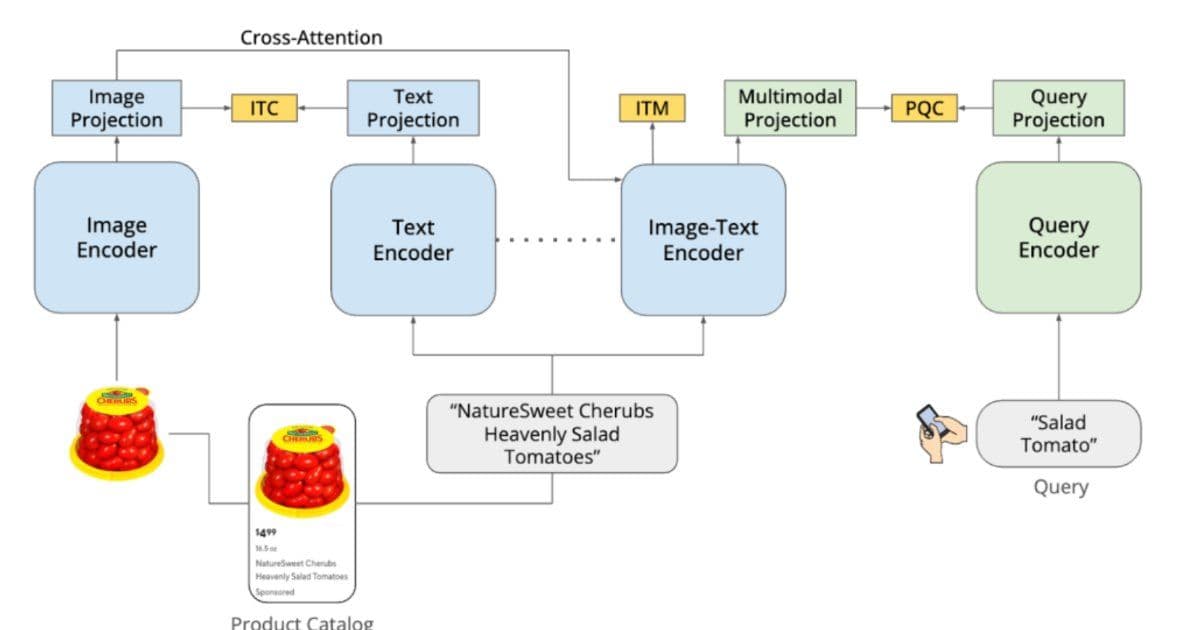
DoorDash has developed DashCLIP, a multimodal ML system that aligns product images, text descriptions, and user queries in shared embedding space to improve semantic search across its diverse CPG marketplace.
DoorDash has introduced DashCLIP, a multimodal machine learning system designed to generate semantic embeddings by aligning product images, text descriptions, and user queries in a shared representation space. The architecture aims to improve product discovery, ranking, and advertising relevance across the company's Consumer Packaged Goods (CPG) marketplace.
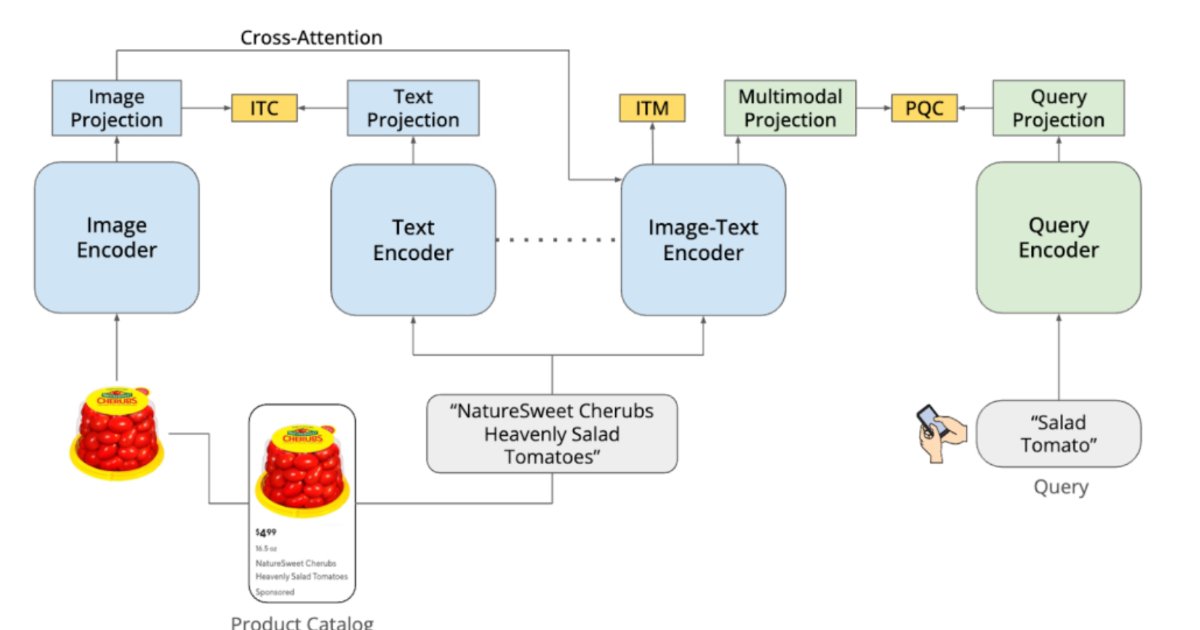
To train the system, DoorDash used approximately 32 million labeled query product pairs to align search queries with relevant catalog items. DoorDash's marketplace spans diverse categories, including groceries, retail goods, electronics, and pharmaceuticals. This variety challenges traditional search and recommendation systems that rely on structured metadata and historical engagement signals. These approaches often miss semantic relationships between product images, descriptions, and user intent.
DashCLIP addresses this by learning multimodal representations that combine visual and textual product information with query context. The system builds on contrastive learning approaches, such as CLIP (Contrastive Language-Image Pretraining). It uses separate encoders for product images, text descriptions, and user queries, each producing vector embeddings. During training, semantically related items are placed close together in the embedding space while unrelated items are pushed apart.
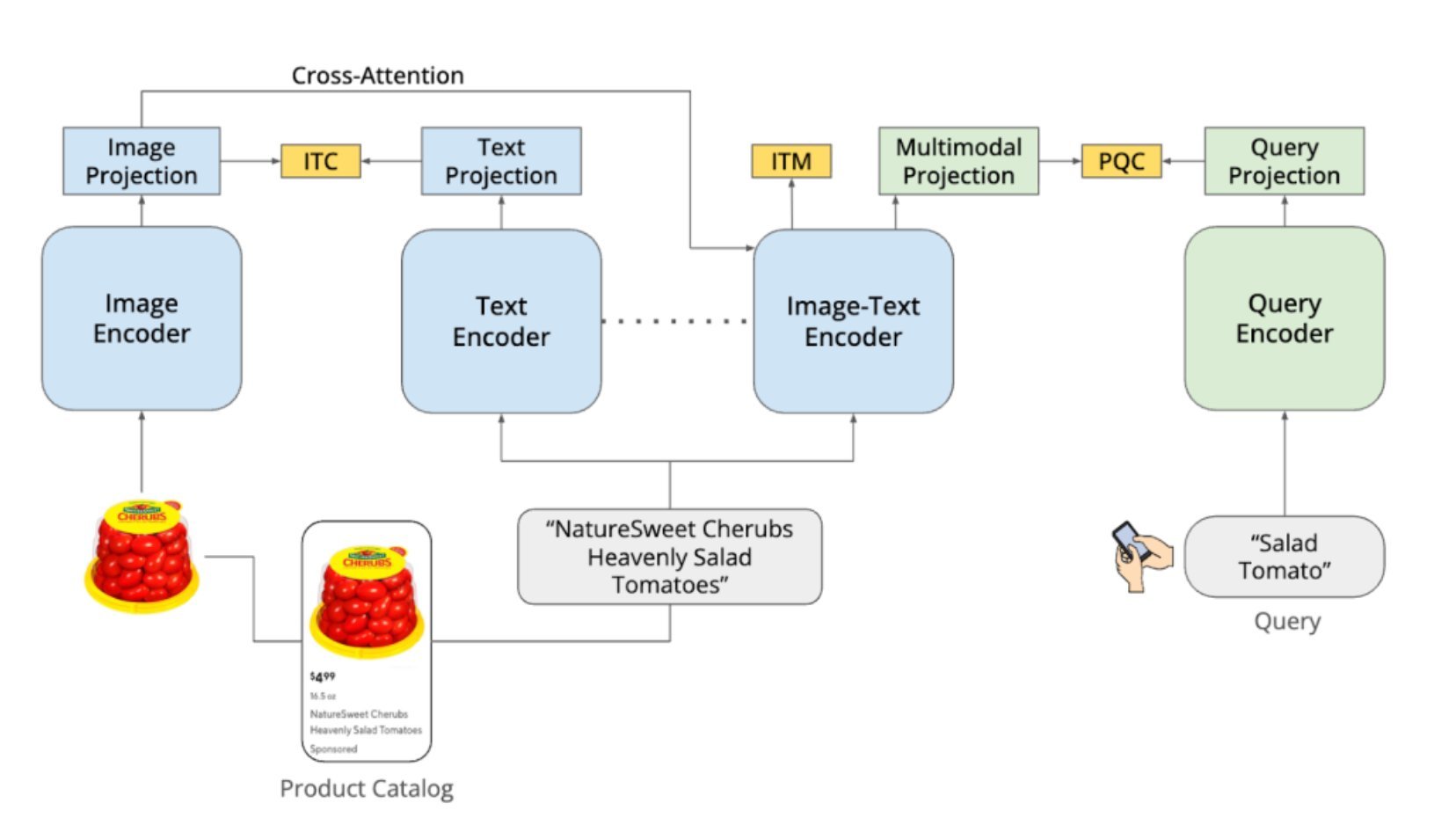
The architecture combines unimodal encoders for images and text, a multimodal encoder integrating both signals, and a query encoder mapping search queries into the same space. This allows the system to match queries with products even when textual descriptions are incomplete or visual attributes are critical.
DoorDash trained DashCLIP using a two-stage pipeline. The first stage performs continual pretraining on roughly 400,000 product images and title pairs from the catalog, adapting pretrained vision language models to the e-commerce domain and learning multimodal product representations. The second stage aligns user queries with product embeddings using a contrastive objective called Query Catalog Contrastive (QCC) loss, bringing relevant query product pairs closer while separating unrelated pairs.
To support this, the team collected 700,000 human-annotated query product pairs and used a GPT-based labeling system to expand the dataset to around 32 million examples. This hybrid approach reduces bias from relying solely on historical engagement.
Once trained, embeddings are integrated into DoorDash's ranking system. Query embeddings retrieve candidate products through K-nearest neighbor search, which are then scored by downstream ranking models that incorporate user behavior, contextual signals, and product popularity, enabling semantically relevant retrieval and ranking.
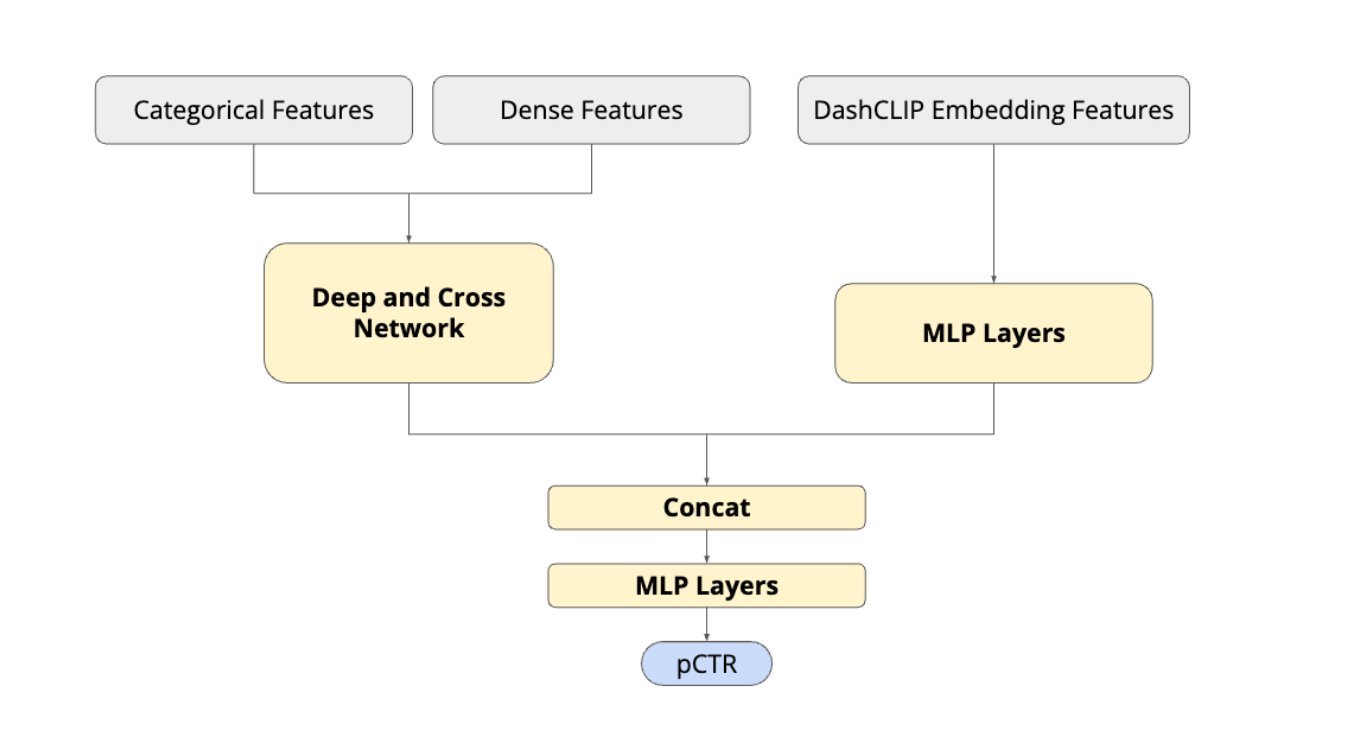
Offline experiments showed that DashCLIP embeddings outperform baseline vision language models such as CLIP, BLIP, and FLAVA in ranking and retrieval tasks. In online A/B experiments, the system improved engagement metrics and was subsequently deployed to serve production traffic for sponsored product recommendations.
Beyond advertising and ranking, DoorDash reports that the embeddings generalize to additional tasks, including aisle category prediction and product query relevance classification, noting that a shared multimodal embedding layer can serve as a foundational representation across multiple machine learning systems within the marketplace platform.
Comments
Please log in or register to join the discussion