
FuriosaAI is launching a turnkey server system built around its RNGD accelerators, designed to deliver high-performance AI inference without the power and cooling demands of traditional GPU farms. The NXT RNGD Server targets the vast majority of existing data centers that are air-cooled and power-constrained, offering a practical path to deployment for enterprises.
The AI infrastructure market is currently defined by a single bottleneck: power and thermal limits. While demand for inference capacity skyrockets, the physical data centers that house this compute are struggling to keep up. Most facilities were not built for the 10kW+ per server, liquid-cooled racks that modern GPUs demand. This mismatch forces a difficult choice between expensive, disruptive facility retrofits or a move to new, specialized data centers.
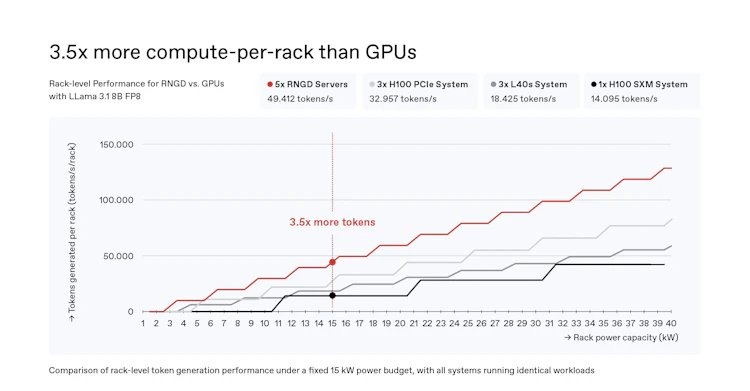
FuriosaAI is positioning its new NXT RNGD Server as a direct answer to this problem. The company is moving beyond just selling its RNGD accelerator chips and is now offering a complete, branded server system. The core value proposition is efficiency: delivering substantial AI inference performance within a power envelope that fits existing infrastructure.

The Hardware: Optimized for Practical Deployment
The NXT RNGD Server is a 1U rack-mountable system engineered for density and compatibility. Its headline specification is a 3 kW power draw, a deliberate choice to fit within the constraints of facilities that are not equipped for high-density liquid cooling. According to FuriosaAI, more than 80% of today's data centers are air-cooled and operate at 8 kW per rack or less, making the NXT RNGD Server a plug-and-play upgrade rather than a capital-intensive overhaul.
Inside the chassis, the system supports up to eight of the company's RNGD accelerators, delivering a claimed 4 petaFLOPS of FP8 compute per server. The accelerators are paired with dual AMD EPYC processors. This configuration is designed to handle large language models and other demanding AI workloads efficiently.
Memory and I/O are configured to prevent bottlenecks. The server includes 384 GB of HBM3 memory with 12 TB/s of bandwidth, supplemented by 1 TB of DDR5 system memory. For storage, it ships with a pair of 960 GB NVMe drives for the operating system and a pair of 3.84 TB NVMe U.2 drives for internal data or model caching. Networking is handled by two 25G data NICs, which is sufficient for most inference serving scenarios, alongside a standard 1G management port.
From a systems management perspective, the server includes standard enterprise features like Secure Boot, a TPM (Trusted Platform Module), and a BMC (Baseboard Management Controller) for attestation and remote management. This ensures it can be integrated into existing operational workflows without special handling.
The Software Stack: From Silicon to Serving
A server is only as useful as the software that runs on it. FuriosaAI is addressing this by shipping the NXT RNGD Server with its full software stack pre-installed. This includes the Furiosa SDK for model compilation and optimization, and the Furiosa LLM runtime for serving.
Crucially, the Furiosa LLM runtime is vLLM-compatible and includes native support for the OpenAI API. This is a significant strategic decision. It means that organizations with existing applications built for OpenAI's models can, in many cases, simply point their clients to the NXT RNGD Server's endpoint and have their workloads running with minimal code changes. This drastically lowers the barrier to entry for deploying models on-premises or in private cloud environments.
The system also integrates with Kubernetes and Helm, allowing it to fit into modern cloud-native deployment pipelines. This combination of hardware and software is intended to create a turnkey experience, moving enterprises from unboxing to serving production inference as quickly as possible.
Real-World Validation and Use Cases
FuriosaAI is not just making claims about potential performance; they have an anchor customer in LG AI Research. In July, LG announced it has adopted RNGD accelerators for inference on its EXAONE models. The results they reported are a key proof point for the platform's efficiency.
According to FuriosaAI, running LG’s EXAONE 3.5 32B model on a single RNGD server (with four cards) at a batch size of one, they achieved:
- 60 tokens/second with a 4K context window
- 50 tokens/second with a 32K context window
These throughput figures are particularly notable for a single-batch, low-latency scenario, which is often the most demanding use case for real-time applications. The companies are now collaborating to supply NXT RNGD servers to LG's enterprise clients in sectors like electronics, finance, and biotechnology.
This validation from a major industrial conglomerate lends credibility to FuriosaAI's broader pitch. The server is not just for hyperscalers; it's for any enterprise that needs to run advanced AI models on-premises for reasons of data privacy, regulatory compliance, or simply to maintain control over their infrastructure.
Market Positioning: A Pragmatic Path Forward
The global data center market is projected to grow from 60 GW of demand in 2024 to nearly 180 GW by the end of the decade. The infrastructure to support this growth simply does not exist yet, and building it is a massive undertaking.
FuriosaAI's strategy with the NXT RNGD Server is to sidestep this infrastructure race by making AI deployment viable today, within the constraints of the data centers we already have. By focusing on a 3 kW, air-cooled form factor, they are targeting the 80% of the market that is underserved by current GPU trends.
This approach trades the raw, unbounded performance of the largest GPU systems for practicality and total cost of ownership. For many businesses, that will be a trade worth making. The ability to scale AI inference without waiting for new data centers to be built or existing ones to be rewired is a compelling value proposition.
Availability
FuriosaAI is currently taking inquiries and orders for the NXT RNGD Server, with general availability expected in January 2026. The company has made the official datasheet available for those interested in the full technical details.
For a deeper look at the compiler optimizations and performance tuning, you can read FuriosaAI's technical posts on their viewpoints blog.
Comments
Please log in or register to join the discussion