
TycoonLE is betting that AI agents need harder planning environments, not louder demos, and it builds one around cargo, capital, routes, debt, and delayed returns.

Tycoon Learning Environment, or TycoonLE, is an open-source JAX environment for testing reinforcement learning agents in a simulated transport economy. The project is not presenting itself as a company with venture funding. No funding amount, investors, or commercial backing are disclosed in the repository materials. Its traction is technical: a public GitHub project, a replay interface, installable Python and npm tooling, PPO training examples, tests, and a companion benchmark report called TycoonBench.
That matters because agent benchmarks are still too often built around short tasks, narrow reward loops, or toy abstractions where the economic consequences of a decision appear almost immediately. TycoonLE takes a different route. Agents allocate capital, build transport routes, move cargo, manage debt, and wait for delayed returns. The pitch is not that this perfectly models logistics markets. It is that economically grounded simulations can expose planning weaknesses that are easy to hide in cleaner benchmark settings.
The problem TycoonLE tries to solve is long-horizon planning under constraints. In many reinforcement learning environments, an agent can act at every timestep from a small fixed menu, receive quick feedback, and learn from dense reward signals. Real operating problems are less forgiving. A capital allocation decision may look wrong for several turns before it becomes profitable. A route may be legal but poorly timed. Borrowing can accelerate expansion or drag down performance. Waiting can be a strategic action rather than a failure to act.
TycoonLE turns those tensions into the core mechanics. The environment gives agents route, finance, and wait candidates, then asks them to choose among valid options. That design is important. Instead of pretending every possible action is always legal, the environment exposes legality through an action mask and a candidate interface. This makes the benchmark closer to the kind of constrained decision-making seen in logistics, resource allocation, and operational planning systems.
The technical positioning is also specific. TycoonLE uses JAX, and its fixed-shape interface is designed to work with transformations such as jit, vmap, and scan. In practical terms, that means researchers can run batched rollouts, compile environment logic, and train agents without fighting variable-shaped observations or unstable action spaces. The quickstart shows the basic flow: create a TycoonLE environment, reset it with a JAX random key, read the action mask, choose a valid action, and step the environment forward.
That sounds small, but fixed-shape design is one of those unglamorous choices that determines whether a research environment is pleasant to use at scale. Dynamic candidate lists may be expressive, but they can become awkward inside accelerated training loops. TycoonLE appears to trade some interface flexibility for compatibility with high-throughput JAX workflows. That is a reasonable bet if the target user is training and comparing policies rather than hand-building a one-off simulator.
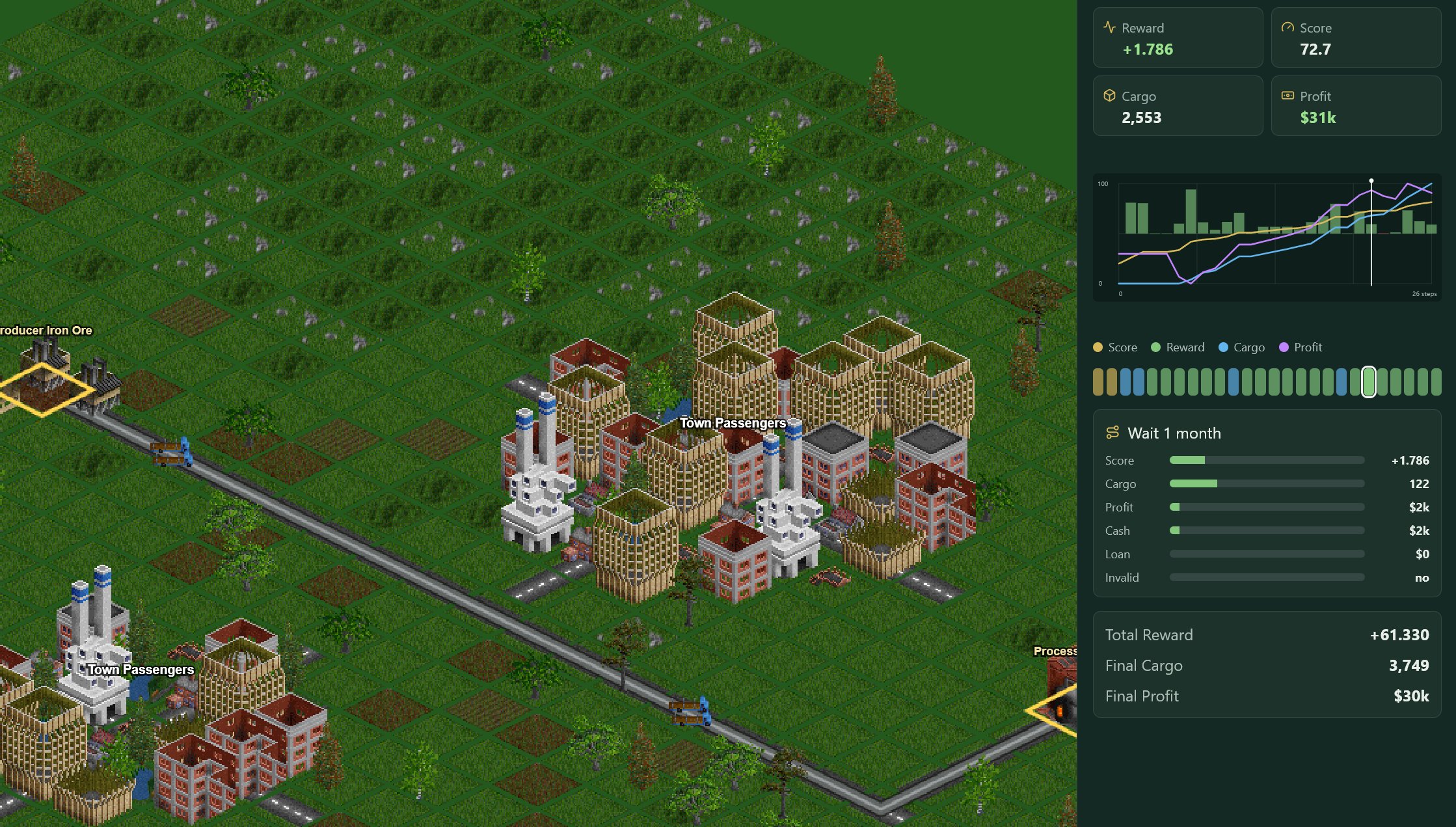
The replay UI is the most useful part of the project from an auditability standpoint. TycoonLE can export replay traces, then visualize route choices, cargo flow, financing behavior, reward, score, and profit over time. This is more than a convenience feature. Long-horizon agents are hard to evaluate from a final score alone because the same score can come from very different behaviors. One policy may build slowly and avoid debt. Another may borrow early, overexpand, and recover late. A third may exploit quirks in the environment. Replay makes those differences inspectable.
For AI agent evaluation, that inspectability is becoming a real market position. Companies and research teams are increasingly asking not only whether an agent can produce an answer, but whether its intermediate decisions are coherent. TycoonLE sits in that gap between synthetic benchmark and operational simulation. It is not a logistics SaaS product. It is not a planning platform for freight operators. It is a research tool for studying how agents behave when actions have delayed financial consequences.
The companion TycoonBench report gives the project a benchmarking angle. Benchmarks can create adoption if they make comparison easy, but they can also create shallow optimization if the community focuses only on leaderboard gains. TycoonLE’s replayable traces help counter that risk because they give evaluators more to inspect than a single aggregate number. The healthier version of this project would be one where benchmark scores, policy traces, legality handling, and financing behavior are all considered together.
The market context is favorable, but not automatic. Reinforcement learning environments for games and control tasks have a long history, from classic arcade suites to robotics simulators. What TycoonLE adds is an economy-flavored planning domain with capital constraints and delayed reward. That places it near a growing category of agent evaluation tools aimed at business-like reasoning, operations research, and multi-step decision quality. The demand is credible because current AI systems often look impressive in isolated tasks and brittle when asked to manage state, constraints, and trade-offs over time.
The skepticism comes from the usual benchmark problem: simulated difficulty is not the same as real-world usefulness. A transport economy can teach useful lessons about planning, but agents that perform well in TycoonLE may still fail when moved into messy enterprise systems with incomplete data, human approvals, shifting objectives, and non-stationary demand. The strongest claim TycoonLE can make is not that it solves logistics planning. It is that it gives researchers a controlled place to study a subset of the problem, especially action legality, financing timing, procedural variation, and delayed returns.
From a funding and traction perspective, TycoonLE looks early. There is no disclosed seed round, no listed investors, and no commercial pricing page. The traction is developer-facing: source code, install steps, tests, a replay workflow, a PPO smoke training script, and citation metadata for academic or research use. That is appropriate for the project’s current shape. If adoption grows, the interesting signals will be external citations, benchmark submissions, forks, issues from researchers trying to train agents, and integrations with broader agent evaluation suites.
The project’s setup also suggests it is meant to be worked with, not merely read about. It supports Python 3.11 or 3.12, editable installation with test dependencies, npm installation for the UI, replay export through an example script, and pytest plus npm run build for validation. The PPO example gives users a minimal path from environment to training loop, which lowers the barrier for researchers who want to test whether their policies can handle the environment before investing in a larger experiment.
There is a broader lesson here for the startup and research ecosystem. Agent infrastructure is moving from prompt demos toward measurable behavior under constraints. That shift creates room for projects that are narrower, more inspectable, and more economically grounded. TycoonLE’s opportunity is to become a useful testbed for that shift. Its risk is that it remains a niche simulator unless enough outside users treat TycoonBench as a serious comparison point.
For now, TycoonLE is best understood as an open-source research venture with no disclosed funding, no named investors, and a clear technical thesis: planning agents should be evaluated on constrained, capital-aware, delayed-reward tasks where their decisions can be replayed and audited. That is a modest claim, but it is a useful one. In a field crowded with broad promises, a focused environment for route planning, cargo flow, and financing behavior may tell us more about agent competence than another polished demo.
Comments
Please log in or register to join the discussion