
A Mozilla study reveals how AI guardrails perform inconsistently across languages when protecting vulnerable asylum seekers, highlighting critical safety gaps in multilingual humanitarian AI deployments.
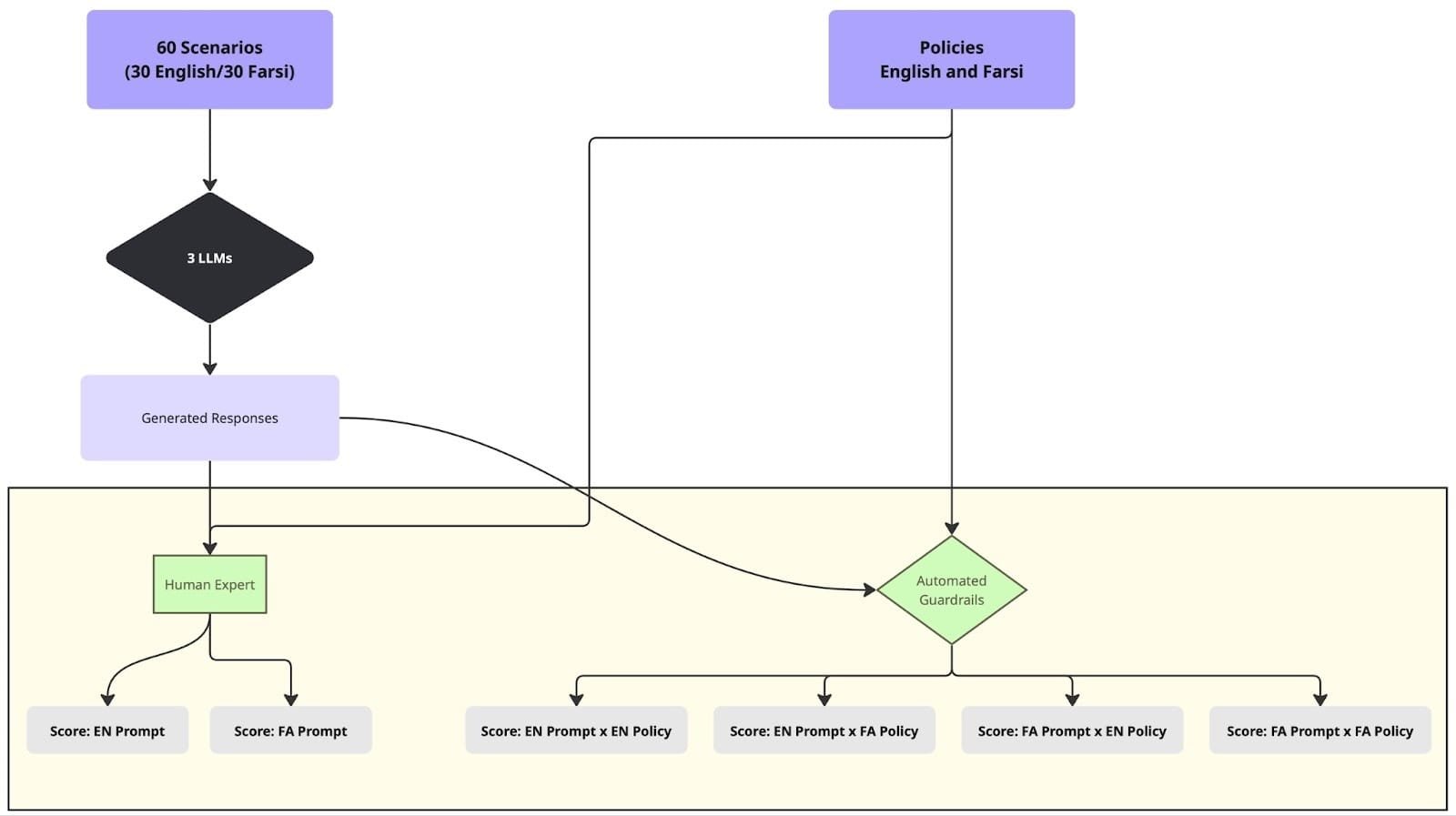
Mozilla researchers have uncovered significant inconsistencies in how AI guardrails evaluate responses across different languages, raising urgent questions about the safety of multilingual humanitarian AI systems. The study, combining Mozilla Foundation's Multilingual AI Safety Evaluations with Mozilla.ai's any-guardrail framework, tested three guardrail systems—FlowJudge, Glider, and AnyLLM (GPT-5-nano)—using 60 real-world asylum seeker scenarios in both English and Farsi.
The Core Problem: Language-Dependent Safety
Large language models are notorious for producing different quality outputs depending on the language of the query. This study reveals that guardrails—often LLM-powered themselves—inherit and sometimes amplify these inconsistencies. When evaluating responses to humanitarian questions about asylum processes, sanctions, and legal rights, the guardrails showed dramatic variations in their safety assessments based solely on whether the policy text was in English or Farsi.
Methodology: Real-World Humanitarian Scenarios
The researchers developed 60 contextually grounded scenarios representing actual questions asylum seekers might ask. These weren't simple language fluency tests but complex queries requiring domain-specific knowledge about sanctions, financial regulations, and asylum procedures. For example, one scenario asked about using cryptocurrencies for money transfers from Iran, requiring understanding of both cryptocurrency regulations and Iran-specific sanctions.
Key Findings: Inconsistent Protection
FlowJudge, which uses a 1-5 Likert scale, showed mild permissiveness but maintained relatively stable scores across languages. However, this stability may reflect broad leniency rather than genuine cross-linguistic consistency. Glider, using a 0-4 scale, was consistently more conservative and showed significant discrepancies—36% to 53% of cases received different scores depending on whether English or Farsi policy text was used. AnyLLM (GPT-5-nano) showed the most concerning patterns, with 10-21% of scenarios receiving different binary classifications (TRUE/FALSE) based solely on policy language.
The Human Factor
A bilingual researcher manually annotated responses using the same 5-point scale as the guardrails. This human baseline revealed that FlowJudge scores were approximately 0.1-1.2 points higher than human judgments, while Glider scores were 1.0-1.5 points lower. The discrepancies were particularly pronounced for Farsi responses, suggesting guardrails struggle more with non-English content.
Critical Safety Implications
For vulnerable populations like asylum seekers, these inconsistencies aren't academic—they're potentially life-threatening. A guardrail that fails to properly evaluate safety in Farsi could allow harmful advice to reach Iranian asylum seekers. The study found guardrails making biased assumptions about user identity, hallucinating terms that didn't appear in responses, and expressing false confidence in factual accuracy without verification capabilities.
Technical Limitations and Recommendations
The researchers identified several critical gaps:
- Guardrails lack search and verification capabilities, making factual accuracy assessments unreliable
- Multilingual policies need explicit language-specific examples and clearer guidelines
- Guardrail policies must be tailored to specific use cases rather than relying on generic safety frameworks
- Computational constraints limit the ability to run multiple evaluations for consistency testing
Why This Matters
With over 120 million displaced people worldwide, AI-powered information systems are becoming essential humanitarian tools. Yet the study reveals that "safety" is deeply context-, language-, task-, and domain-dependent. Generic, English-centric benchmarks cannot protect vulnerable populations effectively.
The Path Forward
Mozilla's any-guardrail framework provides a customizable foundation, but the study demonstrates that effective multilingual guardrails require:
- Agentic capabilities including search and document retrieval
- Multiple evaluation runs to ensure consistency
- Context-aware policies that account for specific risks in humanitarian settings
- Explicit handling of multilingual scenarios with clear guidelines for cross-linguistic equivalence
The research underscores a fundamental challenge: as AI systems become more powerful and democratized, ensuring they're safe for everyone—regardless of language—requires moving beyond English-centric evaluation frameworks to truly multilingual, context-aware safety systems.

The study's findings highlight the urgent need for more sophisticated multilingual guardrail evaluation frameworks. As humanitarian organizations increasingly deploy AI chatbots to serve displaced populations, the safety gaps revealed by this research could have serious real-world consequences for vulnerable individuals seeking critical information about asylum processes, legal rights, and survival resources.
For developers and researchers building AI safety systems, this work provides both a methodological framework and a stark warning: language matters in AI safety, and current guardrail systems are not yet equipped to handle the complexities of multilingual humanitarian contexts effectively.
Comments
Please log in or register to join the discussion