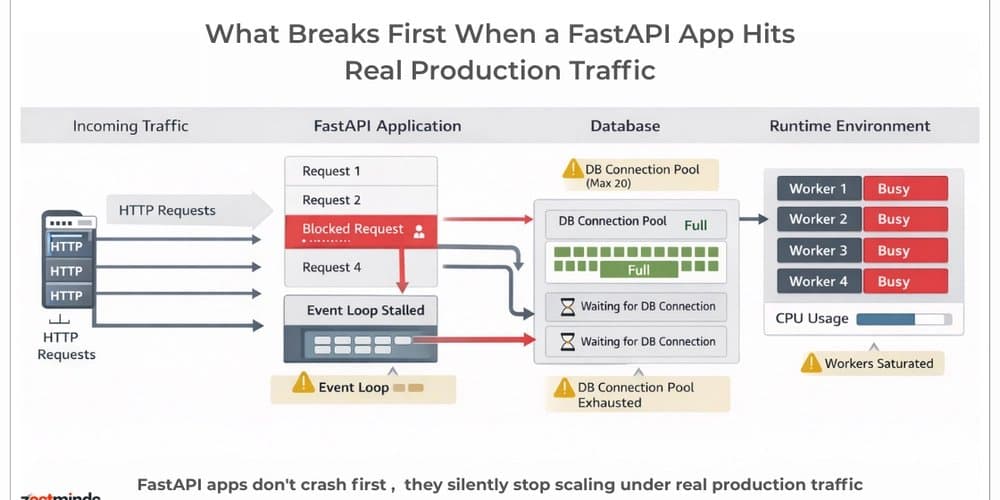
While FastAPI excels for initial development, production-scale deployments reveal architectural bottlenecks that teams often discover too late. This analysis examines five critical scalability challenges and their implications for distributed system design.
FastAPI Under Load: Architectural Bottlenecks in Production Systems
FastAPI delivers impressive performance for minimum viable products, offering a clean, developer-friendly framework for building APIs. However, as traffic scales, the limitations reveal themselves—not in the framework itself, but in the architectural patterns teams implement around it. These bottlenecks emerge when systems transition from development to production workloads, exposing fundamental distributed systems challenges.
This analysis examines five production issues that consistently appear when FastAPI services handle real concurrency, exploring their implications for system design and the trade-offs involved in addressing them.
1. Event Loop Blocking: The Async Illusion
Problem
Just because an endpoint is declared with async def doesn't guarantee non-blocking behavior. Teams frequently implement CPU-heavy operations directly within request handlers, creating subtle bottlenecks that remain hidden under light load. Common patterns include:
- Synchronous database calls within async endpoints
- Large JSON serialization/deserialization
- Data processing operations using libraries like Pandas
- Machine learning inference
- Blocking third-party SDK integrations
Under light traffic, these implementations appear functional. As concurrency increases, however, the entire system's degrades. The event loop becomes blocked, causing latency to spike across all endpoints—even those unrelated to the blocking operations.
Solution Approach
Addressing event loop blocking requires separating concerns between I/O-bound and CPU-bound work:
- Offload CPU-intensive tasks to separate worker processes using tools like Celery or RQ
- Implement async-native database drivers and connection handling
- Push heavy processing to dedicated task queues
- Utilize process pools for CPU-bound operations
- Implement streaming responses for large payloads
The key architectural decision involves identifying which operations truly benefit from async patterns versus those requiring separate processes.
Trade-offs
The primary trade-off lies between request processing simplicity and system complexity. Moving CPU-bound work to separate workers increases architectural complexity but provides better isolation and resource utilization. Teams must also consider:
- Latency implications of inter-process communication
- Additional infrastructure requirements for worker processes
- Error handling complexity across system boundaries
- Development overhead in managing multiple components
The optimal approach depends on the specific workload characteristics and team capacity to manage increased complexity.
2. Database Connection Pool Exhaustion
Problem
Default database connection pool configurations rarely accommodate production workloads. Symptoms of connection pool exhaustion include:
- Requests hanging with timeout errors
- Increased p95 and p99 latency
- Database CPU spikes
- Progressive system degradation under sustained load
The application remains operational but becomes increasingly unresponsive, creating a misleading impression of system health.
Solution Approach
Production-ready database connection management requires explicit configuration and monitoring:
- Explicitly configure pool sizes based on expected concurrency and database capacity
- Implement monitoring of active versus idle connections
- Avoid long-running transactions that hold connections
- Consider read replicas for read-heavy workloads
- Implement circuit breakers for database connectivity
The architectural decision involves treating connection pools as capacity limits requiring infrastructure planning rather than configuration defaults.
Trade-offs
Connection pool optimization involves balancing several factors:
- Larger pools increase database load and resource consumption
- Smaller pools increase request contention and latency
- Read replicas improve read performance but add operational complexity
- Connection monitoring adds development overhead but provides visibility
Teams must consider their database's specific capabilities and limitations when tuning connection pools.
3. BackgroundTasks vs. Distributed Queues
Problem
FastAPI's BackgroundTasks serves a purpose but is frequently misused for workloads beyond its design scope. Teams often implement:
- Bulk email sending
- File processing
- Report generation
- Long-running workflows
Under load, these background tasks compete with incoming requests for resources, reducing overall system throughput. The shared resource contention creates unpredictable performance characteristics.
Solution Approach
For production workloads, proper task separation requires distributed queue systems:
- Implement dedicated queue systems like Celery, RQ, or Dramatiq
- Utilize message brokers such as Redis or RabbitMQ
- Separate request handling from asynchronous workload processing
- Design idempotent tasks that can be safely retried
- Implement proper task prioritization and monitoring
The architectural decision involves creating clear boundaries between synchronous request processing and asynchronous background work.
Trade-offs
Implementing distributed queues introduces several considerations:
- Increased operational complexity for queue infrastructure
- Additional latency for task execution
- Need for proper error handling and retry mechanisms
- Resource requirements for queue workers
- Potential for message accumulation during outages
The benefits of improved isolation and scalability must be weighed against the operational overhead.
4. Uvicorn Worker Configuration
Problem
Many FastAPI deployments start with simple configurations like uvicorn main:app, using a single worker with default settings. Under production load, this approach reveals limitations:
- CPU saturation under moderate traffic
- Request queuing and increased latency
- Worker restarts under sustained load
- Inefficient resource utilization
The default configuration fails to leverage available system resources effectively.
Solution Approach
Production FastAPI deployments require thoughtful worker configuration:
- Use Gunicorn with Uvicorn workers:
gunicorn -k uvicorn.workers.UvicornWorker -w 4 main:app - Tune worker count based on CPU cores and workload characteristics
- Implement proper process management for worker restarts
- Configure appropriate timeouts for different types of requests
- Consider async worker processes for I/O-bound workloads
The architectural decision involves aligning worker configuration with the specific nature of the application's workload.
Trade-offs
Worker configuration optimization requires balancing several factors:
- More workers increase throughput but also memory usage
- Worker count must match CPU availability for CPU-bound workloads
- Async workers provide better I/O utilization but add complexity
- Process management overhead increases with more workers
- Restart strategies must balance availability with resource consumption
Teams must measure actual performance characteristics rather than relying on theoretical optimizations.
5. Memory Growth Under Concurrency
Problem
Memory issues in FastAPI applications often remain hidden until systems face significant concurrency. Under load, several patterns contribute to memory growth:
- Large response objects accumulating in memory
- Inefficient dependency injection patterns creating persistent references
- In-memory caching misuse
- Objects not being released promptly
Symptoms include gradual memory increase, higher garbage collection pressure, and eventual container restarts.
Solution Approach
Addressing memory growth requires careful design and monitoring:
- Profile memory usage under realistic load conditions
- Implement streaming responses for large payloads
- Keep request-scoped dependencies clean and short-lived
- Use appropriate caching strategies with expiration
- Monitor container memory continuously
The architectural decision involves designing for predictable memory usage patterns rather than optimizing for peak performance.
Trade-offs
Memory optimization involves several trade-offs:
- Streaming responses reduce memory usage but increase complexity
- Caching improves performance but consumes memory
- Object pooling reduces allocation overhead but increases complexity
- Frequent garbage collection reduces memory pressure but increases CPU usage
- Memory limits protect the system but may require request rejection
Teams must balance performance requirements with resource constraints.
The Systems Thinking Perspective
FastAPI itself is not the scalability layer—it's a framework. True scalability emerges from:
- Architectural decisions that separate concerns appropriately
- Comprehensive load testing under realistic conditions
- Capacity planning that anticipates growth
- Observability that provides insight into system behavior
- Clear separation between synchronous and asynchronous workloads
Most "FastAPI performance issues" are fundamentally system design issues that become apparent only under load.
Production Validation Framework
Before scaling a FastAPI-based system, teams should validate:
- Async correctness across all components
- Database pool configuration matching expected load
- Worker strategy aligned with workload characteristics
- Clear separation between request handling and background processing
- Load testing under realistic traffic patterns
- p95/p99 latency tracking for all critical paths
- Memory usage patterns under sustained concurrency
Production problems rarely manifest in development environments. They emerge when marketing succeeds and systems face real-world usage patterns.
Conclusion
The challenges outlined here are not unique to FastAPI—they represent fundamental distributed systems principles that apply to any async framework. The specific implementation details may vary, but the underlying architectural concerns remain consistent.
Teams that recognize these issues early can design systems that scale gracefully rather than reacting to crises as they occur. The key is understanding that framework performance is only one component of overall system performance.
For teams building production systems with FastAPI, deeper exploration of these architectural patterns and their implementation details can be found in engineering resources that document production experiences and system design decisions.
What production challenges have you encountered when scaling FastAPI applications? Which of these issues surprised you most in your deployment experience?
Comments
Please log in or register to join the discussion