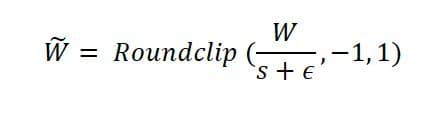
ENERZAi has slashed memory and power demands for AI models like Whisper using extreme 1.58-bit quantization, reducing memory usage by 4x and power consumption by 60% while doubling inference speed—all with minimal accuracy loss. Their custom QAT approach and Optimium inference engine overcome critical barriers for deploying large language models on resource-constrained edge hardware.
The Edge AI Memory Crisis: How 1.58-Bit Quantization Changes the Game
As generative AI models like OpenAI's Whisper become ubiquitous in applications from voice assistants to real-time translation, a harsh reality sets in: these computational behemoths were born for data centers, not the memory-starved, power-frugal world of edge devices. Traditional 32-bit or even 8-bit models buckle under the constraints of embedded systems, where every milliwatt and megabyte counts. Yet the demand for on-device AI grows—imagine a smartwatch that transcribes conversations offline or a factory robot understanding verbal commands without cloud latency. This is where ENERZAi's radical 1.58-bit quantization acts as a surgical strike on inefficiency, compressing models to previously unthinkable densities while preserving their intelligence.
 ENERZAi's 1.58-bit Whisper model demo at Embedded Vision Summit 2025, where their technology won Product of the Year.
ENERZAi's 1.58-bit Whisper model demo at Embedded Vision Summit 2025, where their technology won Product of the Year.
Why 1.58 Bits? The Math Behind the Magic
Quantization isn't new—reducing numerical precision from 32-bit floats to 8-bit integers (INT8) has long been a staple for shrinking models. But ENERZAi pushes this to the theoretical edge: 1.58-bit quantization represents weights using just three values: -1, 0, and 1. The term "1.58-bit" derives from information theory (log₂(3) ≈ 1.58), reflecting the bits needed to encode three states. In practice, this transforms matrix multiplications into sign-based operations, drastically cutting memory footprints and enabling hardware-friendly computations. But there's a catch: collapsing weight distributions this aggressively ravages model accuracy with Post-Training Quantization (PTQ). When ENERZAi tested 2-bit PTQ on Whisper variants, some outputs degenerated into gibberish or failed entirely.
"In extreme low-bit regimes below 4-bits, Quantization-Aware Training isn't just helpful—it's non-negotiable. PTQ collapses; QAT adapts," notes ENERZAi's technical team.
Their solution? Quantization-Aware Training (QAT) simulates 1.58-bit constraints during training, allowing Whisper's weights to adapt to quantization noise. Using ~40,000 hours of speech data (including LibriSpeech and Common Voice) and Google Cloud H100 instances (valued at ~$115,000 in credits), they fine-tuned Whisper Small to tolerate the radical compression. The result? A mere 0.3% increase in Word Error Rate (WER) versus the 16-bit baseline—a negligible trade for monumental gains elsewhere.
Building the Invisible Engine: Optimium and Nadya
A quantized model is useless without a runtime to execute it. Off-the-shelf engines like TensorFlow Lite or whisper.cpp don’t support sub-4-bit precision, so ENERZAi leveraged their in-house stack:
- Optimium: An inference engine that optimizes model graphs and generates hardware-specific kernels.
- Nadya: A domain-specific language (DSL) built on MLIR that auto-generates optimized C++ code. Nadya’s metaprogramming explores thousands of kernel variants, exploiting hardware quirks (e.g., Arm NEON instructions) via explore-exploit algorithms.
For 1.58-bit Whisper, this meant crafting custom kernels where operations like matrix multiplies become efficient sign comparisons. On a quad-core Arm Cortex-A73 (Synaptics Astra SL1680), the stack delivered:
| Model Version | Peak Memory | Latency (9s audio) | Power (12s audio) |
|---|---|---|---|
| 16-bit (whisper.cpp) | 100% (Baseline) | 100% (Baseline) | 0.0213Wh |
| 4-bit PTQ | ~50% | ~75% | — |
| 1.58-bit QAT (Optimium) | 25% | ~50% | 0.0088Wh |
Translation: 4x less memory, 2x faster inference, and 60% lower power draw. In edge environments—where devices juggle multiple tasks on under 1GB RAM—this isn’t incremental; it’s transformative.
Beyond Whisper: The Edge AI Pipeline Revolution
ENERZAi’s 1.58-bit Whisper isn’t an isolated triumph—it’s a blueprint for the entire on-device AI stack. When chained with quantized NLU (Natural Language Understanding) and TTS (Text-to-Speech) models, it enables complex pipelines like voice-controlled appliances on Raspberry Pi-class hardware. Future work includes deploying such systems in smart homes and industrial IoT, proving that generative AI needn’t be shackled to the cloud. As edge devices evolve, so does the mandate: intelligence everywhere, without compromises. ENERZAi’s quantization leap turns that vision into silicon reality.
Source: ENERZAi via Medium
Comments
Please log in or register to join the discussion