Google/AWS models
- Negotiate better cloud contracts with empirical performance data
Implementation Roadmap
Baseline Current State
- Profile existing models using FLPerformance
- Document latency/throughput requirements
Compare Providers
- Run identical benchmarks on Azure VMs, AWS EC2, Google TPUs
- Evaluate Foundry Local vs cloud-native tools
Build Decision Framework
- Weight metrics by business priority (cost vs performance)
- Create model/hardware compatibility matrix
Continuous Monitoring
- Re-benchmark with new model releases
- Track cloud pricing changes affecting TCO
The Bottom Line
Empirical benchmarking transforms AI deployment from guesswork to engineering discipline. By adopting tools like Foundry Local and following methodical comparison processes, organizations can:
- Reduce cloud costs by 30-50% through right-sized models
- Improve application responsiveness with latency-optimized selections
- Future-proof deployments against evolving hardware/cloud landscapes
The complete benchmarking platform and documentation is available on GitHub, providing an open foundation for strategic model evaluation across cloud ecosystems.
Comments
Please log in or register to join the discussion