Google DeepMind researchers have introduced ATLAS, a comprehensive framework of scaling laws that quantifies how model size, training data volume, and language mixtures interact as the number of supported languages increases, providing practical guidance for building efficient multilingual models.
Google DeepMind has unveiled ATLAS, a groundbreaking set of scaling laws specifically designed for multilingual language models that addresses the unique challenges of training systems across hundreds of languages simultaneously.
The Challenge of Multilingual Scaling
Most existing scaling laws in machine learning have been derived from English-only or single-language training regimes, leaving a significant gap in understanding how models behave when trained on multiple languages. This limitation has made it difficult for researchers and engineers to predict the computational requirements and performance trade-offs when building truly multilingual systems.
The ATLAS framework fills this gap by explicitly modeling cross-lingual transfer and the efficiency trade-offs introduced by multilingual training. Rather than assuming a uniform impact from adding languages, ATLAS provides a nuanced understanding of how individual languages contribute to or interfere with performance in others during training.
Core Methodology and Scale
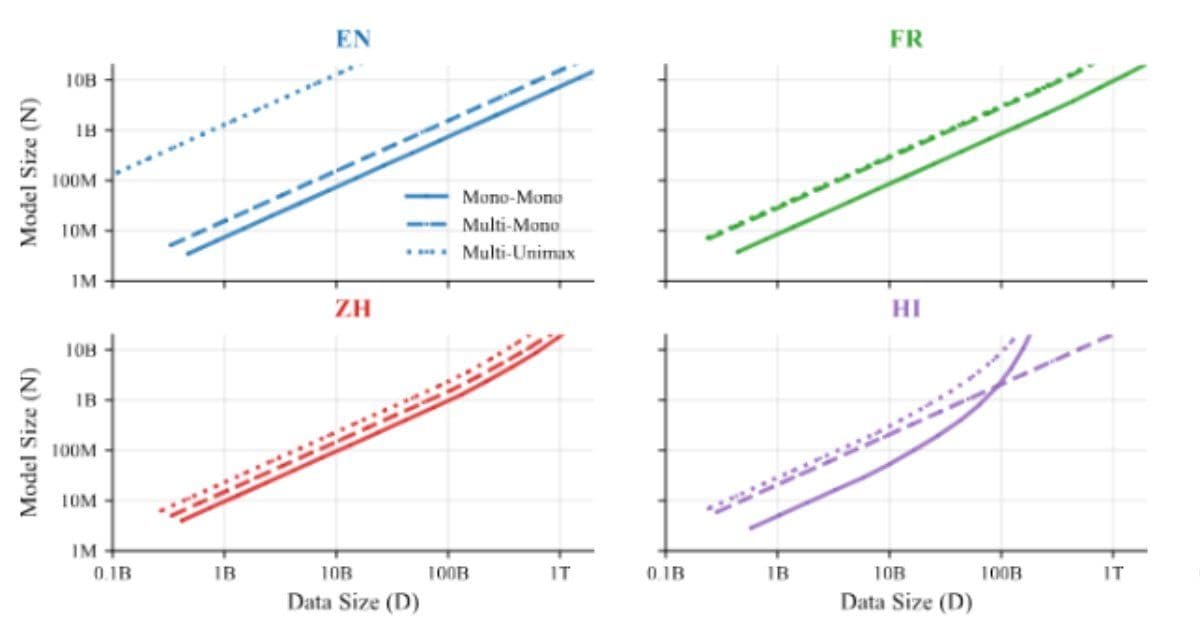
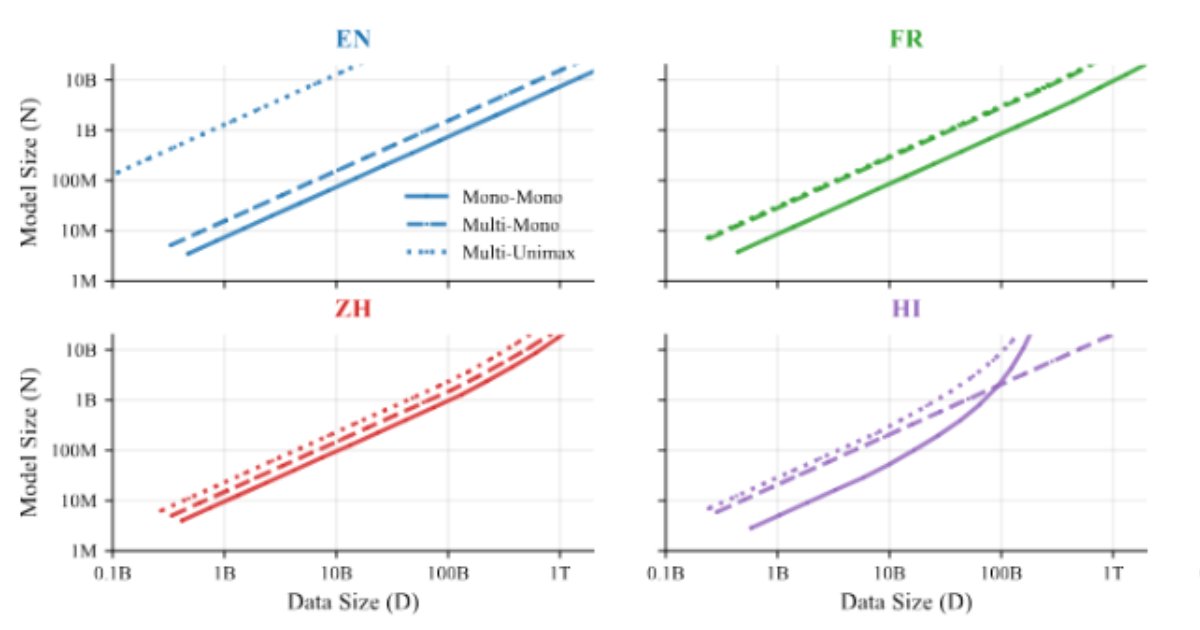
The research is based on an impressive 774 controlled training runs across models ranging from 10 million to 8 billion parameters. The team used multilingual data covering more than 400 languages and evaluated performance across 48 target languages, providing a robust empirical foundation for their findings.
At the heart of ATLAS is a cross-lingual transfer matrix that measures how training on one language affects performance in another. This analysis reveals that positive transfer is strongly correlated with shared scripts and language families. For example, Scandinavian languages exhibit mutual benefits, while Malay and Indonesian form a high-transfer pair.
English, French, and Spanish emerge as broadly helpful source languages, likely due to their data scale and diversity, though transfer effects are not symmetric. This insight is crucial for understanding which languages provide the most value when included in multilingual training.
Quantifying the "Curse of Multilinguality"
One of ATLAS's most significant contributions is quantifying what researchers call the "curse of multilinguality" - the phenomenon where per-language performance declines as more languages are added to a fixed-capacity model.
Empirical results show that doubling the number of languages while maintaining performance requires increasing model size by roughly 1.18× and total training data by 1.66×. However, positive cross-lingual transfer partially offsets the reduced data per language, making multilingual training more efficient than it would be without transfer effects.
Practical Guidelines for Model Development
The study also examines when it is more effective to pre-train a multilingual model from scratch versus fine-tuning an existing multilingual checkpoint. Results show that fine-tuning is more compute-efficient at lower token budgets, while pre-training becomes advantageous once training data and compute exceed a language-dependent threshold.
For 2B-parameter models, this crossover typically occurs between about 144B and 283B tokens, providing a practical guideline for selecting an approach based on available resources. This insight helps practitioners make informed decisions about resource allocation and model development strategies.
Implications for Model Architecture
The release has sparked interesting discussions about alternative model architectures. One X user commented: "Rather than an enormous model that is trained on redundant data from every language, how large would a purely translation model need to be, and how much smaller would it make the base model?"
While ATLAS does not directly answer this question, its transfer measurements and scaling rules offer a quantitative foundation for exploring modular or specialized multilingual designs. The framework could inform the development of more efficient architectures that leverage translation models or other specialized components.
Technical Contributions and Future Directions
ATLAS extends scaling laws by explicitly modeling the number of training languages alongside model size and data volume. This extension is crucial because it acknowledges that the relationship between model capacity and performance is fundamentally different in multilingual settings compared to monolingual ones.
The framework provides researchers and practitioners with concrete formulas and guidelines for predicting the computational requirements of multilingual models. This predictability is essential for planning large-scale training runs and for making informed decisions about model architecture and training strategies.
Broader Impact on the Field
The introduction of ATLAS represents a significant step forward in making multilingual AI more accessible and efficient. By providing a quantitative framework for understanding the trade-offs involved in multilingual training, it enables more informed decision-making in the development of language technologies that can serve diverse global populations.
This work is particularly relevant as the demand for multilingual AI systems continues to grow, driven by the need to serve users across different languages and regions. The insights from ATLAS can help ensure that these systems are developed efficiently and effectively, maximizing their impact while minimizing resource requirements.
The ATLAS framework is now available for researchers and practitioners to use in their own work, potentially accelerating the development of more capable and efficient multilingual language models across the field.
Comments
Please log in or register to join the discussion