Current LLMs fundamentally lack the ability to model adversarial environments where agents dynamically respond to actions, explaining why domain experts remain skeptical about AI replacing them despite impressive outputs.
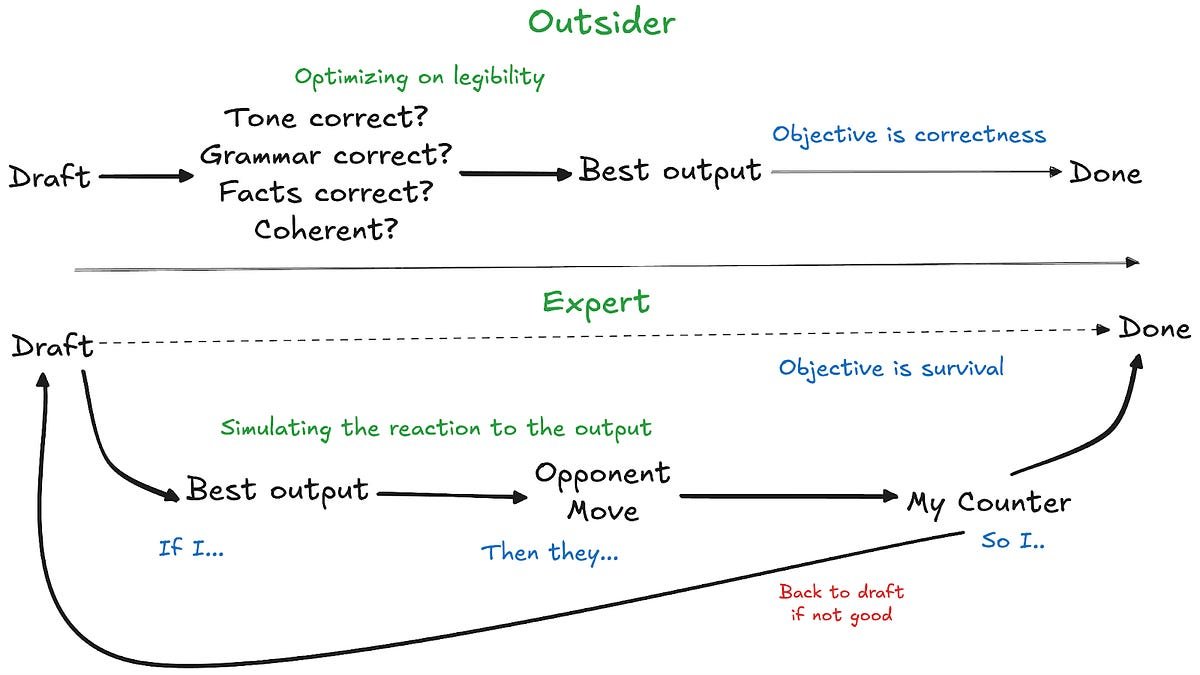
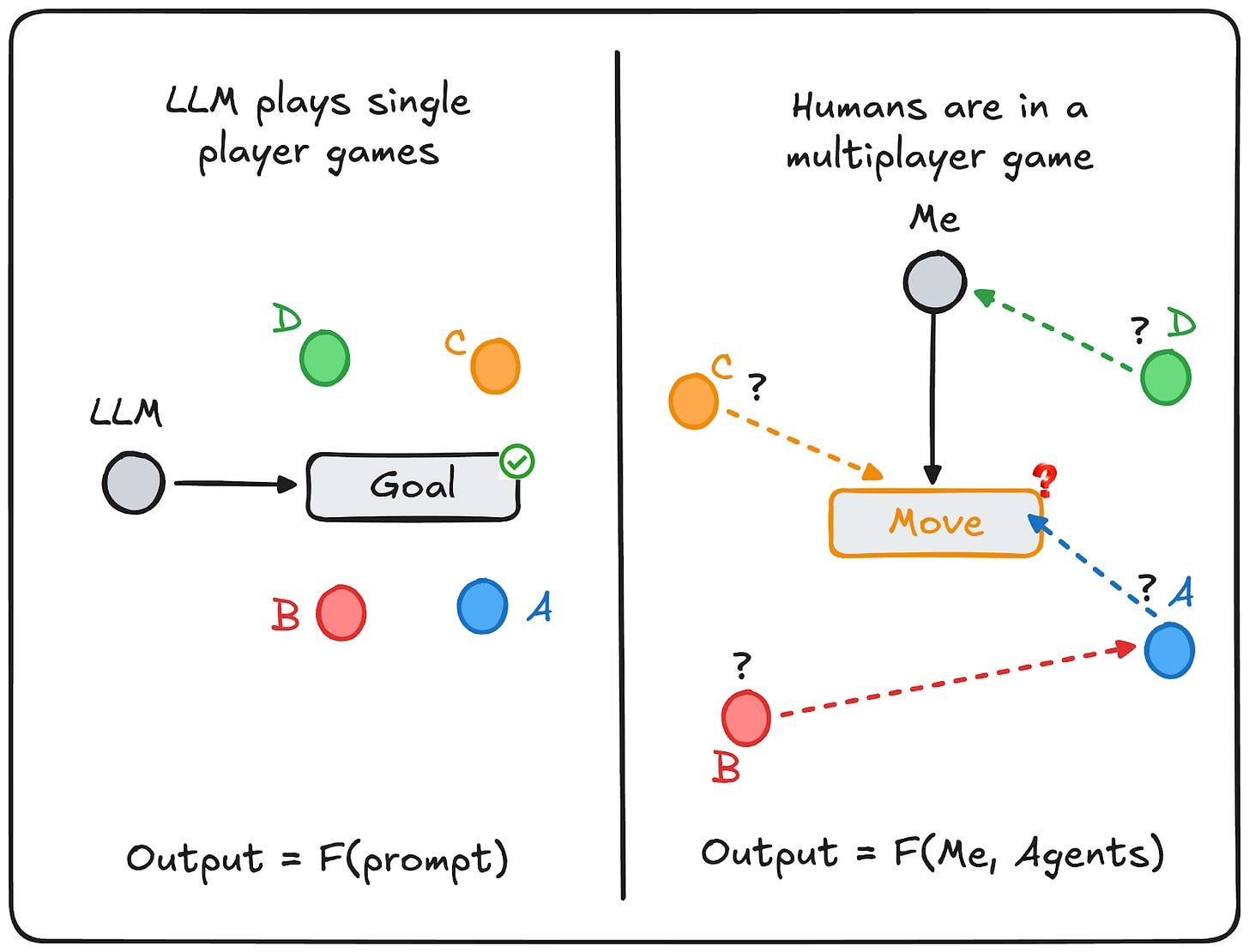
When trial lawyers dismiss AI's ability to replace them while startup founders proclaim it's already happening, both are observing the same outputs but evaluating different dimensions. This disconnect reveals a fundamental limitation in large language models: they produce artifacts rather than strategically robust moves in adversarial environments.
The Slack Message Litmus Test
Consider requesting feedback from an overloaded colleague. An LLM might generate: "Hi Priya, when you have a moment, could you please take a look? No rush at all." While grammatically correct and polite, an experienced coworker would warn:
"Don't send that. 'No rush' signals low priority, ensuring indefinite delay. Specify: 'Blocked on X, need 15 minutes by Friday.'"
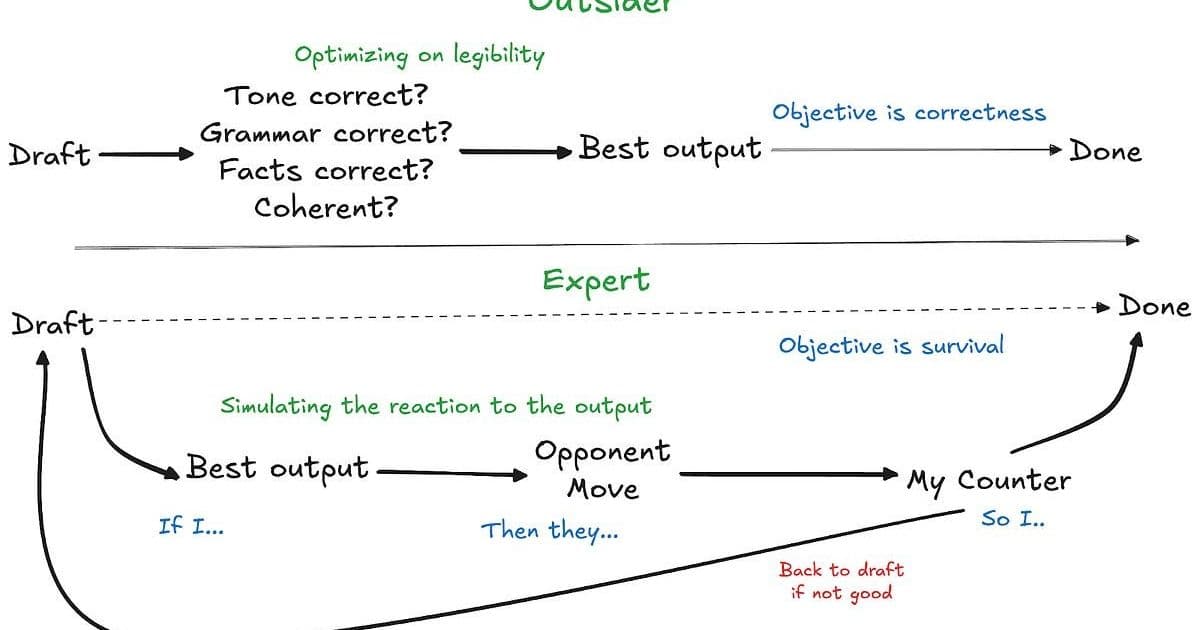
The LLM evaluates text in isolation. The expert simulates Priya's triage algorithm under workload pressure. This gap between artifact evaluation and environmental simulation defines the core limitation.
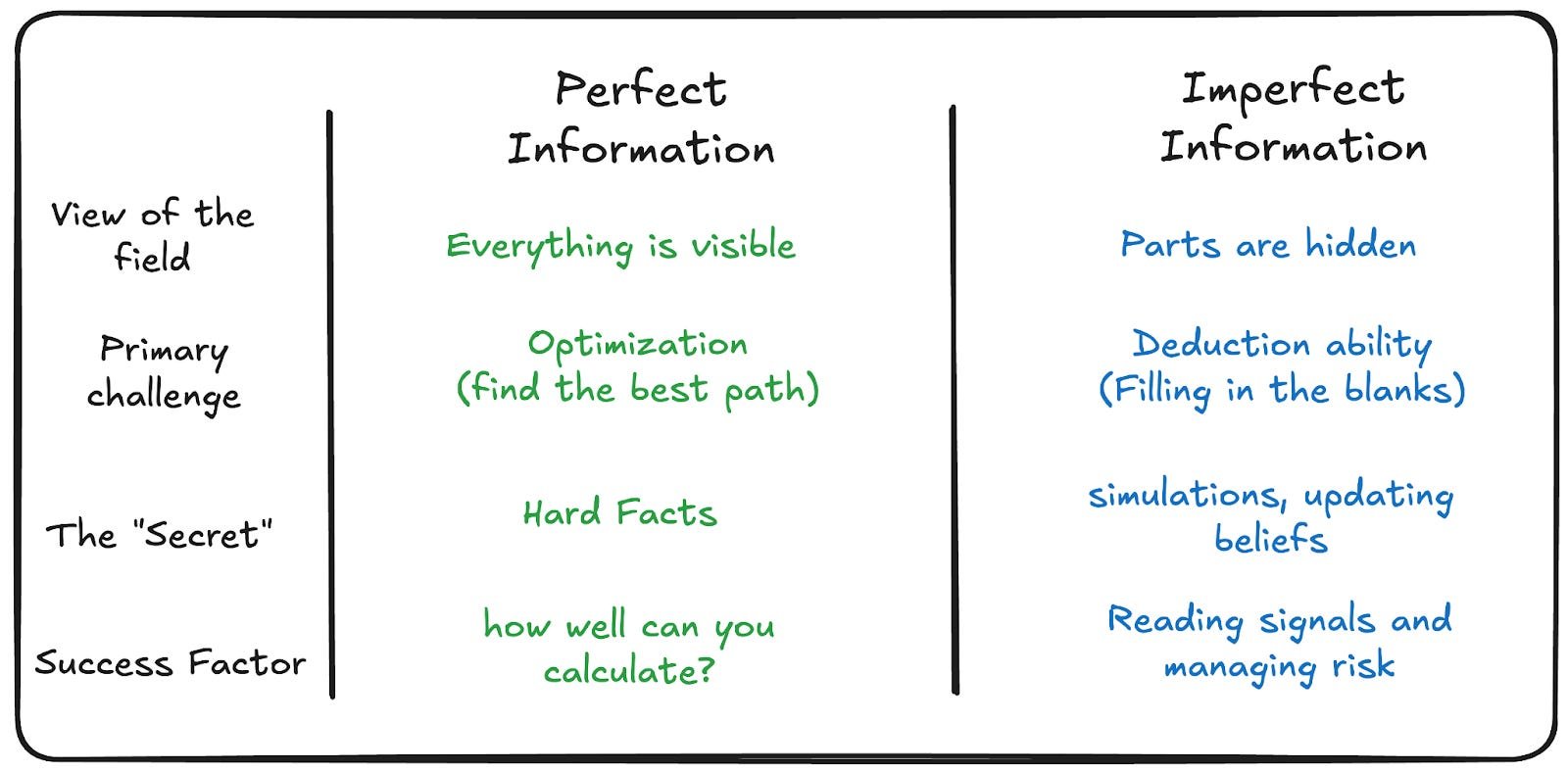
Chess vs. Poker: The Adversarial Divide
- Chess-like domains (LLM-strong): Code generation, math proofs, translation. Fixed rules, no hidden state, no adaptive opponents. AlphaZero mastered chess through state optimization without modeling opponents' minds.
- Poker-like domains (LLM-weak): Negotiation, litigation, strategy. Hidden information, theory of mind requirements, recursive modeling ("I think they think I think...").
Meta's Pluribus poker AI demonstrated the solution: it calculated actions for all possible hands simultaneously, balancing strategies to remain unpredictable. Humans couldn't exploit patterns because none existed.
Why LLMs Fail in Adversarial Loops
- Training mismatch: RLHF optimizes for static "reasonable" outputs, not survival against counterplay. The environment doesn't provide real-time feedback when moves get exploited.
- Predictability penalty: Cooperative biases become detectable patterns. Human adversaries probe and exploit consistency (e.g., anchoring aggressive positions knowing LLMs default to accommodation).
- Recursive modeling gap: LLMs can't simulate being simulated. They don't recalibrate when opponents adjust strategies mid-interaction based on observed patterns.
The Expert Edge: Ecosystem Simulation
Domain expertise isn't just knowledge – it's a high-resolution simulation engine tracking:
- Agents' hidden incentives and constraints
- How actions update others' beliefs
- Counterfactual responses across possible reactions
Legal briefs or negotiation emails are judged not by polish but by vulnerability to exploitation. As one litigator noted: "Ambiguous phrasing isn't inelegant – it's exploitable territory."
Frontier Shift: From Tokens to States
 Labs recognize this limitation. Google DeepMind recently expanded benchmarks to poker and Werewolf, stating: "Chess tests computation. These test social deduction." The required paradigm shift:
Labs recognize this limitation. Google DeepMind recently expanded benchmarks to poker and Werewolf, stating: "Chess tests computation. These test social deduction." The required paradigm shift:
| Old Approach | New Requirement |
|---|---|
| Next token prediction | Next state prediction |
| Single-agent output | Multi-agent environment |
| Static preference tuning | Outcome-based rewards |
The Exploitability Crisis
As LLMs deploy in procurement, sales, and diplomacy, predictable patterns will be weaponized:
- Probing: Testing reaction consistency
- Bluff exploitation: Leveraging truthfulness biases
- Ambiguity attacks: Capitalizing on charitable interpretations
Unlike Pluribus' unpredictability, current LLMs are the most readable counterparts humans have faced.
Path Forward: Adversarial Training Loops
Solutions require fundamental changes:
- Multi-agent RL environments where actions trigger opponent adaptation
- Outcome-based rewards (e.g., negotiation success rate vs. message politeness)
- Real-time opponent modeling during interactions
As Ankit Maloo concludes: "Artifacts impress outsiders. Moves that survive experts require simulating ecosystems, not generating text."
Comments
Please log in or register to join the discussion